Linux课题实践三——字符集总结与分析
Posted lllhc
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux课题实践三——字符集总结与分析相关的知识,希望对你有一定的参考价值。
Linux课题实践三——字符集总结与分析
20135318 刘浩晨
字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。字符集是多个字符的集合,字符集种类较多,每个字符集包含的字符个数不同,常见字符集名称:ASCII字符集、GB2312字符集、BIG5字符集、 GB18030字符集、Unicode字符集等。
1.总结ISO、UCS/UTF、GB系列字符集的由来、异同
(1)、ISO/IEC
ISO/IEC 646:是国际标准化组织(ISO)及国际电工委员会(IEC)联合制定的一系列7位字符集的标准来自数个国家标准,最主要来自美国的 ASCII(美国信息互换标准代码)。ISO 646 除了英语字母和数字部分,为所有国家相同外,有些使用字母的国家,可按照实际需要,把ISO 646修改,以定出该国的字符标准。
ISO/IEC 8859:是国际标准化组织(ISO)及国际电工委员会(IEC)联合制定的一系列8位字符集的标准,现时定义了15个字符集。ASCII收录了空格及94个“可印刷字符”,足以给英语使用。但是,其他使用拉丁字母的语言(主要是欧洲国家的语言),都有一定数量的附加符号字母,故可以使用ASCII及控制字符以外的区域来储存及表示。
(2)、UCS/UTF:
Unicode:Unicode(万国码)对世界上大部分的文字系统进行了整理、编码,使得电脑可以用更为简单的方式来呈现和处理文字。Unicode涵盖的数据除了视觉上的字形、编码方法、标准的字符编码外,还包含了字符特性,如大小写字母。
Unicode编码方式:统一码的编码方式与ISO 10646的通用字符集概念相对应。目前实际应用的统一码版本对应于UCS-2,使用16位的编码空间。也就是每个字符占用2个字节。这样理论上一共最多可以表示216(即65536)个字符。
UTF:Unicode的实现方式,也称为Unicode转换格式(Unicode Transformation Format),包括UTF-8、UTF-7、Punycode、CESU-8、SCSU、UTF-32、GB18030等。
UTF-8:是一种针对Unicode的可变长度字符编码,也是一种前缀码。它可以用来表示Unicode标准中的任何字符,且其编码中的第一个字节仍与ASCII兼容,这使得原来处理ASCII字符的软件无须或只须做少部份修改,即可继续使用。
UTF-8使用一至六个字节为每个字符编码:
①128个US-ASCII字符只需一个字节编码(Unicode范围由U+0000至U+007F)。
②带有附加符号的拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文及它拿字母则需要两个字节编码(Unicode范围由U+0080至U+07FF)。
③其他基本多文种平面(BMP)中的字符(这包含了大部分常用字,如大部分的汉字)使用三个字节编码(Unicode范围由U+0800至U+FFFF)。
④其他极少使用的Unicode 辅助平面的字符使用四至六字节编码
UCS:通用字符集(Universal Character Set),是由ISO制定的ISO 10646(或称ISO/IEC 10646)标准所定义的标准字符集。
通用字符集包括了其他所有字符集。它保证了与其他字符集的双向兼容,即,如果你将任何文本字符串翻译到UCS格式,然后再翻译回原编码,你不会丢失任何信息。
UCS包含了已知语言的所有字符。除了拉丁语、希腊语、斯拉夫语、希伯来语、阿拉伯语、亚美尼亚语、格鲁吉亚语,还包括中文、日文、韩文这样的方块文字,UCS还包括大量的图形、印刷、数学、科学符号。
UCS不仅给每个字符分配一个代码,而且赋予了一个正式的名字。表示一个UCS或Unicode值的十六进制数通常在前面加上“U+”,例如“U+0041”代表字符“A”。
(3)、Unicode和ISO 10646的关系:
历史上存在两个独立的尝试创立单一字符集的组织,即国际标准化组织(ISO)于1984年创建的ISO/IEC和由Xerox、Apple等软件制造商于1988年组成的统一码联盟。
1991年前后,两个项目的参与者都认识到,世界不需要两个不兼容的字符集。于是,它们开始合并双方的工作成果,并为创立一个单一编码表而协同工作。从Unicode 2.0开始,Unicode采用了与ISO 10646-1相同的字库和字码;ISO也承诺,ISO 10646将不会替超出U+10FFFF的UCS-4编码赋值,以使得两者保持一致。
(4)、GB:
GB 2312 或 GB 2312-80 :是中华人民共和国国家标准简体中文字符集,全称《信息交换用汉字编码字符集•基本集》,又称GB0,由中国国家标准总局发布,1981年5月1日实施。GB2312编码通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB 2312。
GB 2312标准共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;同时收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个字符。
GB 2312中对所收汉字进行了“分区”处理,每区含有94个汉字/符号。这种表示方式也称为区位码。
GB 2312的区位码:
01-09区为特殊符号。
16-55区为一级汉字,按拼音排序。
56-87区为二级汉字,按部首/笔画排序。
10-15区及88-94区则未有编码。
举例来说,“啊”字是GB2312之中的第一个汉字,它的区位码就是1601。
2.会设置修改系统、应用默认字符集
a、查看服务器字符集
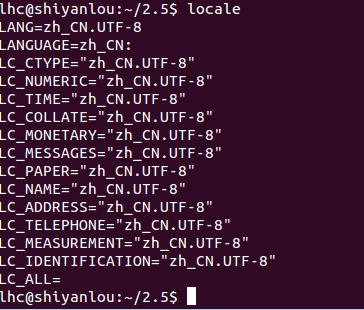
locale命令查看当前服务器字符集:
可见,虚拟机使用的字符集是zh_CN.UTF-8
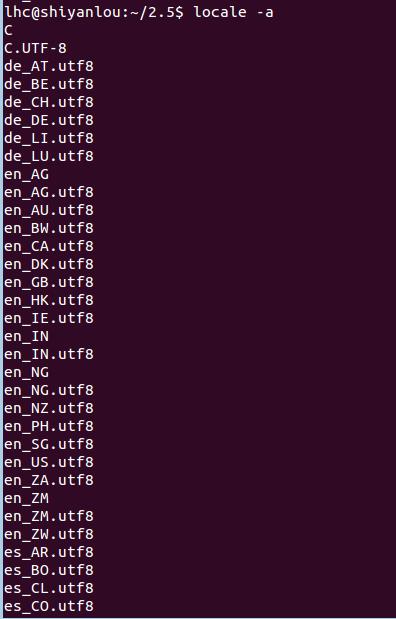
(1) 查看服务器支持的字符集 #locale –a:
(2) 修改字符集类型
LANG=xxx 或者 export LANG=xxx;
注:xxx为欲修改为的字符集,可选择en_US.UTF-8。
取消字符集还可以执行unset LANG这个命令。

