STL简单hashtable的实现
Posted chengonghao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了STL简单hashtable的实现相关的知识,希望对你有一定的参考价值。
1. 简介
Hash_table可提供对任何有名项(named item)的存取、删除和查询操作。由于操作对象是有名项,所以hash_table可被视为是一种字典结构(dictionary)。
Hash_table使用名为hash faction的散列函数来定义有名项与存储地址之间的映射关系。使用hash faction会带来一个问题:不同的有名项可能被映射到相同的地址,这便是所谓的碰撞(collision)问题,解决碰撞问题的方法主要有三种:线性探测(linear probing)、二次探测(quadratic probing)、开链(separate chaining)。
1.1 线性探测
先介绍一个名词:负载系数(loading factor),意为元素个数除以表格大小。负载系数永远在0 ~ 1之间(除非使用开链策略)。
当hash faction计算出某个元素的插入位置,而该位置已经被占用时,我们循序往下查找,直到找到一个可用空间为止。然而这凸显了一个问题:平均插入成本的涨幅,远高于负载系数的涨幅。这样的现象在hashing过程中被称为主集团(primary clustering)。此时我们手上有一大团已经被占用的方格,插入操作极有可能在主集团所形成的泥泞中艰难爬行,不断碰撞,最后好不容易才找到一个落脚处,但这又助长了主集团的泥泞面积。
1.2 二次探测
二次探测主要用来解决主集团的问题。如果hash faction计算出新元素的位置为H,但该位置被占用,那我们尝试H + 1^2、H + 2^2、H +3^2…..,而不是H + 1、H + 2、H + 3…….。二次探测可以消除主集团(primary clustering),但是可能造成次集团(secondary clustering)。
1.3 开链
这是我们采用的方法。
在每个表格元素中维护一个 list(链表),list 由 hash faction 为我们,我们在list上执行元素的插入、查找、删除等操作,虽然对list进行的查询是线性操作,但是 list 足够短的话,我们也能获得较好的效率。注意,使用开链法,表格的负载系数可能大于1。
1.4 开链法的名称约定
下面介绍开链法中的基本术语,这些术语将贯穿博客和代码注释。
我们用vector作为hash_table的底层实现,并称hash_table内的每个元素为桶子bucket,每个桶子里装着一个list头指针,通过list头指针,可以串联出一串节点(node)。这就是开链法的精髓:hash_table(底层是vector)的每个元素装着list头指针,每个list头指针可以开出一条链表。
Hash_table的实现方式有点像deque,关于deque的实现,请看另一篇博客:STL简单deque的实现
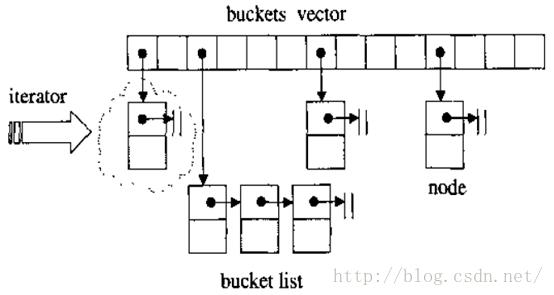
2.设计与实现
我用VS2013写的程序(github),set和multiset版本的代码位于cghSTL/version/cghSTL-0.4.3.rar
在STL中,set和multiset的底层都需要以下几个文件:
1. globalConstruct.h,构造和析构函数文件,位于cghSTL/allocator/cghAllocator/
2. cghAlloc.h,空间配置器文件,位于cghSTL/allocator/cghAllocator/
3. hash_table_node.h,hash_table节点的实现,位于cghSTL/associative containers/RB-tree/
4. hash_table_iterator.h,hash_table迭代器的实现,位于cghSTL/associativecontainers/cgh_hash_table/
5. cgh_hash_table.h,hash_table的实现,位于cghSTL/associativecontainers/cgh_hash_table/
6. test_cgh_hash_table,测试文件,位于cghSTL/test/
另外,hash_table的底层采用vector作为容器,关于vector的实现,请看博客:STL简单vector的实现
下面介绍hash_table具体实现步骤
2.1 构造与析构
先看第一个,globalConstruct.h构造函数文件
/*******************************************************************
* Copyright(c) 2016 Chen Gonghao
* All rights reserved.
