平均数编码:针对某个分类特征类别基数特别大的编码方式
Posted wzd321
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了平均数编码:针对某个分类特征类别基数特别大的编码方式相关的知识,希望对你有一定的参考价值。
原文:https://zhuanlan.zhihu.com/p/26308272
插入一条信息:特征编码一定要考虑是否需要距离度量,编码方式对距离度量的适应:例如:我们用one-hot编码颜色,向量正交,各个颜色之间的距离等同,如果此处用序数编码显然不太合适,但是我们用one-hot编码星期几就不好了,显然星期一和星期二的距离小于星期一和星期三的距离。
应用条件:某一个特征是分类的,特征的可能值非常多,那么平均数编码是一种高效的编码方式。
适用问题:平均数编码是一种有监督的编码方式,适用于分类和回归问题。
基本原理:基于分类问题分析
目标y一共有C个不同类别,具体的一个类别用target表示;
某一个定性特征variable一共有K个不同类别,具体的一个类别用k表示;
先验概率:数据点属于某一个target(y)的概率,;
后验概率:该定性特征属于某一类时,数据点属于某一个target(y)的概率,;
算法的基本思想:将variable中的每一个k,都表示为它所对应的目标y值概率:;
因此,整个数据集将增加(C-1)列,是C-1而不是C的原因:,所以最后一个
的概率值必然和其他
的概率值线性相关。在线性模型、神经网络以及SVM里,不能加入线性相关的特征列。如果你使用的是基于决策树的模型(gbdt、rf等),个人仍然不推荐这种over-parameterization;
先验概率与后验概率的计算:
= (y = target)的数量 / y 的总数
= (y = target 并且 variable = k)的数量 / (variable = k)的数量
我们已经得到了先验概率估计和后验概率估计
。最终编码所使用的概率估算,应当是先验概率与后验概率的一个凸组合(convex combination)。由此,我们引入先验概率的权重
来计算编码所用概率
:
直觉上,(贝叶斯统计学中
也被称为shrinkage parameter)应该具有以下特性:
- 如果测试集中出现了新的特征类别(未在训练集中出现),那么
;
- 一个特征类别在训练集内出现的次数越多,后验概率的可信度越高,其权重也越大;
权重函数:
我们需要定义一个权重函数,输入是特征类别在训练集中出现的次数n,输出是对于这个特征类别的先验概率的权重。假设一个特征类别的出现次数为n,以下是一个常见的权重函数:
这个函数有两个参数:
k:当时,
,先验概率与后验概率的权重相同;当
时,
。
f:控制函数在拐点附近的斜率,f越大,“坡”越缓。
图示:k=1时,不同的f对于函数图象的影响。
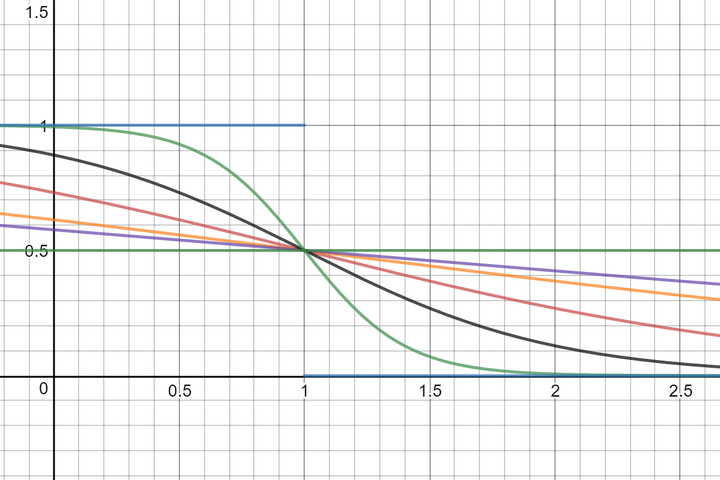
当(n - k) / f太大的时候,np.exp可能会产生overflow的警告。我们不需要管这个警告,因为某一类别的频数极高,分母无限时,最终先验概率的权重将成为0,这也表示我们对于后验概率有充足的信任。
以上的算法设计能解决多个类别的分类问题,自然也能解决更简单的两类分类问题以及回归问题。
还有一种情况:定性特征本身包括了不同级别。例如,国家包含了省,省包含了市,市包含了街区。有些街区可能就包含了大量的数据点,而有些省却可能只有稀少的几个数据点。这时,我们的解决方法是,在empirical bayes里加入不同层次的先验概率估计。
代码实现:
原论文并没有提到,如果fit时使用了全部的数据,transform时也使用了全部数据,那么之后的机器学习模型会产生过拟合。因此,我们需要将数据分层分为n_splits个fold,每一个fold的数据都是利用剩下的(n_splits - 1)个fold得出的统计数据进行转换。n_splits越大,编码的精度越高,但也更消耗内存和运算时间。编码完毕后,是否删除原始特征列,应当具体问题具体分析。
import numpy as np import pandas as pd from sklearn.model_selection import StratifiedKFold from itertools import product class MeanEncoder: def __init__(self, categorical_features, n_splits=5, target_type=‘classification‘, prior_weight_func=None): """ :param categorical_features: list of str, the name of the categorical columns to encode :param n_splits: the number of splits used in mean encoding :param target_type: str, ‘regression‘ or ‘classification‘ :param prior_weight_func: a function that takes in the number of observations, and outputs prior weight when a dict is passed, the default exponential decay function will be used: k: the number of observations needed for the posterior to be weighted equally as the prior f: larger f --> smaller slope """ self.categorical_features = categorical_features self.n_splits = n_splits self.learned_stats = {} if target_type == ‘classification‘: self.target_type = target_type self.target_values = [] else: self.target_type = ‘regression‘ self.target_values = None if isinstance(prior_weight_func, dict): self.prior_weight_func = eval(‘lambda x: 1 / (1 + np.exp((x - k) / f))‘, dict(prior_weight_func, np=np)) elif callable(prior_weight_func): self.prior_weight_func = prior_weight_func else: self.prior_weight_func = lambda x: 1 / (1 + np.exp((x - 2) / 1)) @staticmethod def mean_encode_subroutine(X_train, y_train, X_test, variable, target, prior_weight_func): X_train = X_train[[variable]].copy() X_test = X_test[[variable]].copy() if target is not None: nf_name = ‘{}_pred_{}‘.format(variable, target) X_train[‘pred_temp‘] = (y_train == target).astype(int) #classification else: nf_name = ‘{}_pred‘.format(variable) X_train[‘pred_temp‘] = y_train #regression prior = X_train[‘pred_temp‘].mean() col_avg_y = X_train.groupby(by=variable, axis=0)[‘pred_temp‘].agg({‘mean‘: ‘mean‘, ‘beta‘: ‘size‘}) col_avg_y[‘beta‘] = prior_weight_func(col_avg_y[‘beta‘]) col_avg_y[nf_name] = col_avg_y[‘beta‘] * prior + (1 - col_avg_y[‘beta‘]) * col_avg_y[‘mean‘] col_avg_y.drop([‘beta‘, ‘mean‘], axis=1, inplace=True) nf_train = X_train.join(col_avg_y, on=variable)[nf_name].values nf_test = X_test.join(col_avg_y, on=variable).fillna(prior, inplace=False)[nf_name].values return nf_train, nf_test, prior, col_avg_y def fit_transform(self, X, y): """ :param X: pandas DataFrame, n_samples * n_features :param y: pandas Series or numpy array, n_samples :return X_new: the transformed pandas DataFrame containing mean-encoded categorical features """ X_new = X.copy() if self.target_type == ‘classification‘: skf = StratifiedKFold(self.n_splits) else: skf = KFold(self.n_splits) if self.target_type == ‘classification‘: self.target_values = sorted(set(y)) self.learned_stats = {‘{}_pred_{}‘.format(variable, target): [] for variable, target in product(self.categorical_features, self.target_values)} for variable, target in product(self.categorical_features, self.target_values): nf_name = ‘{}_pred_{}‘.format(variable, target) X_new.loc[:, nf_name] = np.nan for large_ind, small_ind in skf.split(y, y): nf_large, nf_small, prior, col_avg_y = MeanEncoder.mean_encode_subroutine(X_new.iloc[large_ind],y.iloc[large_ind],X_new.iloc[small_ind],variable, target, self.prior_weight_func) X_new.iloc[small_ind, -1] = nf_small self.learned_stats[nf_name].append((prior, col_avg_y)) else: self.learned_stats = {‘{}_pred‘.format(variable): [] for variable in self.categorical_features} for variable in self.categorical_features: nf_name = ‘{}_pred‘.format(variable) X_new.loc[:, nf_name] = np.nan for large_ind, small_ind in skf.split(y, y): nf_large, nf_small, prior, col_avg_y = MeanEncoder.mean_encode_subroutine( X_new.iloc[large_ind], y.iloc[large_ind], X_new.iloc[small_ind], variable, None, self.prior_weight_func) X_new.iloc[small_ind, -1] = nf_small self.learned_stats[nf_name].append((prior, col_avg_y)) return X_new def transform(self, X): """ :param X: pandas DataFrame, n_samples * n_features :return X_new: the transformed pandas DataFrame containing mean-encoded categorical features """ X_new = X.copy() if self.target_type == ‘classification‘: for variable, target in product(self.categorical_features, self.target_values): nf_name = ‘{}_pred_{}‘.format(variable, target) X_new[nf_name] = 0 for prior, col_avg_y in self.learned_stats[nf_name]: X_new[nf_name] += X_new[[variable]].join(col_avg_y, on=variable).fillna(prior, inplace=False)[nf_name] X_new[nf_name] /= self.n_splits else: for variable in self.categorical_features: nf_name = ‘{}_pred‘.format(variable) X_new[nf_name] = 0 for prior, col_avg_y in self.learned_stats[nf_name]: X_new[nf_name] += X_new[[variable]].join(col_avg_y, on=variable).fillna(prior, inplace=False)[nf_name] X_new[nf_name] /= self.n_splits return X_new
以上是关于平均数编码:针对某个分类特征类别基数特别大的编码方式的主要内容,如果未能解决你的问题,请参考以下文章