(3) 查看某个文件的字符类型

3.同一文件存储为不同字符集,并分析原始数据
(1)Unicode——UTF-8
首先,在Unicode编码表和GB2312编码表中查询“刘浩晨”的编码,查询结果如下:
Unicode编码表:“刘”—“5218”、“浩”—“6d69”、“晨”—“6668”
GB2312编码表:“刘”—“C1F5”、“浩”—“BAC6”、“晨”—“B3BF”

UTF-8文件的前3个byte是:EF BB BF。之后的编码按照大端方式排列,汉字实用的是utf-8格式:E5 88 98 E6 B5 A9 E6 99 A8;而数字20135218(32 30 31 33 35 32 33 38)和字母(6C 68 63)也是ASCII码。
(2)Unicode——ANSI(GB2312——Unicode)
ANSI编码方式实际上就是GB2312编码方式,Windows函数MultiByteToWideChar用于将多字节字符串转换成宽字符串;函数WideCharToMultiByte将宽字符串转换成等价的多字节字符串(Unicode属于宽字节字符集,ANSI属于多字节字符集)。

汉字部分为C1F5 BAC6 B3BF就是“刘浩晨”的gb3212编码,而阿拉伯数字20135218(32 30 31 33 35 32 33 38)和英文字母lhc(6C 68 63)都是用ASCII编码表示,大端方式编码。0D 0A表示回车换行。
(3)Unicode——Unicode big endian
这两种编码方式其实没有本质区别,Unicode是以 “FF FE” 开头, 每一个字符占2个字节, 低8位为字符二进制编码, 高8位为0,汉字也占2个字节;而Unicode big endian以“FE FF”开头, 每一个字符占2个字节,与Unicode顺序相反, 低8位为字符二进制编码, 高8位为0 ;汉字也占2个字节。总而言之,就是它们的开头数据不同,另外,Unicode采用的是小端方式(存储与读取顺序相反),Unicode big endian采用的是大端方式(存储与读取顺序相同),所以二者之间只是变一下位置而已,很容易进行转化。
Unicode big endian:

Unicode:

以上是关于Linux课题实践三——字符集总结与分析的主要内容,如果未能解决你的问题,请参考以下文章