R_Studio(贷款)数据规范化处理[最小-最大规范化零-均值规范化小数定标规范化]
Posted Cynical丶Gary
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R_Studio(贷款)数据规范化处理[最小-最大规范化零-均值规范化小数定标规范化]相关的知识,希望对你有一定的参考价值。
农场申请贷款.csv
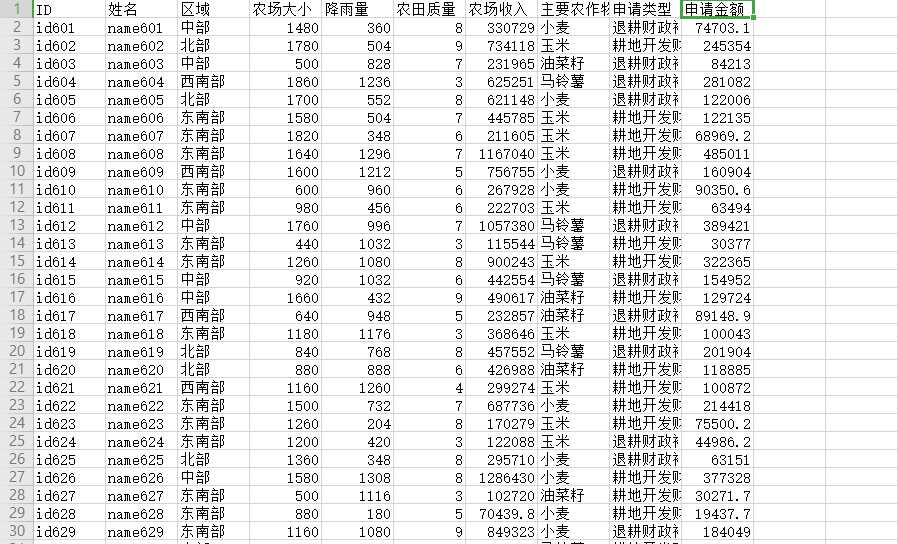
对“农场申请贷款.csv”中农场大小、降雨量、农场质量、农场收入进行数据规范化处理 行数[4 5 6 7]
“农场申请贷款.csv”中存在缺失值,已对数据进行预处理


setwd(‘D:\\data‘) list.files() #数据读取 dat=read.csv(file="农场申请贷款.csv",header=TRUE) sub=which(is.na(dat[5]$‘降雨量‘))#识别缺失值所在行数 #将数据集分成完整数据和缺失数据两部分 inputfile1=dat[-sub,] #缺失部分 inputfile2=dat[sub,] #不缺失部分 dat=inputfile1 #最小-最大规范化 b1=(dat[,4]-min(dat[,4]))/(max(dat[,4])-min(dat[,4])) b2=(dat[,5]-min(dat[,5]))/(max(dat[,5])-min(dat[,5])) b3=(dat[,6]-min(dat[,6]))/(max(dat[,6])-min(dat[,6])) b4=(dat[,7]-min(dat[,7]))/(max(dat[,7])-min(dat[,7])) data_scatter=cbind(b1,b2,b3,b4) newdata=dat for(i in 4:7){ newdata[,i] =(dat[,i]-min(dat[,i]))/(max(dat[,i])-min(dat[,i])) } data_scatter=cbind(b1,b2,b3,b4) data_scatter=cbind(b1,b2,b3,b4) #零-均值规范化 data_zscore=scale(data_scatter) data_zscore #小数定标规范化 i1=ceiling(log(max(abs(dat[,4])),10))#小数定标的指数 