OpenJDK1.8.0 源码解析————HashMap的实现
Posted 小土豆的博客世界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OpenJDK1.8.0 源码解析————HashMap的实现相关的知识,希望对你有一定的参考价值。
HashMap是Java Collection Framework 的重要成员之一。HashMap是基于哈希表的 Map 接口的实现,此实现提供所有可选的映射操作,映射是以键值对的形式映射:key-value。key——此映射所维护的键的类型,value——映射值的类型,并且允许使用 null 键和 null 值。而且HashMap不保证映射的顺序。
简单的介绍一下HashMap,就开始HashMap的源码分析。
首先简单的介绍一下HashMap里都包含的数据结构。觉得还是先贴一张图比较好,结合图文会比较好理解一些。
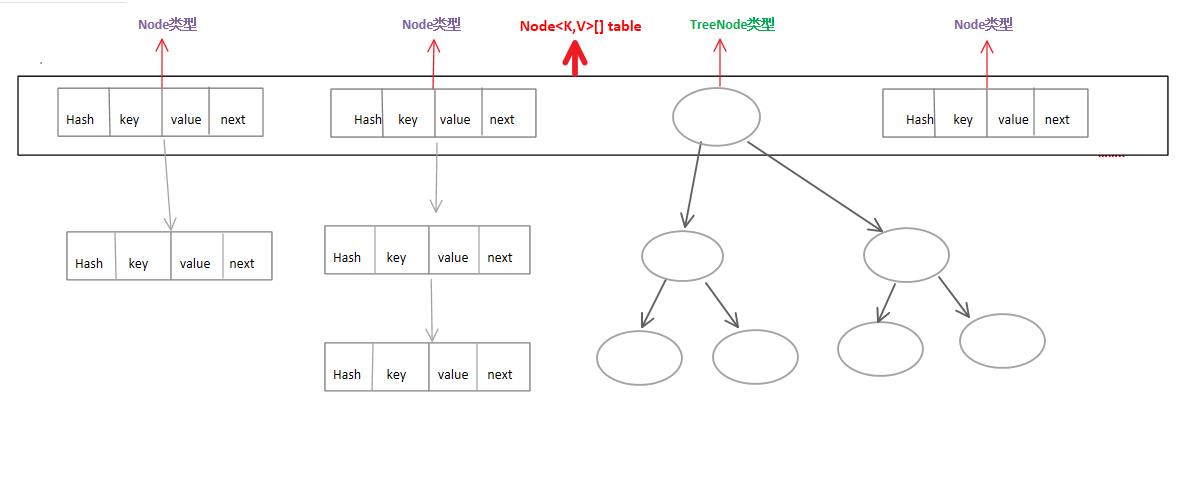
现在就可以开说一下这三种数据结构。
第一个就是Node<K,V>类型的节点。
备注:static class HashMap.Node<K,V> implements Map.Entry<K,V>
第二个就是由Node<K,V>类型组成的一个Node<K,V>[] table数组。
第三个就是一个TreeNode<K,V>类型的红黑树。
备注:static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V>
static class LinkedHashMap.Entry<K,V> extends HashMap.Node<K,V>
static class HashMap.Node<K,V> implements Map.Entry<K,V>
现在结合代码看一看这三种数据结构(其实Node和Node[] 是同一类,所以就是两种)。
第一种:Node<K,V>
看这个之前先看看它实现的父类接口Map.Entry<K,V>的源码(Entry是Map接口里的一个内部接口)
interface Entry<K,V> { K getKey(); V getValue(); V setValue(V value); boolean equals(Object o); int hashCode(); }
再看Node的源码(Node是HashMap类的一个静态内部类,实现了Map接口里的内部接口Entry)
static class Node<K,V> implements Map.Entry<K,V> { //这四个成员变量就是一个Node节点所包含的四个变量域 //其中hash的计算方法是由一个hash方法得到的,该方法的是实现就是HashMap里,这里为了看的清楚一些,就写到下面: // hash = (h = key.hashCode()) ^ (h >>> 16); final int hash; final K key; V value; Node<K,V> next;
//构造方法 Node(int hash, K key, V value, Node<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; }
//拿到该Node 的key public final K getKey() { return key; }
//拿到该Node 的value public final V getValue() { return value; }
//重写toString方法 public final String toString() { return key + "=" + value; }
//修改当前Entry对象的value为传进入newvalue,返回值为之前的oldvalue值
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
/*
判断两个Entry是否相等
若两个Entry的“key”和“value”都相等,则返回true;否则返回false
*/
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) && Objects.equals(value, e.getValue()))
return true;
}
return false;
}
//重写了equals,因此重新实现hashCode()
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
}
第二种:TreeNode(这里只附上TreeNode类的成员变量和一个获取树根的方法,其他的省略。因为TreeNode里实现了很多关于红黑树的操作方法,如果全部放到这里不仅看不懂而且显得特别乱)
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> { TreeNode<K,V> parent; TreeNode<K,V> left; TreeNode<K,V> right; TreeNode<K,V> prev; //构造函数 TreeNode(int hash, K key, V val, Node<K,V> next){
