二叉排序树(BST)的思路及C语言实现
Posted kelvinmao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了二叉排序树(BST)的思路及C语言实现相关的知识,希望对你有一定的参考价值。
请注意,为了能够更好的理解二叉排序树,我建议各位在看代码时能够设置好断点一步一步跟踪函数的运行过程以及各个变量的变化情况
一.动态查找所面临的问题
在进行动态查找操作时,如果我们是在一个无序的线性表中进行查找,在插入时可以将其插入表尾,表长加1即可;删除时,可以将待删除元素与表尾元素做个交换,表长减1即可。反正是无序的,当然是怎么高效怎么操作。但如果是有序的呢?回想学习线性表顺序存储时介绍的顺序表的缺点,就在于插入删除操作的复杂与低效。
正因为如此,我们引入了链式存储结构,似乎这样就能解决上面遇到的问题了。但细想一下,我们要进行的是查找操作,而链式结构的好处在于插入删除,但在查找方面则显得无能为力。那么有没有一种结构能让我们既提高查找的效率,又不影响插入删除的效率呢?
二.如何解决上述问题
先从最简单的情况考虑,我们现在有一个只有一个数据元素的集合,假设为{20},现在我需要查找其中是否含有’56’这个数字,没有则插入;那么很显然执行该操作后集合变成了{20,56},继续查找集合中是否有’16’这个元素,没有则插入并且不改变原先的有序性。似乎要插入新数据就必须做移动。有没有办法不移动呢?有人想到了用二叉树来存储数据,让20做根节点,56比20大所以做右子树,16比20小所以做左子树,这样不就不用移动其位置了吗?思路见下图
