Flume传输数据事务分析
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flume传输数据事务分析相关的知识,希望对你有一定的参考价值。
Flume传输数据事务分析
本文基于ThriftSource,MemoryChannel,HdfsSink三个组件,对Flume传输数据的事务进行分析。假设使用的是其它组件。Flume事务详细的处理方式将会不同。普通情况下。用MemoryChannel就好了,我们公司用的就是这个。FileChannel速度慢,尽管提供日志级别的数据恢复,可是普通情况下,不断电MemoryChannel是不会丢数据的。
Flume提供事物操作。保证用户的数据的可靠性,主要体如今:
- 数据在传输到下个节点时(一般是批量数据),假设接收节点出现异常,比方网络异常。则回滚这一批数据。
因此有可能导致数据重发
-
同个节点内,Source写入数据到Channel,数据在一个批次内的数据出现异常,则不写入到Channel。
已接收到的部分数据直接抛弃,靠上一个节点重发数据。
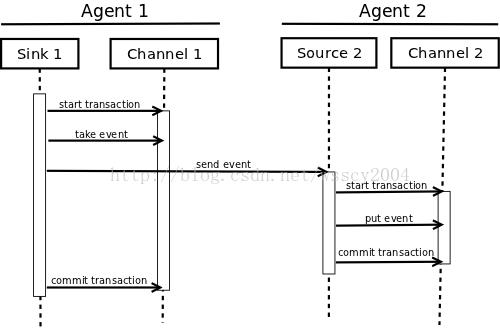
编程模型
Flume在对Channel进行Put和Take操作的时候。必需要用事物包住,比方:
Channel ch = new MemoryChannel();
Transaction txn = ch.getTransaction();
//事物開始
txn.begin();
try {
Event eventToStage = EventBuilder.withBody("Hello Flume!",
Charset.forName("UTF-8"));
//往暂时缓冲区Put数据
ch.put(eventToStage);
//或者ch.take()
//将这些数据提交到channel中
txn.commit();
} catch (Throwable t) {
txn.rollback();
if (t instanceof Error) {
throw (Error)t;
}
} finally {
txn.close();
}
Put事务流程
Put事务能够分为下面阶段:
- doPut:将批数据先写入暂时缓冲区putList
- doCommit:检查channel内存队列是否足够合并。
- doRollback:channel内存队列空间不足,抛弃数据
我们从Source数据接收到写入Channel这个过程对Put事物进行分析。

ThriftSource会spawn多个Worker线程(ThriftSourceHandler)去处理数据,Worker处理数据的接口。我们仅仅看batch批量处理这个接口:
@Override
public Status appendBatch(List<ThriftFlumeEvent> events) throws TException {
List<Event> flumeEvents = Lists.newArrayList();
for(ThriftFlumeEvent event : events) {
flumeEvents.add(EventBuilder.withBody(event.getBody(),
event.getHeaders()));
}
//ChannelProcessor,在Source初始化的时候传进来.将数据写入相应的Channel
getChannelProcessor().processEventBatch(flumeEvents);
...
return Status.OK;
}
事务逻辑都在processEventBatch这种方法里:
public void processEventBatch(List<Event> events) {
...
//预处理每行数据,有人用来做ETL嘛
events = interceptorChain.intercept(events);
...
//分类数据,划分不同的channel集合相应的数据
// Process required channels
Transaction tx = reqChannel.getTransaction();
...
//事务開始,tx即MemoryTransaction类实例
tx.begin();
List<Event> batch = reqChannelQueue.get(reqChannel);
for (Event event : batch) {
// 这个put操作实际调用的是transaction.doPut
reqChannel.put(event);
}
//提交,将数据写入Channel的队列中
tx.commit();
} catch (Throwable t) {
//回滚
tx.rollback();
...
}
}
...
}
每一个Worker线程都拥有一个Transaction实例,保存在Channel(BasicChannelSemantics)里的ThreadLocal变量currentTransaction.
那么。事务究竟做了什么?

实际上。Transaction实例包括两个双向堵塞队列LinkedBlockingDeque(感觉不是必需用双向队列,每一个线程写自己的putList,又不是多个线程?),分别为:
- putList
- takeList
对于Put事物操作,当然是仅仅用到putList了。
putList就是一个暂时的缓冲区。数据会先put到putList,最后由commit方法会检查channel是否有足够的缓冲区,有则合并到channel的队列。
channel.put -> transaction.doPut:
protected void doPut(Event event) throws InterruptedException {
//计算数据字节大小
int eventByteSize = (int)Math.ceil(estimateEventSize(event)/byteCapacitySlotSize);
//写入暂时缓冲区putList
if (!putList.offer(event)) {
throw new ChannelException(
"Put queue for MemoryTransaction of capacity " +
putList.size() + " full, consider committing more frequently, " +
"increasing capacity or increasing thread count");
}
putByteCounter += eventByteSize;
}
transaction.commit:
@Override
protected void doCommit() throws InterruptedException {
//检查channel的队列剩余大小是否足够
...
int puts = putList.size();
...
synchronized(queueLock) {
if(puts > 0 ) {
while(!putList.isEmpty()) {
//写入到channel的队列
if(!queue.offer(putList.removeFirst())) {
throw new RuntimeException("Queue add failed, this shouldn‘t be able to happen");
}
}
}
//清除暂时队列
putList.clear();
...