*
* chengonghao@yeah.net
*
* 功能:全局构造和析构的实现代码
******************************************************************/
#include "stdafx.h"
#include <new.h>
#include <type_traits>
#ifndef _CGH_GLOBAL_CONSTRUCT_
#define _CGH_GLOBAL_CONSTRUCT_
namespace CGH
{
#pragma region 统一的构造析构函数
template<class T1, class T2>
inline void construct(T1* p, const T2& value)
{
new (p)T1(value);
}
template<class T>
inline void destroy(T* pointer)
{
pointer->~T();
}
template<class ForwardIterator>
inline void destroy(ForwardIterator first, ForwardIterator last)
{
// 本来在这里要使用特性萃取机(traits编程技巧)判断元素是否为non-trivial
// non-trivial的元素可以直接释放内存
// trivial的元素要做调用析构函数,然后释放内存
for (; first < last; ++first)
destroy(&*first);
}
#pragma endregion
}
#endif按照STL的接口规范,正确的顺序是先分配内存然后构造元素。构造函数的实现采用placement new的方式;为了简化起见,我直接调用析构函数来销毁元素,而在考虑效率的情况下一般会先判断元素是否为non-trivial类型。
关于 trivial 和 non-trivial 的含义,参见:stack overflow
2.2 空间配置器
cghAlloc.h是空间配置器文件,空间配置器负责内存的申请和回收。
/*******************************************************************
* Copyright(c) 2016 Chen Gonghao
* All rights reserved.
*
* chengonghao@yeah.net
*
* 功能:cghAllocator空间配置器的实现代码
******************************************************************/
#ifndef _CGH_ALLOC_
#define _CGH_ALLOC_
#include <new>
#include <cstddef>
#include <cstdlib>
#include <climits>
#include <iostream>
namespace CGH
{
#pragma region 内存分配和释放函数、元素的构造和析构函数
// 内存分配
template<class T>
inline T* _allocate(ptrdiff_t size, T*)
{
set_new_handler(0);
T* tmp = (T*)(::operator new((size_t)(size * sizeof(T))));
if (tmp == 0)
{
std::cerr << "out of memory" << std::endl;
exit(1);
}
return tmp;
}
// 内存释放
template<class T>
inline void _deallocate(T* buffer)
{
::operator delete(buffer);
}
// 元素构造
template<class T1, class T2>
inline void _construct(T1* p, const T2& value)
{
new(p)T1(value);
}
// 元素析构
template<class T>
inline void _destroy(T* ptr)
{
ptr->~T();
}
#pragma endregion
#pragma region cghAllocator空间配置器的实现
template<class T>
class cghAllocator
{
public:
typedef T value_type;
typedef T* pointer;
typedef const T* const_pointer;
typedef T& reference;
typedef const T& const_reference;
typedef size_t size_type;
typedef ptrdiff_t difference_type;
template<class U>
struct rebind
{
typedef cghAllocator<U> other;
};
static pointer allocate(size_type n, const void* hint = 0)
{