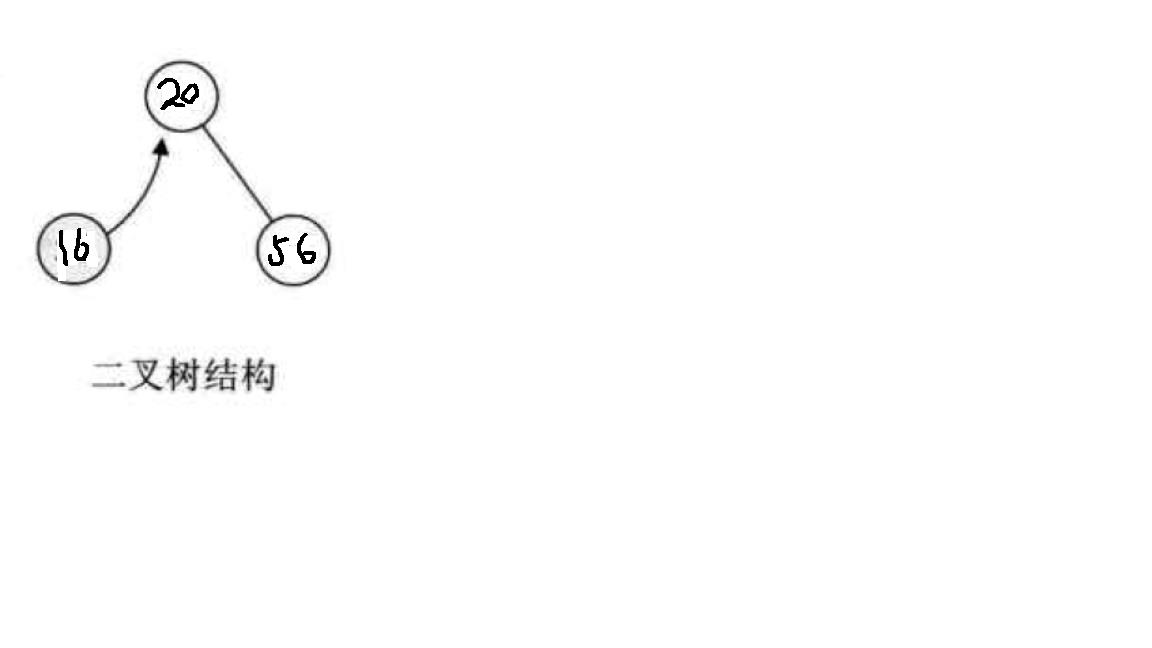
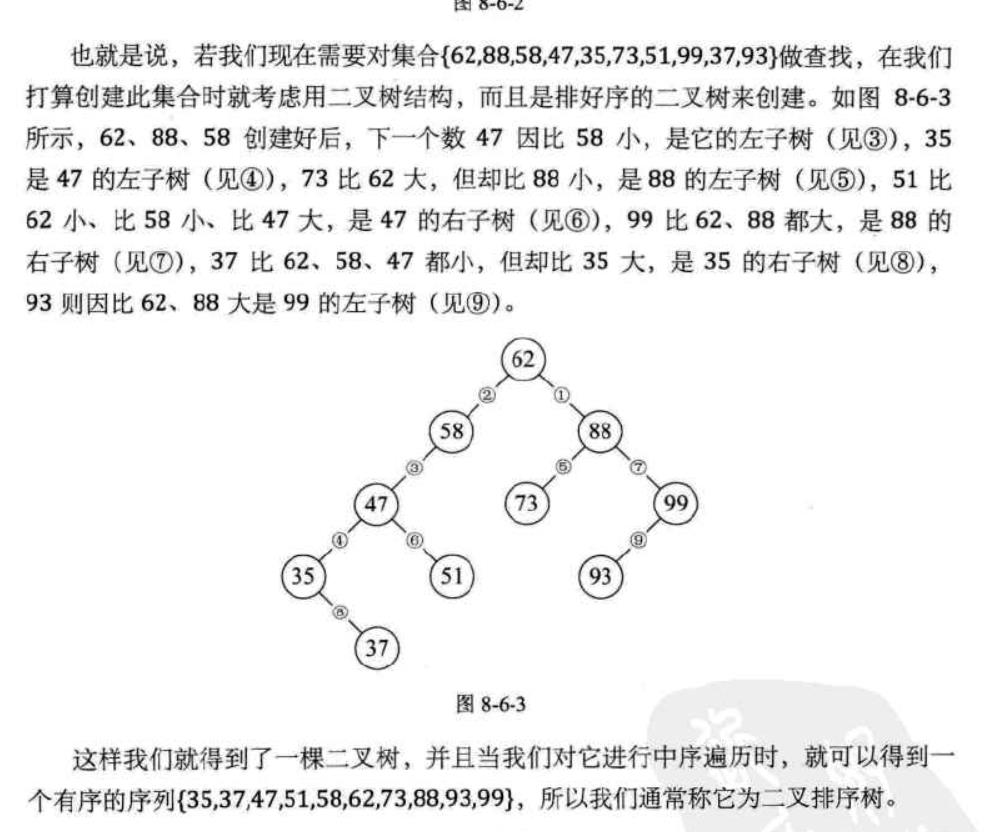
三.二叉排序树(又称二叉搜索树)
1.定义
二叉排序树或者是一棵空树,或者是一棵有下列性质的二叉树:
1.若它的左子树不为空,则它左子树上所有结点的值必然小于根结点的值
2.若它的右子树不为空,则它右子树上所有结点的值必然大于根结点的值
3.它的左右子树也为二叉排序树
之所以要构造这样一棵树,不是为了排序,而是为了提高查找,插入和删除的效率
2.构建一棵二叉排序树
要构建一棵二叉排序树并实现相关操作,首先应理解下列的三个操作
1.查找操作:
给定key值,首先将其与根节点比较,相等则返回根结点,否则将其与根结点值进行比较,小于根结点则在左子树中递归查找;大于根结点则在右子树中递归查找,代码如下:
/*在BST中查找值为key的元素,f为指向双亲的指针,p用来返回查找路径上最后一个结点*/
Status SearchBST(BiTree T,int key,BiTree f,BiTree *p){
if(!T){
*p=f;
return ERROR;
}
if(T->data==key){
*p=T;
return OK;
}
else{
/*如果key值小于当前值,则进入左子树中查找*/
if(key<T->data)
return SearchBST(T->Lchild,key,T,p);/*注意这里,递归调用的时候其双亲结点f应该为T*/
