MYSQL 大批量数据插入
Posted 河南骏
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MYSQL 大批量数据插入相关的知识,希望对你有一定的参考价值。
最近在做mysql大批量数据的测试,就简单总结一下遇到的问题:
首先我是简单的写了一个MYSQL的循环插入数据的SP,具体如下:
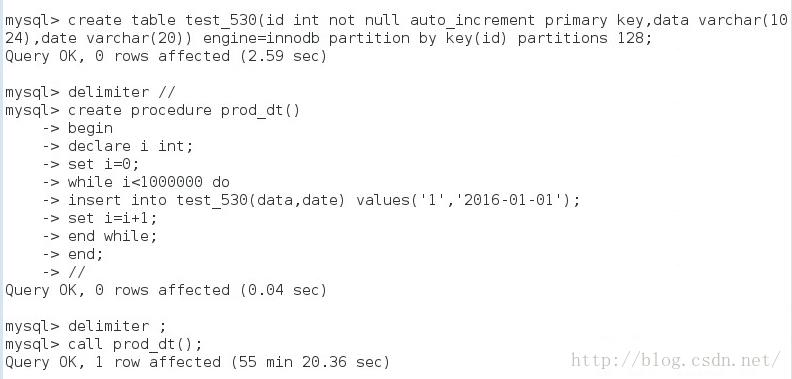
这是插入100W数据的过程和结果,可以看到是换了55min +20S约3320秒(约300rows/s),看到之后我是只崩溃,就在网上查了些提速的方法:
0. 最快的当然是直接 copy 数据库表的数据文件(版本和平台最好要相同或相似);
1. 设置 innodb_flush_log_at_trx_commit = 0 ,相对于 innodb_flush_log_at_trx_commit = 1 可以十分明显的提升导入速度;
2. 使用 load data local infile 提速明显;
3. 修改参数 bulk_insert_buffer_size, 调大批量插入的缓存;
4. 合并多条 insert 为一条: insert into t values(a,b,c), (d,e,f) ,,,
5. 手动使用事物;
当数据量较大时,如上百万甚至上千万记录时,向MySQL数据库中导入数据通常是一个比较费时的过程。通常可以采取以下方法来加速这一过程:
一、对于Myisam类型的表,可以通过以下方式快速的导入大量的数据。 ALTER TABLE tblname DISABLE KEYS; loading the data ALTER TABLE tblname ENABLE KEYS; 这两个命令用来打开或者关闭Myisam表非唯一索引的更新。在导入大量的数据到一个非空的Myisam表时,通过设置这两个命令,可以提高导入的效率。对于导入大量数据到一个空的Myisam表,默认就是先导入数据然后才创建索引的,所以不用进行设置。
二、对于Innodb类型的表,有以下几种方式可以提高导入的效率: ①因为Innodb类型的表是按照主键的顺序保存的,所以将导入的数据按照主键的顺序排列,可以有效的提高导入数据的效率。如果Innodb表没有主键,那么系统会默认创建一个内部列作为主键,所以如果可以给表创建一个主键,将可以利用这个优势提高导入数据的效率。
②在导入数据前执行SET UNIQUE_CHECKS=0,关闭唯一性校验,在导入结束后执行SET UNIQUE_CHECKS=1,恢复唯一性校验,可以提高导入的效率。
③如果应用使用自动提交的方式,建议在导入前执行SET AUTOCOMMIT=0,关闭自动提交,导入结束后再执行SET AUTOCOMMIT=1,打开自动提交,也可以提高导入的效率。
而我创建的是Innodb类型的表,分了128个分区。而我依照以上的方法,设置如下:

插入百万数据的SP如下:

可以明显的看到插入百万数据是100S左右,速度提升了33倍之多。
速度是提升了不少,那就加大插入的数据量,提升10倍,即插入千万的数据量,具体的SP如下:
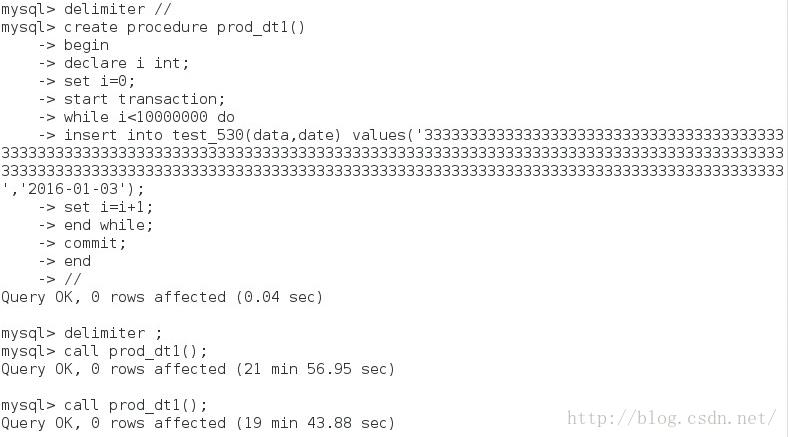
可以看到时间差不多是1200s左右,因为字段加长了,可能也有影响插入的速度。
为了具体验证,就按千万行插入,字段的长度为1000字节,来查看结果,具体的SP和结果如下:


可以看到用时33min 51s月(约2031秒),即(4900row/s),速度下降很多,字符长度看来是用影响的。
varchar字段
字段的限制在字段定义的时候有以下规则:
a) 存储限制
varchar 字段是将实际内容单独存储在聚簇索引之外,内容开头用1到2个字节表示实际长度(长度超过255时需要2个字节),因此最大长度不能超过65535。
b) 编码长度限制
字符类型若为gbk,每个字符最多占2个字节,最大长度不能超过32766;
字符类型若为utf8,每个字符最多占3个字节,最大长度不能超过21845。
对于英文比较多的论坛 ,使用GBK则每个字符占用2个字节,而使用UTF-8英文却只占一个字节。
若定义的时候超过上述限制,则varchar字段会被强行转为text类型,并产生warning。
c) 行长度限制
导致实际应用中varchar长度限制的是一个行定义的长度。 MySQL要求一个行的定义长度不能超过65535。若定义的表长度超过这个值,则提示
ERROR 1118 (42000): Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. You have to change some columns to TEXT or BLOBs。
2、计算例子
举两个例说明一下实际长度的计算。
a) 若一个表只有一个varchar类型,如定义为
create table t4(c varchar(N)) charset=gbk;
则此处N的最大值为(65535-1-2)/2= 32766。
减1的原因是实际行存储从第二个字节开始';
减2的原因是varchar头部的2个字节表示长度;
除2的原因是字符编码是gbk。
b) 若一个表定义为
create table t4(c int, c2 char(30), c3 varchar(N)) charset=utf8;
则此处N的最大值为 (65535-1-2-4-30*3)/3=21812
减1和减2与上例相同;
减4的原因是int类型的c占4个字节;
减30*3的原因是char(30)占用90个字节,编码是utf8。
如果被varchar超过上述的b规则,被强转成text类型,则每个字段占用定义长度为11字节,当然这已经不是“varchar”了。
在mysql 中用"SHOW VARIABLES LIKE '%CHAR%'"查看字符集:
再次升级插入的数据量,提升10倍,看插入的时间及占用的内存,字段的字节同样为1000,具体的SP和结果如下:



从上图可以清楚的看到,插入1亿条数据的时间为5hours +20 min+ 56s=19256s,平均插入的条数为(5193 rows/s)。根上次插入1千万条的时间差不多,再看所耗磁盘空间,用了98G的空间,跟上次插入千万条数据时的(26G-17G=9G)也是成线性关系的。按照本机500G的磁盘空间,存储1行1K字节大小的数据,本机可以存储理想极限情况下为5亿条数据,保守为4~4.5亿左右合适,以防其他的应用或者数据库的UNDO,索引空间占用。
最后再看一次查询的时间,上次插入百万数,查询数据量的时间
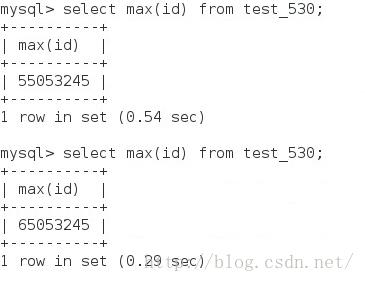
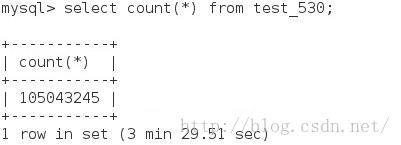
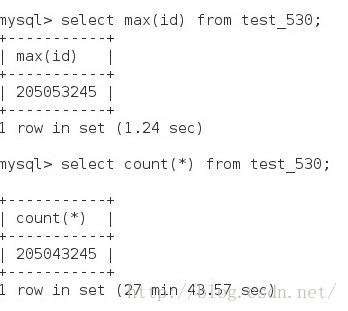
因为创建了索引,在查百万级的数据量时,时间是1秒左右,在数据量上升到千万时,查询1亿5百万时,时间为3Min 30S,再插入1亿数据,查询数据量,时间达到27min 43s,可见,不是线性关系,是几何级增加的。
=====================================================================================================
现在描述集群环境的测试
集群:32G内存 ,500G硬盘,3台虚拟机也就是3个节点:188.188.2.181(主节点,数据节点和SQL节点)、188.188.2.182(数据节点和SQL节点)和188.188.2.183(数据节点和SQL节点)。/root目录分区磁盘空间200G(原先默认的是50G)、插入的数据量为8000KW,所占磁盘空间为下图
插入前的内存:

插入后内存:

数据内存所占空间:(910051-5)*32K=27.77G -----300W条/G
索引内存所占空间:54980*8K=430M
插入前的磁盘空间:

插入后的磁盘空间:

磁盘空间:200G*(34%-5%)=58G -----143W条/G
插入前的条数:

插入后的条数:

条数的:82551267条
=================================================================================================================
2016-06-03,在上上述配置的基础上,增加一个数据节点,184,datamemory:28000M indexmemory=1024M NoOfFragmentLogFiles=64
==================================================================================================================

内存如上
磁盘情况:


到达一个峰值,插不进去,需要调整参数

------------------------------------------------------------------------------------------------

---------------------------------------------------------------------------------------------

======================================================================================================
现在开始DataMemory =28000M
NoOfFragmentLogFiles=128
插入8400W条数据
===================================================================================================================



