字符集实践
Posted 不是富东京
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了字符集实践相关的知识,希望对你有一定的参考价值。
字符集实践报告
20135311傅冬菁
字符集由来及区别:
ASCII码,它以8bit字节为单位存储,ASCII的0-31及127为控制符,32-126为可见字符,包括所有的英文字母,阿拉伯数字和其他一些常见符号,128-255的ASCII码则没有定义。
ASCII对英语国家是够用了,但对其他西欧国家却不够用,因此,人们将ASCII扩展到0-255的范围,形成了ISO-8859-1字符集。
东方的文字(如中文)的字符数要大得多,根本不可能在一个字节内将它们表示出来,因此,它们以两个字节为单位存储,以中文国标字符集GB2312为例,它的第一个字节为128-255。系统可以据此判断,若第一个字节大于127,则把与该字节后紧接着的一个字节结合起来共两个字节组成一个中文字符。这种由多个字节存储一个字符的字符集叫多字节字符集(MultiByte Charsets),对应的象ASCII这种用一个字节存储一个字符的字符集叫单字节字符集(SingleByte Charsets)。在GB2312字符集中,ASCII字符仍然用一个字节存储,换句话说该ASCII是该字符集的子集。
GB2312只包含数千个常用汉字,往往不能满足实际需要,因此,人们对它进行扩展,这就有了我们现在广泛使用的GBK字符集,GBK是现阶段Windows及其他一些中文操作系统的缺省字符集。它包含2万多个字符,除了保持和GB2312兼容外,还包含繁体中文字,日文字符和朝鲜字符。值得注意的是GBK只是一个规范而不是国家标准,新的国家标准是GB18030-2000,它是比GBK包含字符更多的字符集。
国际标准ISO10646定义的通用字符集(Universal Character Set即UCS)的出现,使这种局面发生了彻底的改观。UCS 是所有其他字符集标准的一个超集. 它保证与其他字符集是双向兼容的. 就是说, 如果你将任何文本字符串翻译到 UCS格式, 然后再翻译回原编码, 你不会丢失任何信息。
修改默认字符集:
使用命令locale -a|grep zh_CN查看当前拥有的中文字符集,如果没有gb2312,则使用命令sudo locale-gen zh_CN安装字符集,之后在当前文件夹下使用命令: vim ~/.vimrc设置Vim RunTime Environment,将下面内容输入进该文件:
set fileencodings=utf-8,ucs-bom,gb18030,gbk,gb2312,cp936
set termencoding=utf-8
set encoding=utf-8
用多种字符集进行编写文件:
一、用ASCII码字符集:
首先,在ASCII码表中找到自己所要写的内容所对应的十六进制编码;我所想输入的内容是“I’ am FDJ”,所对应的十六进制数是4927616d46444a;
接下来,用vi打开我所想输入的文件。输入::%!xxd 转到十六进制文本模式。使用i对文本进行编辑,输入4927616d46444a即可。退出编辑模式,输入::%!xxd –r返回,这事显示了自己所要看到的内容“I’ am FDJ”,并保存。

使用cat指令查看文本内容:

二、使用GB2312字符集
同样是找到自己所要输入内容的GB2312码,我所想输入的内容是“傅冬菁不是富东京”,查找到对应的编码为b5b8 b6ac ddbc b2bb cac7 b8bb b6ab bea9;
首先将终端的编码方式改为GB2312;修改后使用命令locale –a|grep zh_CN查看是否有GB2312字符集。没有的话,就是用报告的第二部分内容进行修改。
使用vi 命令进入文本文件,同样输入::%!xxd 进入十六进制文本模式。将自己的编码输入文本中,以::%!xxd –r退出,之后保存。

使用cat指令查看:
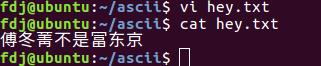
三、使用UTF -8字符集
同样,先查找出我想输入内容的编码表示。我想输入的内容为“不是富东京”。用UTF-8编码表示为:e4b8b0 e698af e5afbc e4b89c e4babc;参照前面两个例子,将内容输出;



以上是关于字符集实践的主要内容,如果未能解决你的问题,请参考以下文章