else
return SearchBST(T->Rchild,key,T,p);
}
}2.插入操作
要进行插入,首先要在BST中进行查找,若key值已经存在,则应返回ERROR;不存在时,由于第一步的search操作已经返回了查找路径上的最后一个结点,只需要把key值与最后一个节点的值进行比较,比它小则为左子树,反之为右子树,代码如下:
/*查找key是否存在于BST中,如果不存在,则插入key到合适位置*/
Status InsertBST(BiTree *T,int key){
/*found用于返回其查找过程中最后一个结点,insert为指向待插入结点的指针*/
BiTree found=NULL,insert=NULL;
/*没找到*/
if(!SearchBST(*T,key,NULL,&found)){
insert=(BiTree)malloc(sizeof(BiTreeNode));
if(!insert){
printf("malloc failed\\n");
return ERROR;
}
insert->data=key;
insert->Lchild=NULL;
insert->Rchild=NULL;
// if(*T==found)
/*如果found空,说明根节点值应为key*/
if(!found)
*T=insert;
else{
/*key值小于上一节点的data时,做左子树*/
if(key<found->data)
found->Lchild=insert;
if(key>found->data)
found->Rchild=insert;
}
}
/*如果找到了,返回ERROR*/
else
return ERROR;
}3.删除操作
由于二叉排序树具有比二叉树更多的特性,所以删除操作就变得更复杂,不能因为删除一个结点导致整棵树不满足BST的性质。所以应该分三种情况进行讨论:
1.删除的是叶子节点
2.删除的是只有左子树或右子树的节点
3.删除的结点既有左子树也有右子树
对于第一种情况,直接删除即可,叶子结点对整棵树的性质并没有影响
对于第二种情况,只有左或右子树,只需要让待删除结点的指针指向其子树即可,同时释放原根结点指针即可
对于既有左子树又有右子树的情况,就比较复杂了,如图所示:要删除下图中的值为47的节点,并且还要保持其是一棵BST,如何解决呢?
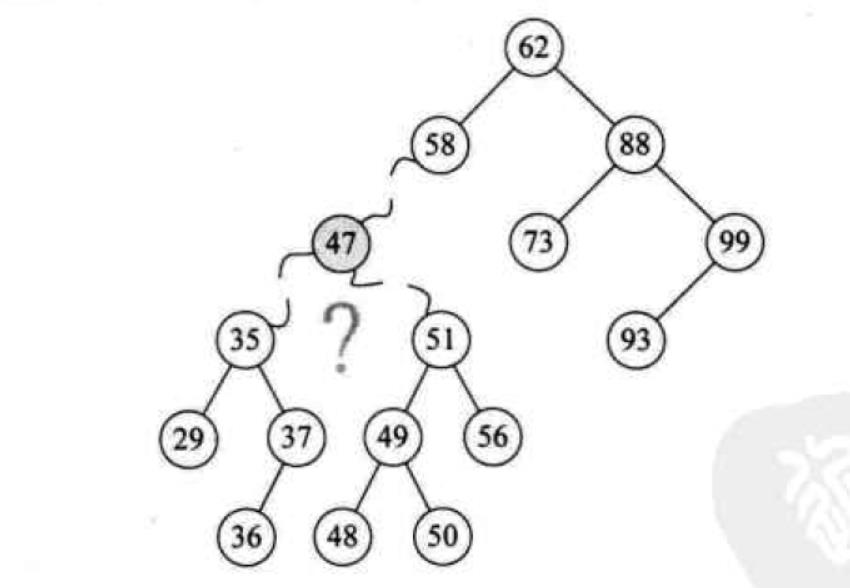
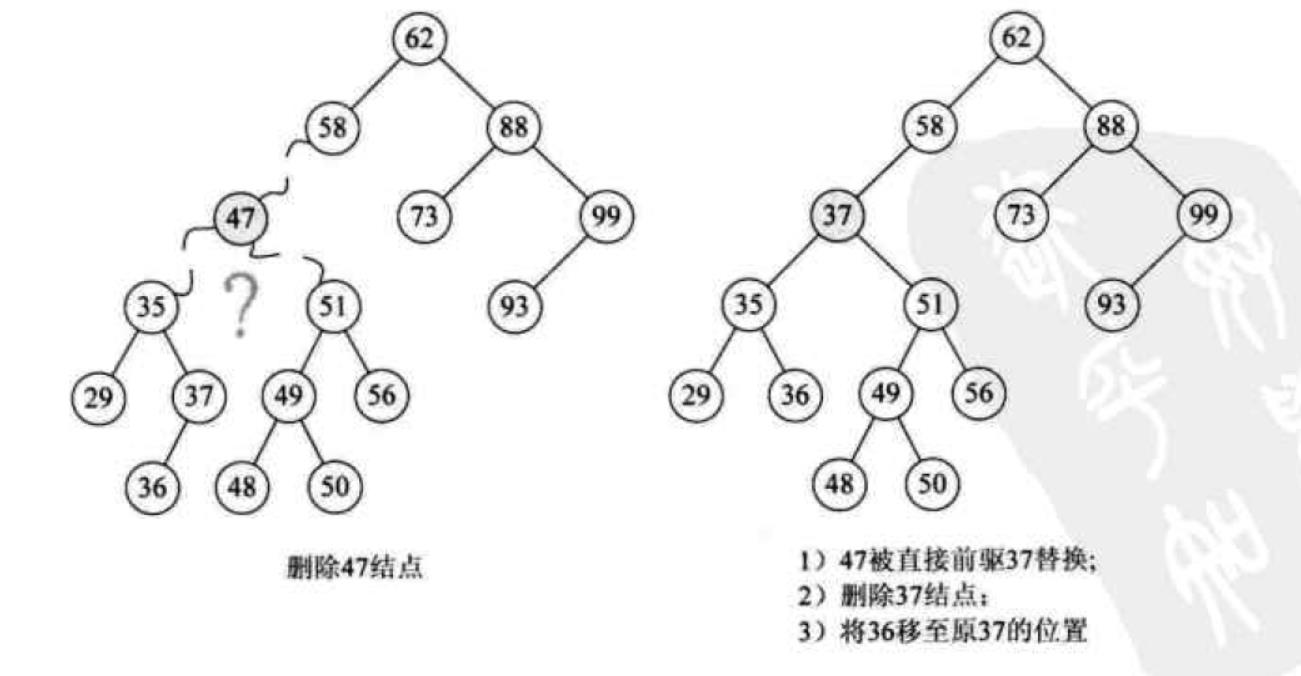
我们当然可以删除47之后再把其子结点上的值插入回原先的BST中,但是这样做效率十分低下而且会改变二叉树的深度,我们换个角度考虑,在47的子结点中有没有哪个值可以代替47的位置呢?寻找一番之后发现37和48好像没问题,进一步思考,37和48能够替代47的原因在于:当我们中序遍历以47为根的二叉树时,37和48是47的直接前驱和后继。这样我们就得到了一个结论,删除操作时,待删除结点在中序遍历的直接前驱或后继可以替代其位置。配图一张说明思路:
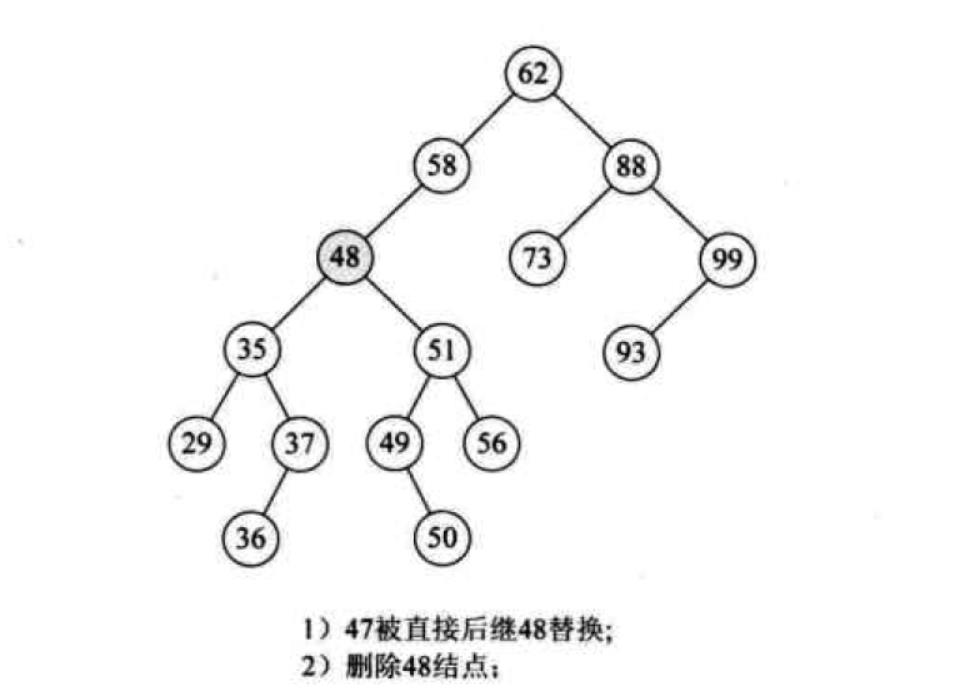
看了图片可能觉得思路清晰一些了,下面看代码吧:
/*删除BST中某一结点,并重接其左右子树*/
Status Delete(BiTree *T){
BiTree qmove=NULL,smove=NULL;
if(!(*T))
return ERROR;
/*如果只有右子树*/
if((*T)->Lchild==NULL){
qmove=*T;/*用qmove保存待删除结点*/
(*T)=(*T)->Rchild;/*待删除结点指向其右子树*/
free(qmove);
}
/*这里要注意一定要写成else if,否则会出现错误*/
else if((*T)->Rchild==NULL){
qmove=*T;
(*T)=(*T)->Lchild;
free(qmove);
}
else{
qmove=*T;
/*先左转再右转至指针为空是为了找到其中序遍历的直接前驱*/
smove=(*T)->Lchild;
while(smove->Rchild){
qmove=smove;
smove=smove->Rchild;
}
/*smove指向待删除结点的直接前驱*/
(*T)->data=smove->data;/*首先把smove指向的值赋给待删除结点,下一步要做的是删除smove并且把smove的孩子结点接好*/
if(qmove!=(*T))/*如果qmove不指向待删除结点,则把smove的左子树赋给qmove的右子树*/
