Linux内核分析——ELF文件格式分析
Posted 20135223何伟钦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux内核分析——ELF文件格式分析相关的知识,希望对你有一定的参考价值。
ELF文件(目标文件)格式主要三种:
1)可重定向文件:文件保存着代码和适当的数据,用来和其他的目标文件一起来创建一个可执行文件或者是一个共享目标文件。(目标文件或者静态库文件,即linux通常后缀为.a和.o的文件)
2)可执行文件:文件保存着一个用来执行的程序。(例如bash,gcc等)
3)共享目标文件:共享库。文件保存着代码和合适的数据,用来被下连接编辑器和动态链接器链接。(linux下后缀为.so的文件。)
一般的 ELF 文件包括三个索引表:
1)ELF header:在文件的开始,保存了路线图,描述了该文件的组织情况。
2)Program header table:告诉系统如何创建进程映像。用来构造进程映像的目标文件必须具有程序头部表,可重定位文件不需要这个表。
3)Section header table :包含了描述文件节区的信息,每个节区在表中都有一项,每一项给出诸如节区名称、节区大小这类信息。用于链接的目标文件必须包含节区头部表,其他目标文件可以有,也可以没有这个表。
1、 分析ELF文件头(ELF header)
进入终端输入:cd /usr/include/elf.h,查看ELF的文件头包含整个文件的控制结构

顺便选取一个简单代码为例:

进行编译运行,生成elf可执行文件。

使用‘readelf ’命令,得到下面的ELF Header头文件的信息,如下图:
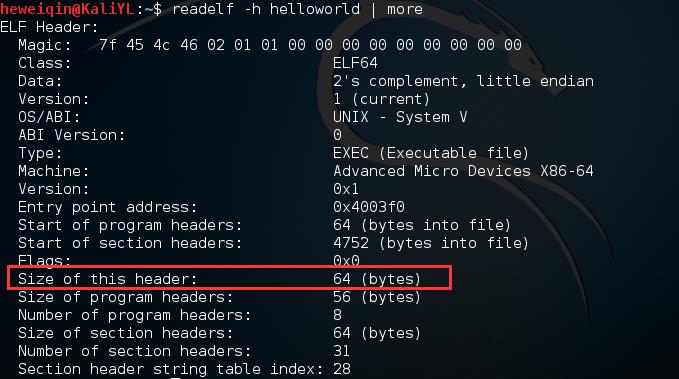
通过上图信息,可以得出Elf Header的Size为64bytes,所以可以使用hexdump工具将头文件的16进制表打开。
如下图使用:‘hexdump –x elf1 –n 64’命令来查看elf文件头的16进制表(前64bytes)对格式进行分析。

