day_4:内置函数
Posted lcj122
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了day_4:内置函数相关的知识,希望对你有一定的参考价值。
一:内置函数
常用内置函数如下:

1)abs:取一个数字的绝对值
#abs:取绝对值
n = abs(-10)
print(n)
2)any和all
值为Fslse有:0,None,""->空的字符串,[]空列表,()空元祖
any:只有字为真即为真
all:值所有为真即为真
3)ascii() 自动执行对象的_repr_方法 (了解)


1 #ascii() 自动执行对象的_repr_方法
2 class foo:
3 def __repr__(self):
4 return "123"
5 n = ascii(foo())
6 print(n)
1 #all()
2 #any()
3 #什么值为Fasle值:0,None,"空字符串","空的元祖","空的字典","空的列表"
4 print(bool(0)) #“0”输出值为Fasle
5 print(bool("")) #空字符串输出值为Fasle
6 print(bool([])) #“空列表”输出值为Fasle
7 print(bool()) #“空元祖”输出值为Fasle
8 print(bool({})) #“空字典”输出值为Fasle
1 #all() :所有为真才为真
2 n = all([1,2,3,4,5,])
3 print(n)
4 # any():任何一个为真,即为真
5 n2 = any((0,2,3,4,[],(),-1))
6 print(n2)
4)bin,oct,hex
#接收一个十进制,并把十进制转换至二进制[0b101:其中0b-->表示一个特殊函数,即表示是二进制]
# bin()
print(bin(5))
#接收一个十进制,并把十进制转换为八进制【0o5:其中0o-->是表示八进制】
# oct()
print(oct(5))
#接收一个十进制,并把十进制转化为一个十六进制【0x5:0x-->表示为十六进制】
# hex()
print(hex(5))
5)bytes:将字符串转换为字节类型
utf-8编写:一个汉子占三个字节,一个字节是8位
#b\'\\xe7\\xbd\\x97\\xe6\\x89\\xbf\\xe7\\x94\\xb2\'
GBK编码:一个汉子占两个字节
#b\'\\xc2\\xde\\xb3\\xd0\\xbc\\xd7\'
1 #一个汉子转换为一个字节
2 #字符串转换为字节类型
3 #bytes(需要转换的字符串,按照什么编码格式)
4 s = "北京欢迎你"
5 n = bytes(s,encoding="utf-8") #将“北京欢迎你”字符串转换为utf-8字节类型
6 print(n)
7 n = bytes(s,encoding="GBK") #将“北京欢迎你”字符串转换为GBK字节类型
8 print(n)
6)str:字节转换至字符串
#字符串用什么编译成字节的,需要用同样的编码编回
s = str(bytes("北京欢迎你",encoding="utf-8"),encoding="utf-8")
print(s)
7)open:文件操作
打开方式:文件句柄 = open("文件路径",‘打开模式’)
文件打开模式有:
- r ,只读模式【默认】
- w,只写模式【不可读;不存在则创建;存在则清空内容;】
- x, 只写模式【不可读;不存在则创建,存在则报错】
- a, 追加模式【可读; 不存在则创建;存在则只追加内容;】
"+" 表示可以同时读写某个文件
- r+, 读写【可读,可写】:可指定位置,但是会覆盖原有的位子
- w+,写读【可读,可写】:先清空
- x+ ,写读【可读,可写】
- a+, 写读【可读,可写】:每次写在最后,不能放在指定的位置
"b"表示以字节的方式操作
- rb 或 r+b
- wb 或 w+b
- xb 或 w+b
- ab 或 a+b
注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型
#tell:获取当前指针的位置(字节)
#seek :主动把指针调到某一个位置,永远按照(字节)方式找位置,即使有中文一样,屏蔽中文
1 #seek主动把指针调到某一个位置,永远按照字节方式找位置,即使有中文一样,屏蔽中文
2 f = open("db",\'r+\', encoding="utf-8")
3 #如果打开模式无b,则read,按照字符读取
4 date = f.read(1)
5 #tell:获取当前指针的位置(字节)
6 print(f.tell())
7 #调整当前指针位置(字节)
8 f.seek(f.tell())
9 #当前指针位置开始向后覆盖
10 f.write("999")
11 f.close()
操作文件:
read() :无参数时,读取文件中全部文件
:有参数时,带“b”:表示读取方式按照“字节”读取
:有参数时。不带“b”:表示读取方式按照“字符”方式读取
write():写数据,打开方式中含有“b”:则按照“字节”方式写,否则无“b”,按照“字符”方式写文件
fileno():文件描述符
flush():强刷,把写的数据强刷值内存中
1 f = open("db",\'a\',encoding="utf-8") #参数a:追加模式【可读; 不存在则创建;存在则只追加内容;】