return _allocate((difference_type)n, (pointer)0);
}
static void deallocate(pointer p, size_type n)
{
_deallocate(p);
}
static void deallocate(void* p)
{
_deallocate(p);
}
void construct(pointer p, const T& value)
{
_construct(p, value);
}
void destroy(pointer p)
{
_destroy(p);
}
pointer address(reference x)
{
return (pointer)&x;
}
const_pointer const_address(const_reference x)
{
return (const_pointer)&x;
}
size_type max_size() const
{
return size_type(UINT_MAX / sizeof(T));
}
};
#pragma endregion
#pragma region 封装STL标准的空间配置器接口
template<class T, class Alloc = cghAllocator<T>>
class simple_alloc
{
public:
static T* allocate(size_t n)
{
return 0 == n ? 0 : (T*)Alloc::allocate(n*sizeof(T));
}
static T* allocate(void)
{
return (T*)Alloc::allocate(sizeof(T));
}
static void deallocate(T* p, size_t n)
{
if (0 != n)Alloc::deallocate(p, n*sizeof(T));
}
static void deallocate(void* p)
{
Alloc::deallocate(p);
}
};
#pragma endregion
}
#endifclasscghAllocator是空间配置器类的定义,主要的四个函数的意义如下:allocate函数分配内存,deallocate函数释放内存,construct构造元素,destroy析构元素。这四个函数最终都是通过调用_allocate、_deallocate、_construct、_destroy这四个内联函数实现功能。
我们自己写的空间配置器必须封装一层STL的标准接口,
template<classT, class Alloc = cghAllocator<T>>
classsimple_alloc
2.3 vector的实现
根据开链法的设计思路,hash_table的底层容器是vector,vector的设计方法在本博客的讨论范围内,感兴趣的童鞋请移步:STL简单vector的实现
2.4 hash_table节点的实现
hash_table的底层容器是vector,所谓hash_table的节点,指的就是vector的元素。根据开链法的设计思路,vector的每个元素是list(链表)的头节点,由list的头节点串出一条链表,所以说,实现hash_table的节点也就是实现list节点。
List节点的实现很简单,相信童鞋们见过多次了,直接给出代码。
hash_table_node.h
/*******************************************************************
* Copyright(c) 2016 Chen Gonghao
* All rights reserved.
*
* chengonghao@yeah.net
*
* 内容:cgh_hash_table的节点
******************************************************************/
#ifndef _CGH_HASH_TABLE_NODE_
#define _CGH_HASH_TABLE_NODE_
namespace CGH{
template<class value>
struct hash_table_node{
hash_table_node* next; // 指向下一个节点
value val; // 节点的值域
};
}
#endif
2.5 hash_table迭代器的实现
迭代器的内部结构可以分为以下部分:
1. 一堆typedef,成员变量的定义;
2. 迭代器的构造与析构函数;
3. 迭代器的一般操作,注意,hash_table的迭代器没有后退操作。
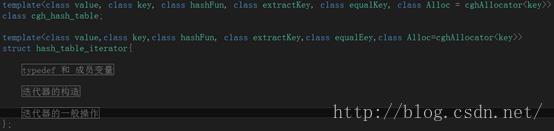
迭代器的代码注释已经写得很详细了,童鞋们可以参考迭代器的内部结构来总体把握迭代器的框架,通过注释来理解迭代器的工作原理。
hash_table_iterator.h
/*******************************************************************
* Copyright(c) 2016 Chen Gonghao
* All rights reserved.