super(hash, key, val, next); } //返回该树的树根 final TreeNode<K,V> root() { for (TreeNode<K,V> r = this, p;;){ if ((p = r.parent) == null) return r; r = p;
} } //其余部分省略,有兴趣的可以自行查看源代码。 }
然后在说一下TreeNode构造函数所做的事情。
先了解一下TreeNode的继承体系:TreeNode继承了LinkedHashMap.Entry
LinkedHashMap.Entry继承了HashMap.Node
HashMap.Node实现了Map.Entry
了解这个就能清楚的知道TreeNode的构造函数到底做了什么事情。底下的图显示了TreeNode利用构造初始化的流程。
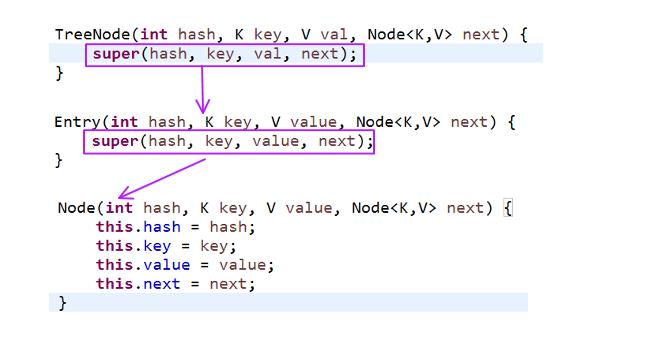
其实最终还是调到了Node的构造,初始化TreeNode了从Node继承而来的四个数据域(int hash,K key,V value,Node<K,V> next)。
接着我们说一下HashMap里几个重要的成员变量和常量(省略了一部分)。
//通过HahMap实现的接口可知,其支持所有映射操作,能被克隆,支持序列化 public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable { private static final long serialVersionUID = 362498820763181265L; //默认Node<K,V> table的初始容量16,2的4次方。 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; //table数组的最大容量为1073 741 824,2的30次方。 static final int MAXIMUM_CAPACITY = 1 << 30; /* 默认加载因子 该值和table的长度的乘积为是否对table进行扩容的标志。 例如当该值默认为0.75,table的长度为16时,就是说当table填充至 12*0.75 =12 之后,这个table就要进行扩容 */ static final float DEFAULT_LOAD_FACTOR = 0.75f; //哈希表的定义,这个数据结构在前面已经介绍过 transient Node<K,V>[] table; /* HashMap的大小,即保存的键值对的数量 当该值大于等于HashMap的阈值时,数组就会扩充 */ transient int size; /* HashMap的阈值. 用于判断是否需要调整HashMap的容量 该值的计算方法为: 加载因子 * (table.length) 当table.size>=threshold就会扩容,就是如果hashMap中存放的键值对大于这个阈值,就进行扩容 如果加载因子没有被分配,默认为0.75 如果table数组没有被分配,默认为初始容量值(16); 或若threshold值为0,也表明该值为初始容量值。 */ int threshold;
/* 加载因子 如果加载因子没有被分配,默认为0.75 */ final float loadFactor;
//当添加到tab[i]位置下的链表长度达到8时将链表转换为红黑树 static final int TREEIFY_THRESHOLD = 8; ...... }
介绍完数据结构再来说一下我们平时经常写的代码:Map<String,Object> map = new HashMap<String,Object>()
(这样的方式获得的map对象,调用的是默认无参的构造,实际上还有其他三个有参的构造函数)
要知道写完这句代码之后到底发生了什么。我们首先就得看一下HashMap构造器(共4个构造器),源码如下
/*
默认无参构
构造一个具有默认初始容量 (16) 和默认加载因子 (0.75) 的空 HashMap。
*/ public HashMap() { this.loadFactor = DEFAULT_LOAD_FACTOR; } //构造一个带指定初始容量和加载因子的空 HashMap。 public HashMap(int initialCapacity, float loadFactor) { //初始容量为负数,抛出异常。 if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
//初始容量大于最大容量,把初始容量定为最大容量。 if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY;
//如果加载因子不符合规范,抛出异常 if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " +loadFactor);
//经过一些过滤和处理,现在的loadFactor和initialCapacity都为合法的值 //初始化加载因子 this.loadFactor = loadFactor;