qmove->Rchild=smove->Lchild;
else
qmove->Lchild=smove->Lchild;/*否则把smove的左子树赋给qmove的左子树*/
free(smove);
}
return OK;
}
/*查找BST中是否存在key,若存在则删除key*/
Status DeleteBST(BiTree *T,int key){
if(!(*T))
return ERROR;
else{
if((*T)->data==key)
Delete(T);
else if(key<(*T)->data)
DeleteBST(&(*T)->Lchild,key);
else if(key>(*T)->data)
DeleteBST(&(*T)->Rchild,key);
}
}
/*此处顺便附上主程序*/
int main(void)
{
int i;
int a[10]={62,88,58,47,35,73,51,99,37,93};
BiTree T=NULL,p;
for(i=0;i<10;i++)
{
InsertBST(&T, a[i]);
}
DeleteBST(&T,93);
DeleteBST(&T,47);
Inorder(T);//中序遍历
// SearchBST(T,35,NULL,&p);
// printf("%d",p->data);
return 0;
}前两种情况比较简单,不再赘述,下面分析第三种情况
第一步:声明两个指针,qmove指向待删除结点,smove指向待删除结点的左子树之后让smove往右子树移动,同时qmove记录smove的位置,这一步是为了找到待删除结点的直接前驱
第二步:将smove的值赋给根节点,如果这时qmove没有指向根结点,则让qmove的右子树指向smove的左子树;否则qmove的左子树指向smove的左子树
第三步,释放smove
下面这组图片展示了这段代码运行时的每一步的状态:
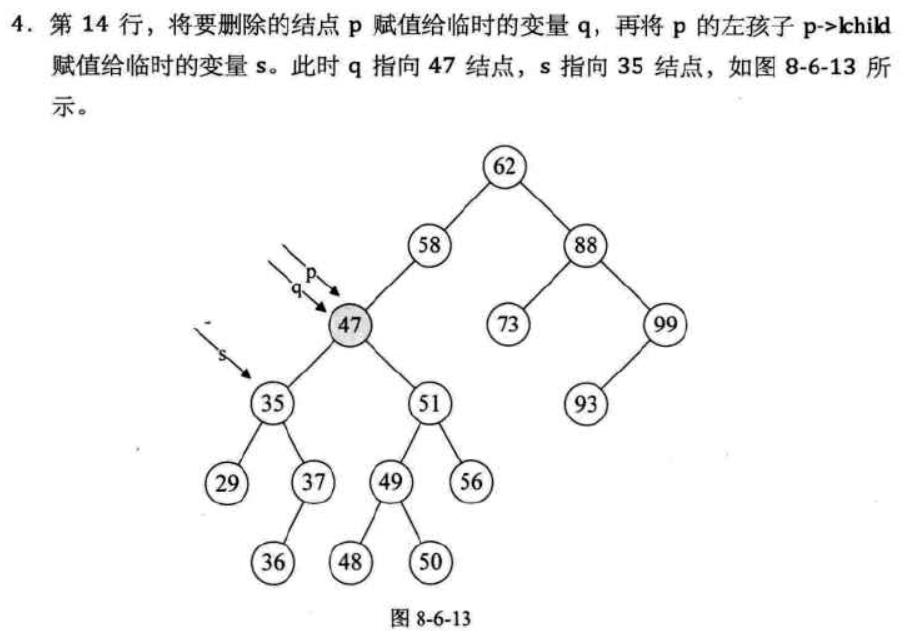
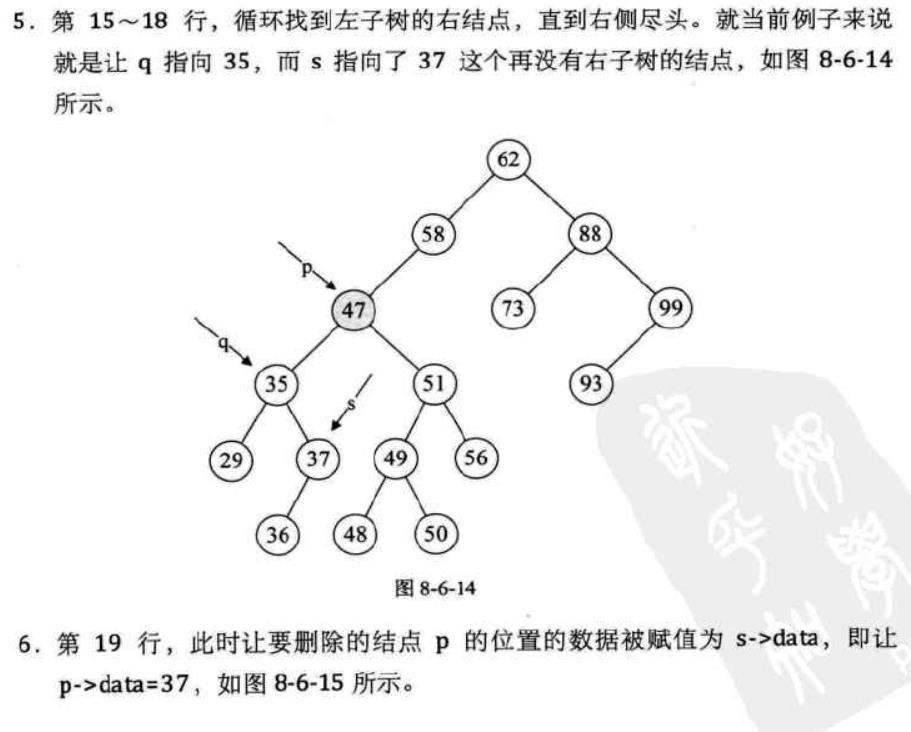
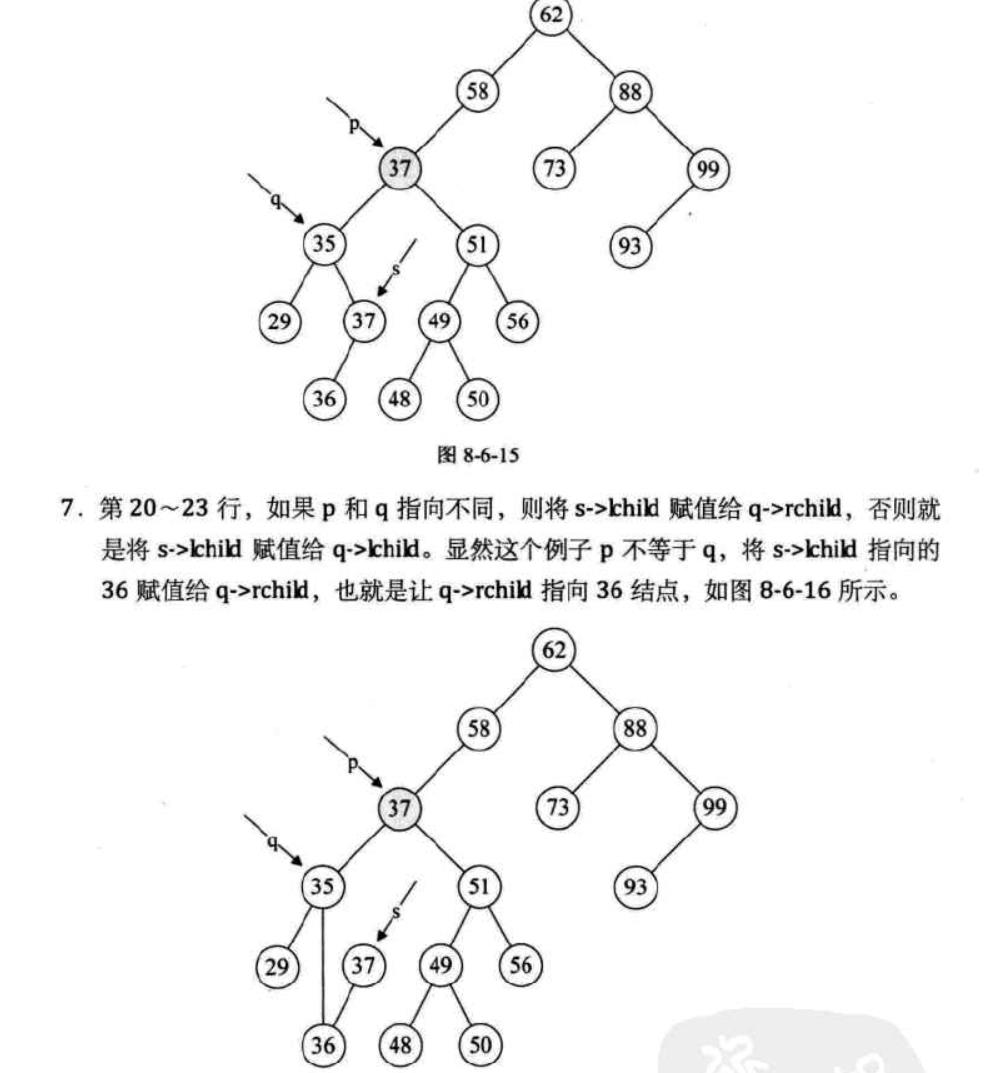
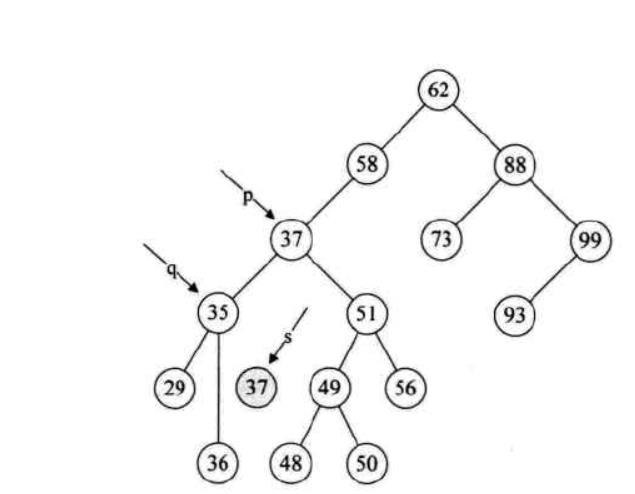
至此,删除操作才算告一段落
四.总结
二叉排序树采用链式存储,有较好的插入删除的时间性能;查找方面,最好情况是1次找到,最差情况也不会超过树的深度。因此,查找方面的性能取决于输的形状,比如有下面这样的两棵树:
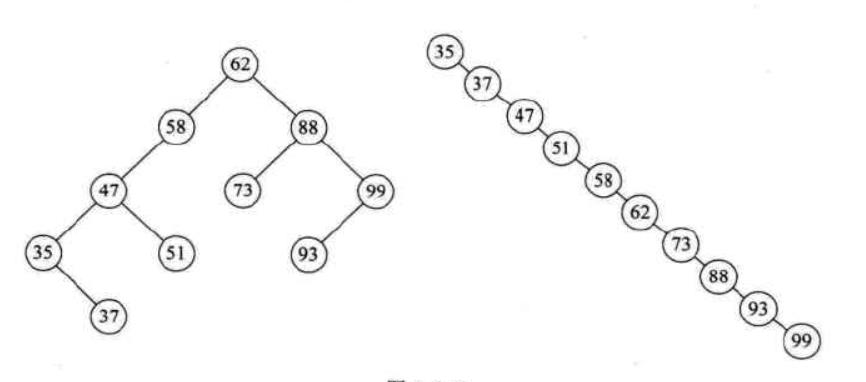
两棵树的数据全部相同,注意右边的树也是二叉排序树,只不过其元素由于是从小到大排列的导致成了一棵右斜树,要查找99这个元素,左边的树只需要两次比较,而右边要 10次比较,差异非常大,已经失去了二叉排序树的意义,因此,如何让二叉树两边变得均衡一些,是我们下一个需要研究的问题。
以上是关于二叉排序树(BST)的思路及C语言实现的主要内容,如果未能解决你的问题,请参考以下文章