*
* chengonghao@yeah.net
*
* 内容:cgh_hash_table的迭代器
******************************************************************/
#ifndef _CGH_HASH_TABLE_ITERATOR_
#define _CGH_HASH_TABLE_ITERATOR_
#include "globalConstruct.h"
#include "cghAlloc.h"
#include "hash_table_node.h"
#include "cgh_hash_table.h"
#include <memory>
using namespace::std;
namespace CGH{
/*
迭代器中用到了cgh_hash_table,除了#include "hash_table.h"以外,我们要在这里声明一下cgh_hash_table
不然的话,在hash_table_iterator中
typedef cgh_hash_table<value, key, hashFun, extractKey, equalEey, Alloc> cgh_hash_table;
报错:error C2143: 语法错误 : 缺少“;”(在“<”的前面)
*/
template<class value, class key, class hashFun, class extractKey, class equalKey, class Alloc = cghAllocator<key>>
class cgh_hash_table;
template<class value,class key,class hashFun, class extractKey,class equalEey,class Alloc=cghAllocator<key>>
struct hash_table_iterator{
#pragma region typedef 和 成员变量
typedef hash_table_iterator<value, key, hashFun, extractKey, equalEey, Alloc> iterator; // 声明迭代器
typedef hash_table_node<value> node; // 声明节点
typedef cgh_hash_table<value, key, hashFun, extractKey, equalEey, Alloc> cgh_hash_table; // 声明hash_table
/* hash_table的迭代器没有后退操作,只能前进 */
typedef std::forward_iterator_tag iterator_category;
typedef value value_type; // 声明实值类型
typedef ptrdiff_t difference_type; // 表示两迭代器之前的距离
typedef size_t size_type;
typedef value& reference; // 声明引用类型
typedef value* pointer; // 声明指针类型
node* cur; // 节点和迭代器联系的纽带
cgh_hash_table* ht; // 迭代器和cgh_hash_table联系的纽带
#pragma endregion
#pragma region 迭代器的构造
hash_table_iterator(node* n, cgh_hash_table* tab) :cur(n), ht(tab){}
hash_table_iterator(){}
#pragma endregion
#pragma region 迭代器的一般操作
/* 解除引用,返回节点实值 */
reference operator*()const { return cur->val; }
/* 解除引用 */
pointer operator->()const{ return &(operator*()); }
/* 步进(注意,cgh_hash_table的迭代器只能前进)*/
iterator& operator++()
{
const node* old = cur; // 保存迭代器当前位置
// 由于节点被安置在list内,所以利用next指针可以轻易进行前进操作
cur = cur->next;
// 如果前进一个步长之后来到list尾部,我们就要跳到下一个bucket上
if (!cur)
{
size_type bucket = ht->bkt_num(old->val); // 获得当前bucket的位置
// ++bucket:来到下一个bucket
// cur = ht->buckets[bucket]:下一个bucket保存的list的头节点,如果cur == NULL
// 说明下一个bucket为空,继续while循环,直到找到一个不为空的bucket
while (!cur && ++bucket < ht->buckets.size())
{
cur = ht->buckets[bucket];
}
return *this;
}
}
/* 步进(注意,cgh_hash_table的迭代器只能前进)*/
iterator& operator++(int)
{
iterator tmp = *this;
++*this;
return tmp;
}
#pragma endregion
};
}
#endif
2.6 hash_table的实现
有了hash_table的节点和迭代器,接下来我们就要开始设计hash_table啦~
hash的内部结构可以分为以下部分:
1. 一堆typedef,成员变量的定义;
2. hash_table的构造与析构函数;
3. 提供给用户的api,提供对hash_table的读写操作;
4. 给定键值,计算bucket。也就是给定key值,根据hash faction计算出存放地址;
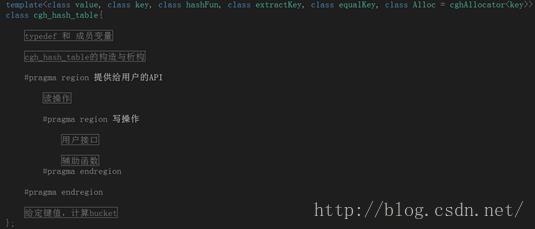
hash_table的代码注释已经写得很详细了,童鞋们可以参考hash_table的内部结构来总体把握hash_table的框架,通过注释来理解hash_table的工作原理。
cgh_hash_table.h
/*******************************************************************
* Copyright(c) 2016 Chen Gonghao
* All rights reserved.