2 f.write("3456") #在db文件中写入3456
3 f.flush() #将数字3456强制写入内存
4 input("dsddsds")
reabable:判断文件是否可读
f = open("db",\'w\',encoding="utf-8") #w:表示只写模式,不可读
print(f.readable()) #readable判断文件是否可读
readline:表示每次仅读取一行
truncate:截断数据,即指针后的数据清空,只截取指针前面的数据
f = open("db",\'r+\',encoding="utf-8") #r+:可读可写文件
f.seek(2) #把指针一至问价第一行的第二元素,
f.truncate()#把指针后面的数据清空,只是截取指针前面的数据
f.close() #关闭文件
for循环文件对象:f = open("db",\'r+\')
for line in f:
print(line) #一行行读取文件
关闭文件
关闭文件方式一:
f = open("db",\'r+\',encoding="utf-8") #r+:可读可写文件
f.seek(2) #把指针一至问价第一行的第二元素,
f.truncate()#把指针后面的数据清空,只是截取指针前面的数据
f.close() #关闭文件
关闭文件方式二:
#with open("hh.txt",\'r\',encoding="utf-8") as f #打开文件hh.txt并赋值给变量f
2.6不支持同时打开两个或者多个文件操作,3.0则支持同时打开多个文件
#with open(\'db\')as f
# pass
3.0 则支持同时打开多个文件
with open(\'db\')as f,open(\'db2\')as f:
同时打开两个文件,把一个文件读的数据写入另外一个文件
with open("ha",\'r\',encoding="utf-8")as f1,open("db",\'w\',encoding="utf-8")as f2:
1 with open("ha",\'r\',encoding="utf-8")as f1,open("db",\'w\',encoding="utf-8")as f2:
2 time=0 #计数
3 for line in f1: #读取f1文件每一行
4 time +=1 #没读取一行自增加一
5 if time<=10: #当读取f1文件的第10行时,把数据写入f2中
6 f2.write(line)
7 else: #否则读取超过10行的数据,break退出循环
8 break
callable :表示是否可以被执行
def f1(): pass f1() f2=123 print(callable(f1)) #表示可执行“TRUE” print(callable(f2)) #表示不可被执行“FALSE”
chr,ord 函数
#chr:将asscill码中的数字转换至字母
r = chr(65)
print(r)
#ord:将asscill码中的字母转换至数字
r2 =ord("B")
print(r2)
random模块:
#import random #需要导入random模块
#i = random.randrange(65,91) #表示在一个范围内随机生成一组数字或者字母
例如:6为数字加字母的验证码
1 import random
2 li= [] #将新生成的数据放至列表中
3 for i in range(6): #一共循环6次
4 r = random.randrange(0,5) #循环范围在0-5之间,当循环数字为2或者为4时,就把打印(0-9)数字赋值给num
5 if r == 2 or r == 4:
6 num = random.randrange(0,10)
7 li.append(str(num)) #输出是列表的类型需要统一,0-9为数字,65-91是将数据转换至字母
8 else:
9 temp = random.randrange(65,91)#accill中65-91相对应的数字母
10 c=chr(temp)
11 li.append(c) #将生成数据赋值给li列表
12 s = "".join(li) #join把生成的字母拼接
13 print(s)
compile、eval、exec函数
compile:将字符串编译成python代码(用于python模板引擎)
eval:执行python代码或字符串,并获取返回值
#eval函数:表示将python字符串转换成一个算数表达式并返回结果 r = \'9*6-8\' print( eval(r)) #46
exec:只能执行表达式,且无返回值(None)
#exec函数:只执行表达式,无返回值(None) r = \'9*6-8\' print(exec(r)) #None
single:把字符串编译成单行的python程序,
1 s = "print(123)"
2 #python内部执行流程先编译
3 # single-->把字符串编译成单行的python程序,
4 # eval--》将字符串编译成一个“一个表达式,
5 # exec--》将编译成的代码弄成跟python一样的编码格式的代码
6 #compile将字符串编译成python代码
7 r = compile(s,"<string>","exec")#string表示要把一个字符串编译成一个python代码