=======================================================上述三个截图是4台数据节点的极限情况!!!
为了对比的严谨性和科学性,现在重新比较3台数据节点和4台数据节点的横向比较,为了避免管理节点和数据节点SQL节点在一台机子站占用空间。现在把管理节点单拎出来,185做管理节点,181、182、183做数据节点和SQL节点,
管理节点的配置:Datamemory=30000M Indexmemory=1024M MaxNoOfConcurrentTransactions=100000 MaxNoOfConcurrentOperations=200000 NoOfFragmentLogFiles=128
-----------------------------------------------------------------------------------------------------------------
两台数据节点 三台数据节点 四台数据节点
-----------------------------------------------------------------------------------------------------------------
data useage memory 4*32K---->849052*32K(25.9G)5*32K---->910541*32K(27.787G) 4*32K----->881480*32K(26.9G)
index usage memory 10*8K-->45180 *8K(352.9M) 9*8K---->51753*8k(404.3M) 8*8k---->47572*8K(371.66M)
max record number 533300000 76200000 110500000
initial used disk size 8.8G 8.8G 8.9G
final used disk size 67G 68G 69G
内存占用率都为94%时,表is full
===================================================================================================================
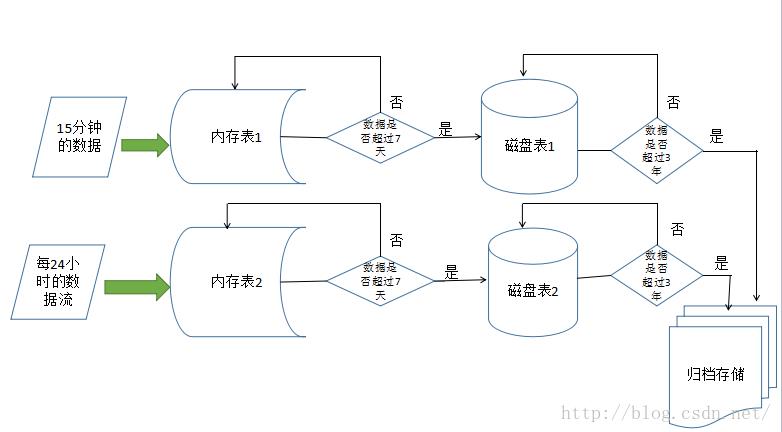
在资源有限的情况下,合理的配置是三台数据节点,每台虚拟机的配置是32G 内存,500G硬盘,目标是存储近10T的数据,如果单纯的按这种集群内存表来存储,要400个数据节点,这个有点夸张了,现实的生产环境中也不可能是这样的,所以,接下来需要用磁盘表来登场了,大致的设计方案的流程图如下:
=======================================================================================
模拟数据流的村过程如下:prod_dt
create procedure prod_dt()
begin
declare i,maxid int;
set i=0;
select max(id) into maxid from loadtest;
if maxid<10000000 then
while i<100000 do
insert into loadtest(data,record_date) values('1111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111','2016-06-06');
set i=i+1;
end while;
commit;
elseif maxid>10000000 and maxid<20000000 then
set i=0;
while i<100000 do
insert into loadtest(data,record_date) values('2222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222','2016-06-07');
set i=i+1;
end while;
commit;
elseif maxid>20000000 and maxid<30000000 then
set i=0;
while i<100000 do
insert into loadtest(data,record_date) values('3333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333333','2016-06-08');
set i=i+1;
end while;
commit;
elseif maxid>30000000 and maxid<40000000 then
set i=0;
while i<100000 do
insert into loadtest(data,record_date) values('4444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444444','2016-06-09');
set i=i+1;
end while;
commit;
elseif maxid>40000000 and maxid<50000000 then
set i=0;
while i<100000 do
insert into loadtest(data,record_date) values('55555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555555','2016-06-10');
set i=i+1;
end while;
commit;
elseif maxid>50000000 and maxid<60000000 then
set i=0;
while i<100000 do
insert into loadtest(data,record_date) values('666666666666666666666666666666666666666666666666666666666666666666666666666666666666666666666666666666666','2016-06-11');
set i=i+1;
end while;
commit;
elseif maxid>60000000 and maxid<70000000 then
set i=0;
while i<100000 do
insert into loadtest(data,record_date) values('7777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777','2016-06-12');
set i=i+1;
end while;
commit;
elseif maxid>70000000 and maxid<80000000 then
set i=0;
while i<100000 do
insert into loadtest(data,record_date) values('888888888888888888888888888888888888888888888888888888888888888888888888888888888888888888888888888888888','2016-06-13');
set i=i+1;
end while;
commit;
elseif maxid>80000000 and maxid<90000000 then
set i=0;
while i<100000 do
insert into loadtest(data,record_date) values('999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999','2016-06-14');
set i=i+1;
end while;
commit;
else
alter event e_load disable;
end if;
end
================================================================================================
模拟存储超过7天的数据,要放到文件中中转,再load data infile插入到磁盘表里,因为MYSQL的存储过程不允许有LOAD DATA infile 语句,故而,需要写一个SHELL脚本定时调用。具体的转移数据脚本transfer_dt:
create procedure transfer_dt()
begin
declare maxdate,currdate varchar(20);
select max(record_date) into maxdate from loadtest;
set currdate=curdate();
start transaction;
if maxdate=currdate then
select * from loadtest where record_date<date_sub(maxdate,interval 7 day) into outfile '/tmp/loadtest.txt';
delete from loadtest where record_date<date_sub(maxdate,interval 7 day);
else
select * from loadtest where record_date<date_sub(currdate,interval 7 day) into outfile '/tmp/loadtest.txt';
delete from loadtest where record_date<date_sub(currdate,interval 7 day);
end if;
end
============================具体的load data shell scripts ,z需要用linux的定时任务去调用shell 脚本:
#!/bin/bash
mysql -u root -vv -pholystar << EOF
use cluster;
load data infile '/tmp/loadtest.txt' into table load_dsk;
exit
EOF
======================================================================================================
大致的数据设计方案和具体模拟设计差不多到这儿,不过需要进行压力测试,有问题的话,再更新吧!!!
以上是关于MYSQL 大批量数据插入的主要内容,如果未能解决你的问题,请参考以下文章