*
* chengonghao@yeah.net
*
* 内容:cgh_hash_table的实现
******************************************************************/
#ifndef _CGH_HASH_TABLE_
#define _CGH_HASH_TABLE_
#include "globalConstruct.h" // 全局构造与析构函数
#include "cghAlloc.h" // 空间配置器
#include "hash_table_node.h"
#include "hash_table_iterator.h"
#include "cghVector.h" // vector
#include "cghUtil.h" // 工具类
#include <algorithm> // 需要用到算法
namespace CGH{
/*
value: 节点的实值类型
key: 节点的键值类型
hashFun: hash faction的函数类型
extractKey:从节点中取出键值的方法
equalKey: 判断键值是否相同的方法
Alloc: 空间配置器
*/
template<class value, class key, class hashFun, class extractKey, class equalKey, class Alloc = cghAllocator<key>>
class cgh_hash_table{
#pragma region typedef 和 成员变量
public:
typedef hashFun hasher;
typedef equalKey key_equal;
typedef size_t size_type;
typedef value value_type; // 实值类型
typedef key key_type; // 键值类型
typedef hash_table_iterator<value, key, hasher, extractKey, equalKey, Alloc> iterator; // 迭代器
private:
hasher hash; // hash faction
key_equal equals; // 判断键值是否相同的方法
extractKey get_key; // 从节点中取出键值的方法
typedef hash_table_node<value> node; // 节点
typedef simple_alloc<node, Alloc> node_allocator; // 空间配置器
public:
size_type num_elements; // hash_table中有效的节点个数
cghVector<node*, Alloc> buckets; // 用cghVector作为bucket的底层实现
#pragma endregion
#pragma region cgh_hash_table的构造与析构
private:
/* 构造新节点 */
node* new_node(const value_type& obj)
{
node* n = node_allocator::allocate(); // 空间配置器分配节点空间
n->next = 0; // 初始化节点的next指针指向NULL
construct(&n->val, obj); // 全局构造函数,初始化节点实值
return n; // 返回新节点的指针
}
/* 销毁节点 */
void delete_node(node* n)
{
destroy(&n->val); // 全局析构函数,销毁节点实值
node_allocator::deallocate(n); // 释还节点内存
}
/*
我们以质数来设计表格大小,将28个质数(逐渐呈现大约两倍的关系)计算好
__stl_next_prime函数用于查询这28个质数中,“最接近某数并大于某数”的质数
__stl_num_primes = 28; // 表示28个质数
__stl_prime_list:指数数组,定义在本文件的末尾
*/
inline unsigned long __stl_next_prime(unsigned long n)
{
const unsigned long* first = __stl_prime_list; // 指向数组头部的指针
const unsigned long* last = __stl_prime_list + __stl_num_primes; // 指向数组尾部的指针
// 这里用到了标准库的lower_bound算法,对质数数组(__stl_prime_list)排序(从小到大)
const unsigned long* pos = std::lower_bound(first, last, n);
return pos == last ? *(last - 1) : *pos;
}
/* 根据n值,返回合适的buckets大小 */
size_type next_size(size_type n){ return __stl_next_prime(n); }
/* 初始化buckets,buckets的每个节点对应一个list链表,链表的节点类型是hash_table_node */
void initialize_buckets(size_type n)
{
const size_type n_buckets = next_size(n); // 取得初始化的buckets的元素个数
buckets.insert(buckets.end(), n_buckets, 0); // 每个元素对应的list链表初始化为空
}
public:
/* cgh_hash_table的构造函数 */
cgh_hash_table(size_type n, const hashFun& hf, const equalKey& eql)