8 #执行python代码或字符串,且无返回值
9 exec(r)
10 #eval 只能执行表达式,并获取有返回值
11 s = "9*9"
12 ret=eval(s)
13 print(ret)
dir:快速获取某一个类、列表、字典、某块或者对象提供哪些功能
#print(dir(dict)) #查看字典提供哪些功能
[\'__class__\', \'__contains__\', \'__delattr__\', \'__delitem__\', \'__dir__\', \'__doc__\', \'__eq__\', \'__format__\', \'__ge__\', \'__getattribute__\', \'__getitem__\', \'__gt__\', \'__hash__\', \'__init__\', \'__iter__\', \'__le__\', \'__len__\', \'__lt__\', \'__ne__\', \'__new__\', \'__reduce__\', \'__reduce_ex__\', \'__repr__\', \'__setattr__\', \'__setitem__\', \'__sizeof__\', \'__str__\', \'__subclasshook__\', \'clear\', \'copy\', \'fromkeys\', \'get\', \'items\', \'keys\', \'pop\', \'popitem\', \'setdefault\', \'update\', \'values\']
divmod:计算分页
r = divmod(100,3)
print(r[0]) #0表示商的整数
print(r[1]) #1表示商的余数
n1,n2 =divmod(100,2)
print(n1,n2) #n1表示商的整数,n2表示商的余数
对象和类的关系
1)、对象是类的实例
2)、字典是dict实例,列表是list实例,元祖是tulp是实例
isinstance:判断对象是否是某个类的实例
s=[22,34,4,56,] r=isinstance(s,list) print(r) #True
filter:筛选数字
格式为filter(函数,可迭代对象(字典,列表))
#filter筛选数字,格式为filter(函数,可迭代对象(字典,列表))
def f2(a):
if a> 22: #列表的第一个元素开始于22比大小,如TRUE则把数据赋值给ret,否则抛弃数字
return True
li = [11,22,3,34,55,77,]
ret = filter(f2,li) #把列表li作为参数传给F2,
print(list(ret))
View Code
filter与lambda结合使用
#lambda表达式:自动返回return,如条件成立返回TRUE,否则返回FALSE li = [22,33,44,556,6,77,88,] result = filter(lambda a:a>22,li) #将lamdba函数与li列表中的每一个数字对比大小,大于列表的数字即返回TRUE,否则返回FASLE print(list(result)) #将返回结果转换至列表形式
map函数和lamdba函数使用
格式:#map(函数,可迭代的对象(可以for循环的东西)
def f1(a): return a+100 li = [22,33,4,5,6] ret = map(f1,li) #将列表中的每一个元素加100,并把结果返回给ret print(list(ret))#将返回数字转换至列表形式 def f2(a): return a+100 li = [22,33,55,7,78,97,] ret = map(lambda a:a+100,li)#将列表中的每一个数字同过lamdba加100,并把结果返回给ret print(list(ret)) #将返回数字转换至列表形式
globals:所有全局变量
locals:所有的局部变量
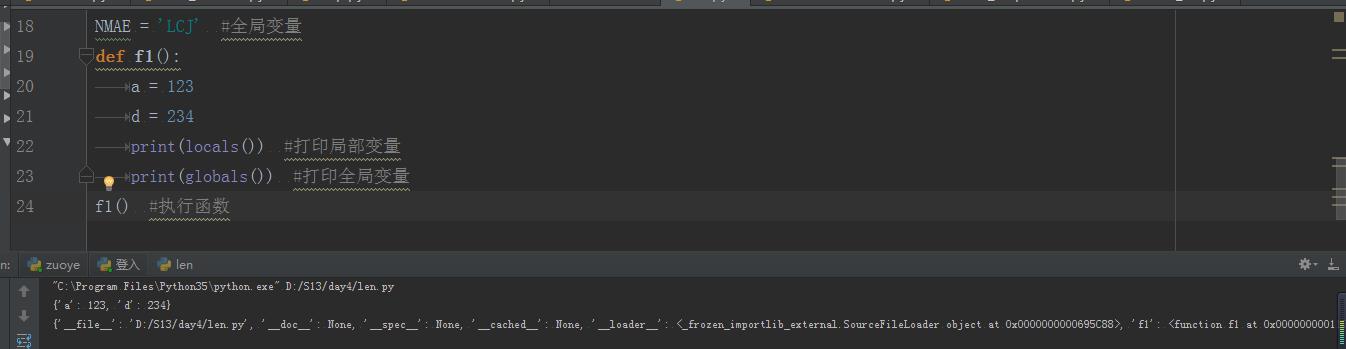
hash:将对象转换一个hash值,一般用于字典的key保存
heple:查看帮助
len:查看字节长度
# s = "李杰" # print(len (s),type(s)) # # s="李杰" # b= bytes(s,encoding=\'utf-8\') #将字符转换为字节查看 # print(len(b)) # # #2.7 for“李杰” # #3.0 for "李杰"
例子:len:取字符串长度
r = \'1234567890\' print(len(r)) #10
关于嵌套while知识扩展:
在嵌套的while循环中,break只是结束当前循环,并未结束整个循环语句
flag = True #将True赋值给flag while flag: #当条件为真执行下面while循环 while True: #如果第二个while语句为真,则返回bbb,否则退出本次循环 print(\'bbb\') flag = False #条件不成立,执行break,并执行第一个while语句,返回aaa break print(\'aaa\') # bbb # aaa
以上是关于day_4:内置函数的主要内容,如果未能解决你的问题,请参考以下文章