c1=dat[,4]/10^i1 i2=ceiling(log(max(abs(dat[,5])),10)) c2=dat[,5]/10^i2 i3=ceiling(log(max(abs(dat[,6])),10)) c3=dat[,6]/10^i3 i4=ceiling(log(max(abs(dat[,6])),10)) c4=dat[,7]/10^i4 data_dot=cbind(c1,c2,c3,c4) #打印结果 options(digits = 4)#控制输出结果的有效位数 data;data_scatter;data_zscore;data_dot
最小-最大规范化:对原始数据的线性变换,将数值映射到[0,1]
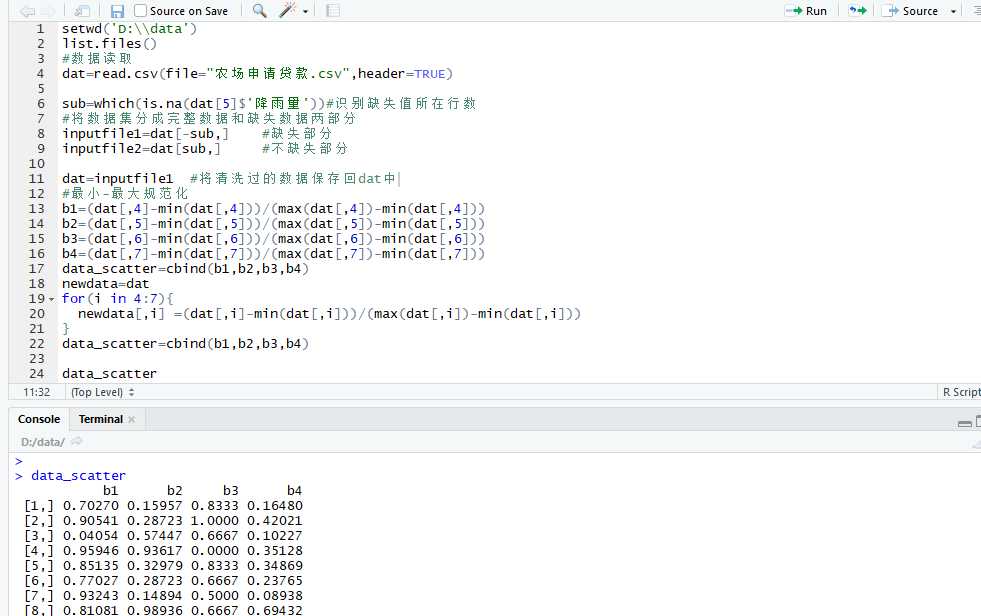
setwd(‘D:\\data‘) list.files() #数据读取 dat=read.csv(file="农场申请贷款.csv",header=TRUE) sub=which(is.na(dat[5]$‘降雨量‘))#识别缺失值所在行数 #将数据集分成完整数据和缺失数据两部分 inputfile1=dat[-sub,] #缺失部分 inputfile2=dat[sub,] #不缺失部分 dat=inputfile1 #将清洗过的数据保存回dat中 #最小-最大规范化 b1=(dat[,4]-min(dat[,4]))/(max(dat[,4])-min(dat[,4])) b2=(dat[,5]-min(dat[,5]))/(max(dat[,5])-min(dat[,5])) b3=(dat[,6]-min(dat[,6]))/(max(dat[,6])-min(dat[,6])) b4=(dat[,7]-min(dat[,7]))/(max(dat[,7])-min(dat[,7])) data_scatter=cbind(b1,b2,b3,b4) newdata=dat for(i in 4:7){ newdata[,i] =(dat[,i]-min(dat[,i]))/(max(dat[,i])-min(dat[,i])) } data_scatter=cbind(b1,b2,b3,b4) data_scatter
零-均值规范化:标准差规范化,经过处理的数据的均值位0,标准差位1
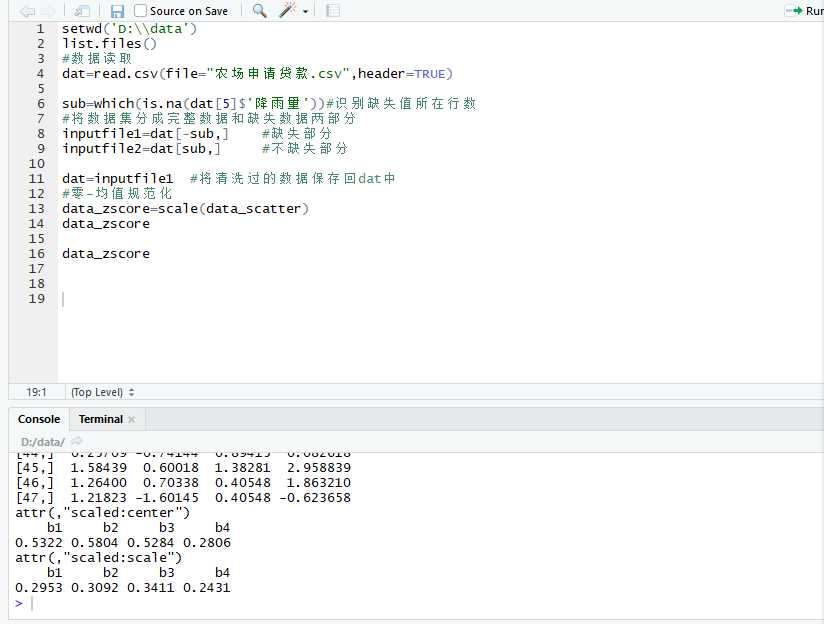