:hash(hf), equals(eql), get_key(extractKey()), num_elements(0)
{
initialize_buckets(n);
}
#pragma endregion
#pragma region 提供给用户的API
#pragma region 读操作
public:
/* 返回当前bucket的总数 */
size_type bucket_count(){ return buckets.size(); }
/* 最大bucket数 */
size_type max_bucket_count()const{ return __stl_prime_list[__stl_num_primes - 1]; }
/* 返回当前cgh_hash_table中有效节点的个数 */
size_type size()const{ return num_elements; }
/* 返回迭代器,指向第一个节点 */
iterator begin()
{
///找到第一个非空的桶,得到其第一个元素
for (size_type n = 0; n < buckets.size(); ++n)
{
if (buckets[n])
{
return iterator(buckets[n], this);
}
}
return end(); // 如果cgh_hash_table为空,返回尾部
}
/* 返回迭代器,指向第一个节点 */
iterator end() { return iterator(0, this); }
/* 返回指定bucket中装的节点个数,节点类型为hash_table_node */
size_type elems_in_bucket(size_type num)
{
size_type result = 0;
node* cur = buckets[num];
for (node* cur = buckets[num]; cur; cur = cur->next)
{
result += 1;
}
return result;
}
/* 输入键值,返回一个迭代器,指向键值对应的节点 */
iterator find(const key_type& key)
{
size_type n = bkt_num(key); // 计算键值落在哪个bucket里面
node* first; // 指向bucket的第一个节点
// 逐一比较bucket对应的list的每个节点的键值
for (first = buckets[n]; first && !equals(get_key(first->val), key); first = first->next){}
return iterator(first, this);
}
/* 返回键值为key的节点个数 */
size_type count(const key_type& key)
{
size_type n = bkt_num(key); // 确定key落在哪个bucket里
size_type result = 0;
// 遍历bucket对应的list的每个节点
for (const node* cur = buckets[n]; cur; cur = cur->next)
{
if (equals(get_key(cur->val), key)) // 如果节点键值等于key
{
++result;
}
}
return result;
}
#pragma endregion
#pragma region 写操作
#pragma region 用户接口
public:
/* 插入元素,不允许键值重复 */
cghPair<iterator, bool> insert_unique(const value_type& obj)
{
resize(num_elements + 1); // 判断是否需要重建表格
return insert_unique_noresize(obj); // 调用辅助函数
}
/* 插入元素,允许键值重复 */
iterator insert_equal(const value_type& obj)
{
resize(num_elements + 1); // 判断是否需要重建表格
return insert_equal_noresize(obj); // 调用辅助函数
}
#pragma endregion
#pragma region 辅助函数
private:
/* 是否需要重建表格 */
void resize(size_type num_elements_hint)
{
/*
判断重建表格的原则:
比较元素个数(计入新增元素)和bucket vector的大小
元素个数 > bucket vector的大小 => 重建表格
由此可知,每个bucket(list)的最大容量和bucket vector的大小相同
是一个 n * n 的矩阵
*/
const size_type old_n = buckets.size(); // 获得bucket vector的大小
if (num_elements_hint > old_n) // 如果 元素个数 > bucket vector的大小,我们就要重建表格
{
// 找出下一个质数,也就是待重建的表格大小
const size_type n = next_size(num_elements_hint);
if (n > old_n)
{
cghVector<node*, Alloc> tmp(n, (node*)0); // 设立新的buckets
// 处理每一个旧的bucket
for (size_type bucket = 0; bucket < old_n; ++bucket)
{
node* first = buckets[bucket];// 旧的buckets中,每个元素(bucket)指向的list起点
while (first) // 循环遍历list
{
size_type new_bucket = bkt_num(first->val, n); // 找出节点落在哪一个新bucket内