第一行,对应e_ident[EI_NIDENT]。实际表示内容为7f454c46020101000000000000000000,前四个字节7f454c46(0x45,0x4c,46是\'e\',\'l\',\'f\'对应的ascii编码)是一个魔数,表示这是一个ELF对象。
接下来的一个字节02表示是一个64位对象,接下来的一个字节01表示是小端法表示,再接下来的一个字节01表示文件头版本。剩下的默认都设置为0.
第二行,e_type值为0x0002,表示是一个可执行文件。e_machine值为0x003e,表示是Advanced Micro Devices X86-64处理器体系结构。e_version值为0x00000100,表示是当前版本。e_entry值为0x 004003f0,表示入口点(下面会用到)。
第三行,e_phoff值为0x40,表示程序头表。e_shoff值为0x1290,表示段表的偏移地址。
第四行,e_flags值为0x00000000,表示未知处理器特定标志。e_ehsize值为0x0040,表示elf文件头大小(正好是64个字节)。e_phentsize表示一个program header表中的入口的长度,值为0x0038。e_phnum的值为0x0008,给出program header表中的入口数目。e_shentsize值为0x0040表示段头大小为64个字节。e_shnum值为0x001f,表示段表入口有31个。e_shstrndx值为0x001c,表示段名串表的在段表中的索引号。
2、通过文件头找到section header table,理解其内容
输入:hexdump –x elf1来用16进制的数字来显示elf1的内容
(其中,标红第二列是16进制表示的偏移地址)
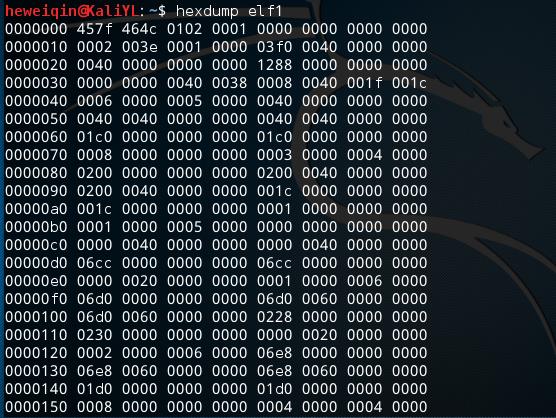
输入:objdump –x elf1来显示elf1中各个段以及符号表的相关信息:
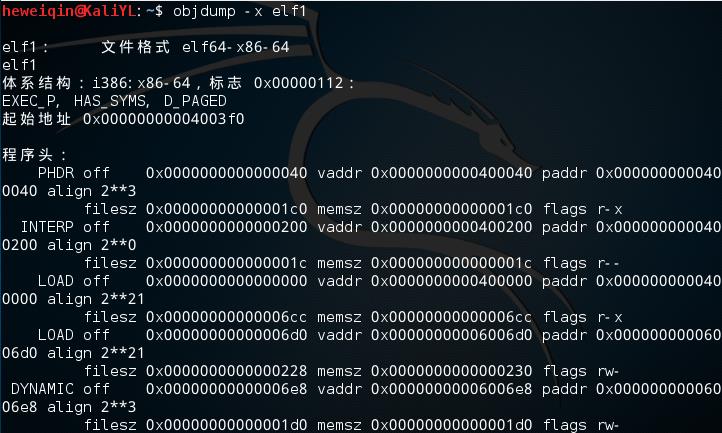
输入:readelf –a elf1来查看各个段信息:
ELF文件头信息:
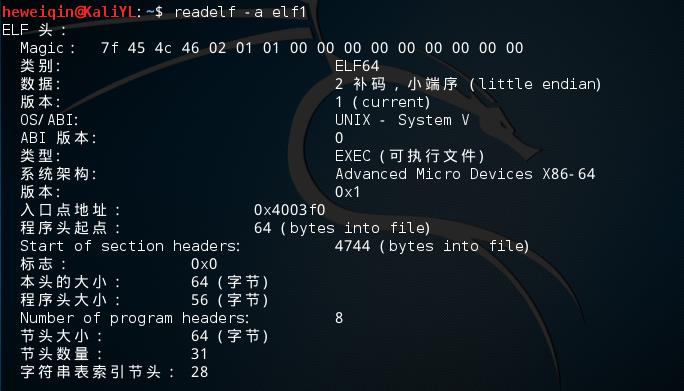
段表Section header table:

.text的索引值为14。
符号表 Symbol table:

3、通过section header table找到各section
在一个ELF文件中有一个section header table,通过它我们可以定位到所有的 section,而 ELF header 中的e_shoff 变量就是保存 section header table 入口对文件头的偏移量。而每个 section 都会对应一个 section header ,所以只要在 section header table 中找到每个 section header,就可以通过 section header 找到你想要的 section。
下面以可执行文件elf1为例,以保存代码段的 section 为例来讲解读取某个section 的过程。
使用‘vi /usr/include/elf.h ’命令查看Sections Header的结构体:

由上面分析可知,section headers table中的每一个section header所占的size均为64字节,ELF header得到了e_shoff变量的值为0X1170,也就是table入口的偏移量,通过看e_shnum值为0x001e,表示段表入口有30个。
所以从0x00001170开始有30个段,每个段占64个字节大小,输入 hexdump elf1查看:

第一个段,其中内容全部为0,所以不表示任何段。
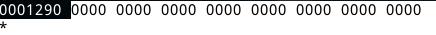
第二个段,为.interp段,段偏移sh_offset为0X200,段大小sh_size为0X1c

第三个段,为.note.ABI-tag段,段偏移sh_offset为0X 21c,段大小sh_size为0X20。

第四个段,为.note.gnu.build-i段,段偏移sh_offset为0X23c(红线), 段大小sh_size为0X 24(蓝线)。

第五个段,为.gnu.hash段,段偏移sh_offset为0X 260, 段大小sh_size为0X 1c
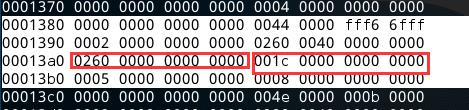
……中间的段省略……
第十四个段,为.text段, 段偏移sh_offset为0X 3f0, 段大小sh_size为0X 182