}
...
}
假设在事务期间出现异常,比方channel剩余空间不足,则rollback:
@Override
protected void doRollback() {
...
//抛弃数据。没合并到channel的内存队列
putList.clear();
...
}
Take事务
Take事务分为下面阶段:
- doTake:先将数据取到暂时缓冲区takeList
- 将数据发送到下一个节点
- doCommit:假设数据所有发送成功。则清除暂时缓冲区takeList
- doRollback:数据发送过程中假设出现异常,rollback将暂时缓冲区takeList中的数据归还给channel内存队列。
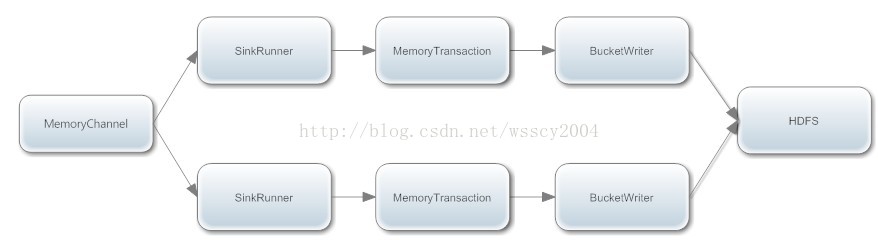
Sink事实上是由SinkRunner线程调用Sink.process方法来了处理数据的。我们从HdfsEventSink的process方法说起,Sink类都有个process方法。用来处理数据传输的逻辑。:
public Status process() throws EventDeliveryException {
...
Transaction transaction = channel.getTransaction();
...
//事务開始
transaction.begin();
...
for (txnEventCount = 0; txnEventCount < batchSize; txnEventCount++) {
//take数据到暂时缓冲区,实际调用的是transaction.doTake
Event event = channel.take();
if (event == null) {
break;
}
...
//写数据到HDFS
bucketWriter.append(event);
...
// flush all pending buckets before committing the transaction
for (BucketWriter bucketWriter : writers) {
bucketWriter.flush();
}
//commit
transaction.commit();
...
} catch (IOException eIO) {
transaction.rollback();
...
} finally {
transaction.close();
}
}
大致流程图:
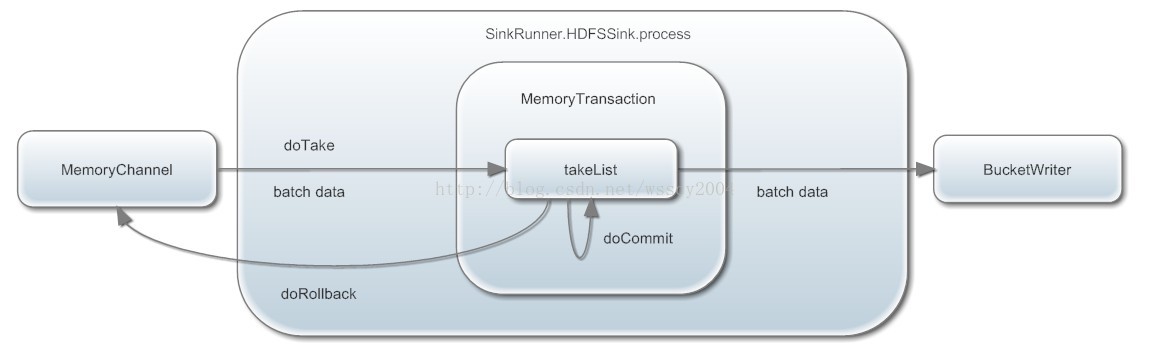
接着看看channel.take。作用是将数据放到暂时缓冲区,实际调用的是transaction.doTake:
protected Event doTake() throws InterruptedException {
...
//从channel内存队列取数据
synchronized(queueLock) {
event = queue.poll();
}
...
//将数据放到暂时缓冲区
takeList.put(event);
...
return event;
}
接着,HDFS写线程bucketWriter将take到的数据写到HDFS,假设批数据都写完了。则要commit了:
protected void doCommit() throws InterruptedException {
...
takeList.clear();
...
}
非常easy。事实上就是清空takeList而已。
假设bucketWriter在写数据到HDFS的时候出现异常。则要rollback:
protected void doRollback() {
int takes = takeList.size();
//检查内存队列空间大小,是否足够takeList写回去
synchronized(queueLock) {
Preconditions.checkState(queue.remainingCapacity() >= takeList.size(), "Not enough space in memory channel " +
"queue to rollback takes. This should never happen, please report");
while(!takeList.isEmpty()) {
queue.addFirst(takeList.removeLast());
}
...
}
...
}以上是关于Flume传输数据事务分析的主要内容,如果未能解决你的问题,请参考以下文章