buckets[bucket] = first->next; // 1.令就bucket指向其所对应的list的下一个节点
first->next = tmp[new_bucket]; //2、3.将当前节点插入到新bucket内,成为其list的第一个节点
tmp[new_bucket] = first;
first = buckets[bucket]; // 4.回到就bucket所指向的list,准备处理下一个节点
}
}
buckets.swap(tmp); // 交换新旧buckets
} // 离开时,tmp被释放
}
}
/* 不允许键值重复的插入 */
cghPair<iterator, bool> insert_unique_noresize(const value_type& obj)
{
const size_type n = bkt_num(obj); // 根据键值决定落在哪个bucket中
node* first = buckets[n]; // 令first指向bucket对应的list
for (node* cur = first; cur; cur = cur->next) // 遍历list
{
if (equals(get_key(cur->val), get_key(obj))) // 如果发现键值重复
{
return cghPair<iterator, bool>(iterator(cur, this), false); // 返回插入失败
}
}
node* tmp = new_node(obj); // 创建新节点
tmp->next = first; // 头插法:插入新节点到list头部
buckets[n] = tmp;
++num_elements; // 节点数加1
return cghPair<iterator, bool>(iterator(tmp, this), true); // 返回结果
}
/* 允许键值重复的插入 */
iterator insert_equal_noresize(const value_type& obj)
{
const size_type n = bkt_num(obj); // 根据键值决定落在哪个bucket中
node* first = buckets[n]; // 令first指向bucket对应的list
for (node* cur = first; cur; cur = cur->next) // 遍历list
{
if (equals(get_key(cur->val), get_key(obj))) // 如果发现键值重复
{
node* tmp = new_node(obj); // 创建新节点
tmp->next = cur->next; // 头插法:插入新节点到cur的前面
cur->next = tmp;
++num_elements; // 节点数加1
return iterator(tmp, this); // 返回结果
}
}
node* tmp = new_node(obj); // 创建新节点
tmp->next = first; // 头插法:插入新节点到first的前面
buckets[n] = tmp;
++num_elements; // 节点数加1
return iterator(tmp, this); // 返回结果
}
#pragma endregion
#pragma endregion
#pragma endregion
#pragma region 给定键值,计算bucket
/*
对于hash_table而言,最重要的就是确定key对应的bucket,这是hash faction的责任
我们把hash faction封装一层,由下面四个函数调用hash faction
*/
public:
/* 接受实值和buckets个数 */
size_type bkt_num(const value_type& obj, size_type n)
{
return bkt_num_key(get_key(obj), n);
}
/* 只接受实值 */
size_type bkt_num(const value_type& obj)
{
return bkt_num_key(get_key(obj));
}
/* 只接受键值 */
size_type bkt_num_key(const key_type& key)
{
return bkt_num_key(key, buckets.size());
}
/* 接受键值和buckets个数 */
size_type bkt_num_key(const key_type& key, size_type n)
{
return hash(key) % n; // 调用hash faction,返回bucket
}
#pragma endregion
};
static const int __stl_num_primes = 28;
static const unsigned long __stl_prime_list[__stl_num_primes] =
{
53, 97, 193, 389, 769,
1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433,
1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457,
1610612741, 3221225473ul, 4294967291ul
};
}
#endif
3. 测试
测试环节的主要内容已在注释中说明
test_cgh_hash_table.cpp
/*******************************************************************
* Copyright(c) 2016 Chen Gonghao
* All rights reserved.