下面用readelf –S elf1命令先去看看elf1的section table中存放的所有的 section header。
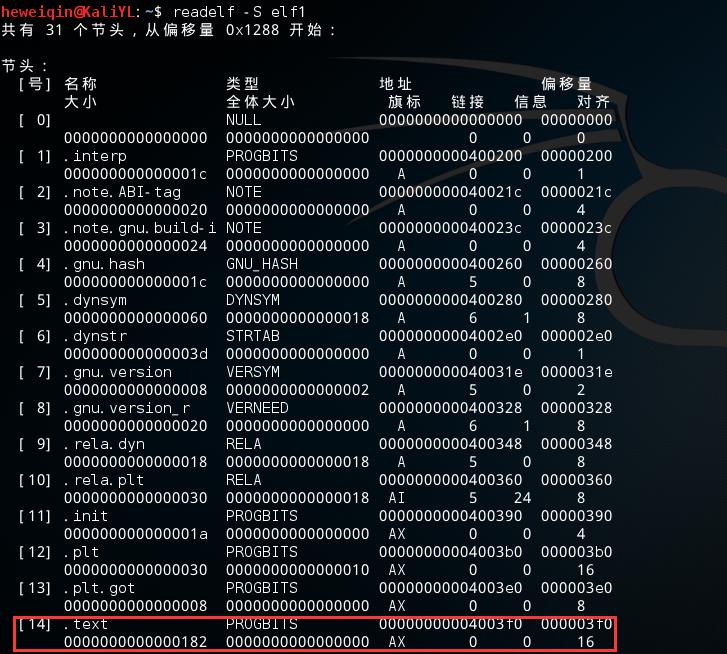
我们用readelf 命令去查看.text这个 section 中的内容,
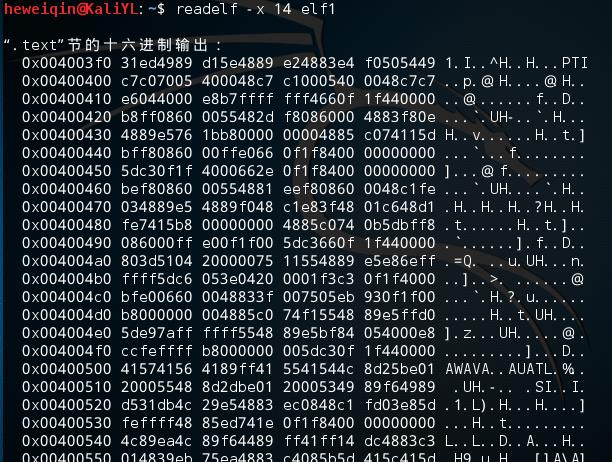
输入readelf –x 14 elf1,对14索引号的.text的section的内容进行查看:
下面用 hexdump 的方法去读取.text这个 section 中的内容,通过看section header中.text中offset和size分别是0x3f0和0x182,通过16进制向10进制转换得到offset:1008和size:386。
输入 hexdump –s 1008 –n 386 –C elf1

得到了和上面的readelf得到的相同。
使用下面命令对elf1的文本段(.text)进行反汇编:
objdump –d elf1 得到如下图:
可以看出,使用反汇编的16进制数据和前面查找到的是相同的。

我们可以使用相同的方法对其他section进行查看,.data 数据段 .bbs 堆栈段(存放没有初始化的数据) .symtab(符号表)段。
① 查看.data数据段的section
比较简单,使用readelf –x 24(索引号) elf1(文件名)来查看

同理分析其他段表
4、理解常见.text .strtab .symtab .rodata等section
①.text section是可执行指令的集合,.data和.text都是属于PROGBITS类型的section,这是将来要运行的程序与代码。查询段表可知.text section的位偏移为0x0000440,size为0x0000192。
②.strtab section是属于STRTAB类型的section,可以在文件中看到,它存着字符串,储存着符号的名字。位偏移为0x0001f08,size为0x0000238。
③.symtab section存放所有section中定义的符号名字,比如“data_items”,“start_loop”。 .symtab section是属于SYMTAB类型的section,它描述了.strtab中的符号在“内存”中对应的“内存地址”。 位偏移为0x00018f0,size为0x0000618。
④.rodata section,ro代表read only,即只读数据(const)。位偏移为0x00005e0,size为0x000000c。

以上是关于Linux内核分析——ELF文件格式分析的主要内容,如果未能解决你的问题,请参考以下文章