scale方法中的两个参数center和scale的解释:
center和scale默认为真,即T或者TRUE
center为真表示数据中心化(只减去均值不做其他处理)
scale为真表示数据标准化
setwd(‘D:\\data‘) list.files() #数据读取 dat=read.csv(file="农场申请贷款.csv",header=TRUE) sub=which(is.na(dat[5]$‘降雨量‘))#识别缺失值所在行数 #将数据集分成完整数据和缺失数据两部分 inputfile1=dat[-sub,] #缺失部分 inputfile2=dat[sub,] #不缺失部分 dat=inputfile1 #将清洗过的数据保存回dat中 #零-均值规范化 data_zscore=scale(data_scatter) data_zscore data_zscore
小数定标规范化:最小-最大规范化保持原有数据之间的联系
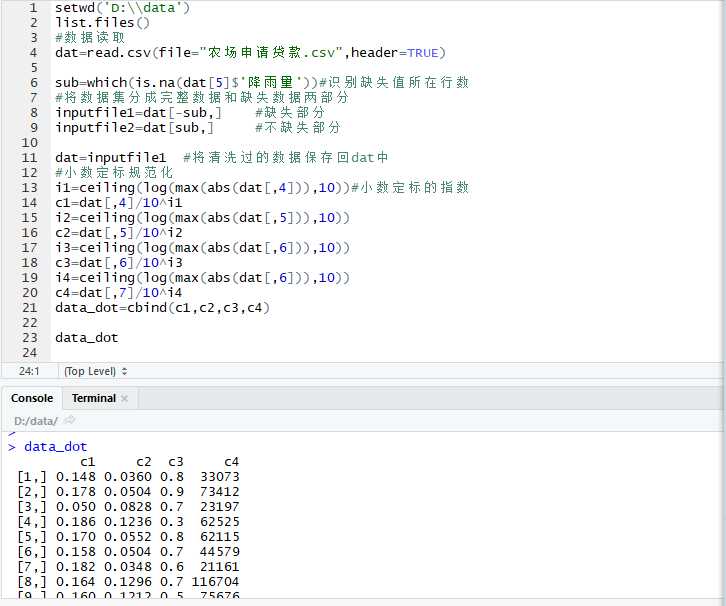
setwd(‘D:\\data‘) list.files() #数据读取 dat=read.csv(file="农场申请贷款.csv",header=TRUE) sub=which(is.na(dat[5]$‘降雨量‘))#识别缺失值所在行数 #将数据集分成完整数据和缺失数据两部分 inputfile1=dat[-sub,] #缺失部分 inputfile2=dat[sub,] #不缺失部分 dat=inputfile1 #将清洗过的数据保存回dat中 #小数定标规范化 i1=ceiling(log(max(abs(dat[,4])),10))#小数定标的指数 c1=dat[,4]/10^i1 i2=ceiling(log(max(abs(dat[,5])),10)) c2=dat[,5]/10^i2 i3=ceiling(log(max(abs(dat[,6])),10)) c3=dat[,6]/10^i3 i4=ceiling(log(max(abs(dat[,6])),10)) c4=dat[,7]/10^i4 data_dot=cbind(c1,c2,c3,c4) data_dot
以上是关于R_Studio(贷款)数据规范化处理[最小-最大规范化零-均值规范化小数定标规范化]的主要内容,如果未能解决你的问题,请参考以下文章