*
* chengonghao@yeah.net
*
* 文件内容:cgh_hash_table的测试
******************************************************************/
#include "stdafx.h"
#include "cgh_hash_table.h"
using namespace::std;
int _tmain(int argc, _TCHAR* argv[])
{
using namespace::CGH;
cgh_hash_table<int, int, std::hash<int>, std::identity<int>, std::equal_to<int>> test(50, std::hash<int>(), std::equal_to<int>());
std::cout << "**************** unique(不允许键值重复)插入测试 ****************" << endl << endl;
std::cout << "依次插入:59,63,108,2,53,55" << endl << endl;
test.insert_unique(59);
test.insert_unique(63);
test.insert_unique(108);
test.insert_unique(2);
test.insert_unique(53);
test.insert_unique(55);
std::cout << "遍历cgh_hash_table,打印插入结果:";
cgh_hash_table<int, int, std::hash<int>, std::identity<int>, std::equal_to<int>>::iterator it = test.begin();
cgh_hash_table<int, int, std::hash<int>, std::identity<int>, std::equal_to<int>>::iterator it2 = test.end();
for (int i = 0; i < test.size(); ++i, ++it)
{
cout << *it << ",";
}
std::cout << endl << endl << "遍历cgh_hash_table的所有bucket,如果节点个数不为0,就打印节点个数:" << endl << endl;
for (int i = 0; i < test.bucket_count(); ++i)
{
int n = test.elems_in_bucket(i);
if (n != 0)
{
cout << "bucket[" << i << "] 有 " << n << " 个节点" << endl;
}
}
cout << endl << "cgh_hash_table的节点个数:" << test.size() << endl;
cout << endl << "cgh_hash_table的bucket个数:" << test.bucket_count() << endl;
cout << "-----------------------------" << endl << endl << endl;
std::cout << "**************** equal(允许键值重复)插入测试 ****************" << endl << endl;
std::cout << "在unique插入测试的基础上,继续插入:1,2,3,...,46,47" << endl << endl;
for (int i = 0; i <= 47; ++i)
{
test.insert_equal(i);
}
std::cout << "遍历cgh_hash_table,打印插入结果:" << endl << endl;
it = test.begin();
for (int i = 0; i < test.size(); ++i, ++it)
{
cout << *it << " ";
if (i % 15 == 0 && i != 0)
{
cout << endl;
}
}
cout << endl << endl << "cgh_hash_table的节点个数:" << test.size() << endl;
cout << endl << "cgh_hash_table的bucket个数:" << test.bucket_count() << endl;
std::cout << endl << endl << "遍历cgh_hash_table的所有bucket,如果节点个数不为0,就打印节点个数:" << endl << endl;
for (int i = 0; i < test.bucket_count(); ++i)
{
int n = test.elems_in_bucket(i);
if (n != 0)
{
cout << "bucket[" << i << "] 有 " << n << " 个节点" << endl;
}
}
cout << "-----------------------------" << endl << endl << endl;
system("pause");
return 0;
}
结果如下所示:
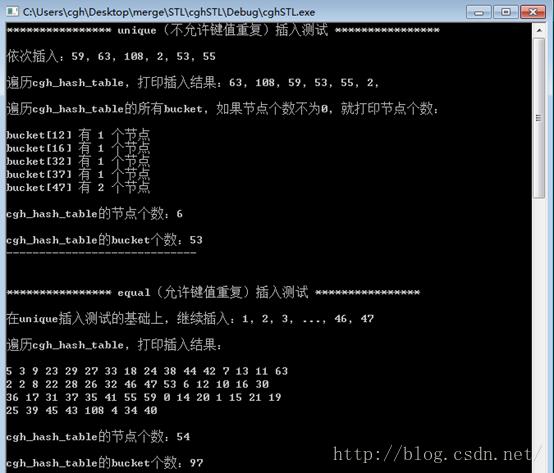
可以看到,hash_table的插入非常均匀。
4.扩展讨论-- Hash与Map的区别
STL中的set和map采用红黑树的方式组织数据;hash_table采用散列的方法组织数据。
Set/map与hash_table各自的优势和应用场景有哪些呢?

有序性:采用红黑树,我们可以方便的得到最小值(向左走到底)和最大值(向右走到底),中序遍历红黑树可以得到key值由小到大的排列;而hash呈散列状,是一种无序状态,要获得最大最小值,或者按key值从小到大排列,我们需要做很多额外工作。
在实际的系统中,例如,需要使用动态规则的防火墙系统,使用红黑树而不是散列表被实践证明具有更好的伸缩性。Linux内核在管理vm_area_struct时就是采用了红黑树来维护内存块的。
如果只需要判断某个值是否存在之类的操作,当然是Hash实现的要更加高效。
如果是需要将两组数据求并集交集差集等大量比较操作,就是map/set更加高效。
以上是关于STL简单hashtable的实现的主要内容,如果未能解决你的问题,请参考以下文章