一个类似 Twitter 雪花算法 的 连续序号 ID 产生器 SeqIDGenerator
Posted 凯特琳
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一个类似 Twitter 雪花算法 的 连续序号 ID 产生器 SeqIDGenerator相关的知识,希望对你有一定的参考价值。
项目地址 : https://github.com/kelin-xycs/SeqIDGenerator
今天 QQ 群 里有网友问起产生唯一 ID 的方法 有哪些, 讨论了各种方法 。
有网友提到 Twitter 的 雪花算法 : https://blog.csdn.net/w200221626/article/details/52064976
我觉得 GUID 的 优点 是 简单 高效, 缺点 是 可读性 比较差 。
高效 是指 相比起 要到 数据库 读取 种子(当前最大序号) 等的方式, 同时 也 简单, 不会出什么问题 。
如果 对 可读性 有要求, 比如 要 显示给 用户 看, 或者 便于 维护, 可以使用 针对业务 产生的 连续序号 ID , 比如 订单号 。
如果 对 可读性 没什么要求, 那么 用 GUID 就行 。 或者说, 对 可读性 没太多要求 的 场合 可以 通用 GUID 。
但很多时候 我们 也希望使用 可读性好的 连续序号 ID , 所以就想有一个 简单的 通用的 产生 连续序号 ID 的 方法 。
所以, 就想出了一个 和 Twitter 雪花算法 类似 的 算法 :
这种算法 产生的 ID 格式如下 :
时间戳-机器ID-序号
时间戳 就是 “20181106213913983” 这样, 表示 2018年11月06日21点39分13秒983毫秒 , 时间戳 取到 毫秒 。
机器ID 就是 计算机 ID, 或者说 服务器 ID, 因为现在 高并发 负载均衡 集群 很常见, 所以需要考虑 多台 Server 并行作业 时 的 情况 。 并行作业 的 Server 之间的 连续序号 ID 不能重复, 对此, Twitter 雪花算法 是 通过 给 每个 Server 一个 机器ID 来区分 , 所以 我们 也学 Twitter 雪花算法 这样 。
机器ID 在 App.config 中 配置 :
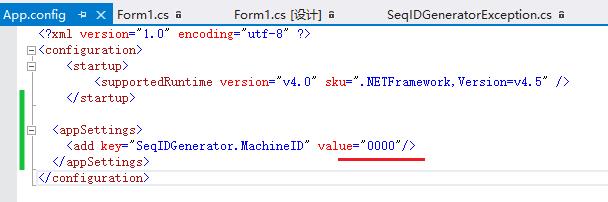
机器ID 可以 自己随便配置, 不过考虑到 连续序号 ID 的 排序 查询 等, 取成 固定位数 的 数字 比较好 , 比如 上图 中的 “0000”,
4 位 数字 可以支持 1 万 台 Server (0000 ~ 9999) 。
序号 是指 这台计算机上 当前这一毫秒 内 连续序号 ID 的 序号, 这一毫秒内 第一个 连续序号 ID 的 序号 是 0, 第二个是 1, 第三个是 2, 第四个是 3 …… , 以此类推 。 到下一毫秒 序号 会重置为 从 0 重新开始 。
现在程序中写死的 序号 格式 是 4 位 数字, 4 位 数字 可以支持在 一台计算机(多核)上 每毫秒 产生 1 万 个 ID (0000 ~ 9999) 。
效果如下 : (运行 解决方案 中的 Demo 项目 就可看到)
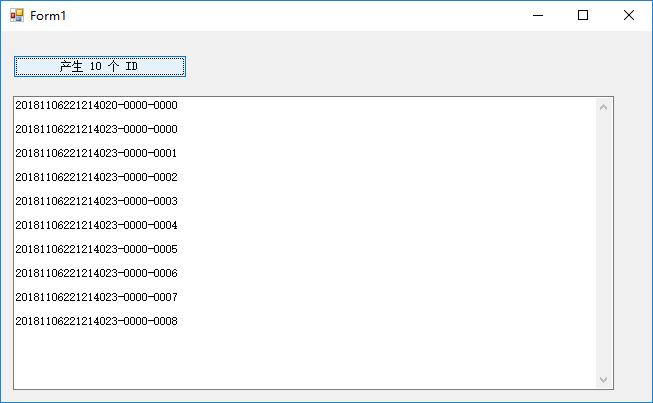
以上是关于一个类似 Twitter 雪花算法 的 连续序号 ID 产生器 SeqIDGenerator的主要内容,如果未能解决你的问题,请参考以下文章
雪花算法Twitter的分布式自增ID算法snowflake (Java版)