/* 初始化HashMap的阈值 调用tableSizeFor(initialCapacity)方法 该方法根据数组的初始容量的大小求出HashMapde的阈值threshold
*/ this.threshold = tableSizeFor(initialCapacity); } /* 第三个构造方法 构造一个带指定初始容量和默认加载因子 (0.75) 的空 HashMap。 */ public HashMap(int initialCapacity) { this(initialCapacity, DEFAULT_LOAD_FACTOR); } // 构造一个映射关系与指定 Map 相同的新 HashMap。 public HashMap(Map<? extends K, ? extends V> m) { this.loadFactor = DEFAULT_LOAD_FACTOR; putMapEntries(m, false); }
上面提到了根据数组初始容量得出HashMap阈值的一个方法:tableSizeFor(int cap)。该方法的源码如下:
static final int tableSizeFor(int cap) { int n = cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; }
简单的测试了一下这个方法
public class TestHashMap{
static final int MAXIMUM_CAPACITY = 1 << 30;
public static void main(String[] args){ System.out.println("---------------------"); System.out.println(" 第一次测试,cap = 0,返回的阈值threshold = "+tableSizeFor(0)); System.out.println("---------------------"); System.out.println(" 第二次测试,cap = 3,返回的阈值threshold = "+tableSizeFor(3)); System.out.println("---------------------"); System.out.println(" 第三次测试,cap = 16,返回的阈值threshold = "+tableSizeFor(16)); System.out.println("---------------------"); System.out.println(" 第四次测试,cap = 100,返回的阈值threshold = "+tableSizeFor(100)); System.out.println("---------------------"); System.out.println(" 第五次测试,cap = 1000,返回的阈值threshold = "+tableSizeFor(1000)); System.out.println("---------------------"); System.out.println(" 第六次测试,cap = 10000,返回的阈值threshold = "+tableSizeFor(10000)); System.out.println("---------------------"); } static final int tableSizeFor(int cap) { int n = cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; } }
输出结果:
---------------------
第一次测试,cap = 0,返回的阈值threshold = 1
--------------------
第二次测试,cap = 3,返回的阈值threshold = 4
---------------------
第三次测试,cap = 16,返回的阈值threshold = 16
---------------------
第四次测试,cap = 100,返回的阈值threshold = 128
---------------------
第五次测试,cap = 1000,返回的阈值threshold = 1024
---------------------
第六次测试,cap = 10000,返回的阈值threshold = 16384
---------------------
总之,tableSizeFor方法是根据table数组的容量计算出hashMap可以维护出的键值对。从结果可以看到阈值至少是1,而且是刚好比cap大一点的2的幂。
至于为什么阈值要做成这样,看了很多文章,都是说为了使hashMap散列均匀。但是实际上tab[i]中i的选择是 hash & lenth-1 是和容量在做按位或。
因此对这里有一些疑惑。
到此对HashMap一部分介绍完了。哪里有不对的地方,还望指出。还有就是如果能解答我的疑惑,还请指导,十分感谢 ^_^。
以上是关于OpenJDK1.8.0 源码解析————HashMap的实现的主要内容,如果未能解决你的问题,请参考以下文章