Python基础之内置函数
Posted ccorz
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python基础之内置函数相关的知识,希望对你有一定的参考价值。
先上一张图,python中内置函数:

python官方解释在这:点我点我
继续聊内置函数:
callable(object):检查对象是否可被调用,或是否可执行,结果为bool值
def f1(): pass f2 = 123 print(callable(f1)) print(callable(f2)) out: True False
char():
ord():
这两个一起讲,都是对应ASCii表的,char(obect)将十进制数字转化为ascii中对应的字母,ord(object)将字母转化为ascii中对应的十进制数字。
顺便上一张ascii表吧,以便以后查询:
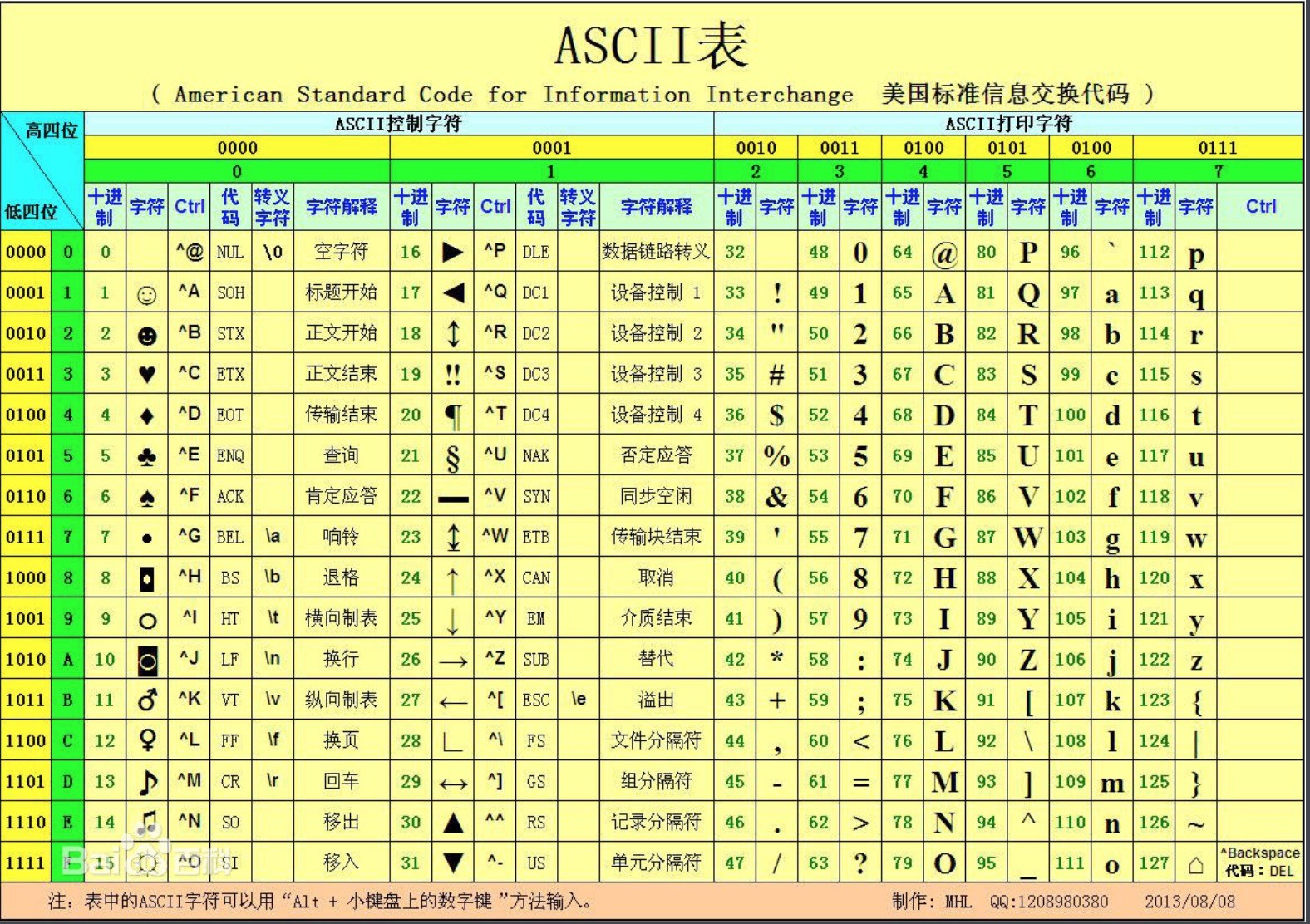
用处呢,可以用来搞随机验证码等等,随机验证码在这:点我点我
>>> chr(89) \'Y\' >>> chr(64) \'@\' >>> ord(\'x\') 120 >>>
compile():将字符串编译成python代码,格式:compile( str, file, type )
compile语句是从type类型(包括’eval’: 配合eval使用,’single’: 配合单一语句的exec使用,’exec’: 配合多语句的exec使用)中将str里面的语句创建成代码对象
exam:
>>> s = "print(123)" >>> r = compile(s, "<string>", "exec") >>> exec(r) 123 >>>
执行:
eval() exec()
eval():格式:eval( obj[, globals=globals(), locals=locals()] ), 运算符,表达式:只能执行运算符,表达式, 并且eval() 有返回值
exec(): 格式:exec(obj),执行代码或者字符串,没有返回值,执行代码时,接收代码或者字符串
exam:
>>> s=\'8*8\' >>> eval(s) 64 #有返回值 >>> >>> exec(\'8+7*8\') #无返回 >>> eval(\'8+7*8\') 64 >>>
dir():快速查看对象提供了哪些功能
help():查看对象使用帮助,显示功能详情
exam:


>>> dir(list) [\'__add__\', \'__class__\', \'__contains__\', \'__delattr__\', \'__delitem__\', \'__dir__\', \'__doc__\', \'__eq__\', \'__format__\', \'__ge__\', \'__getattribute__\', \'__getitem__\', \'__gt__\', \'__hash__\', \'__iadd__\', \'__imul__\', \'__init__\', \'__iter__\', \'__le__\', \'__len__\', \'__lt__\', \'__mul__\', \'__ne__\', \'__new__\', \'__reduce__\', \'__reduce_ex__\', \'__repr__\', \'__reversed__\', \'__rmul__\', \'__setattr__\', \'__setitem__\', \'__sizeof__\', \'__str__\', \'__subclasshook__\', \'append\', \'clear\', \'copy\', \'count\', \'extend\', \'index\', \'insert\', \'pop\', \'remove\', \'reverse\', \'sort\'] >>> help(list) Help on class list in module builtins: class list(object) | list() -> new empty list | list(iterable) -> new list initialized from iterable\'s items | | Methods defined here:
divmod() :求商和余数,返回数据类型是元组,常用于页面分页计算
>>> r = divmod(100, 10) >>> print(r[0]) 10 >>> print(r[1]) 0 >>> print(r) (10, 0) #也可这么用 >>> n1,n2=divmod(100,9) >>> print(n1,n2) 11 1 >>>
isinstance():判断对象是否为某类的实例
>>> s=\'alex\' >>> isinstance(s,str) True >>> li=[1,2,3,4] >>> isinstance(li,dict) False >>>
filter(func,obj):过滤,其中obj为可迭代的对象, 循环第二个参数,将每一个循环元素,去执行第一个参数(函数),如果函数的返回值为True,即合法
filter()用来筛选,函数返回True,将元素添加到结果中。
需要注意的是,filter如果直接打印的话,是一个内存地址,需要将其转化为有序元素,比如list等。
exam:
def f1(args): result = [] for item in args: if item > 22: result.append(item) return result li = [11, 22, 33, 44, 55] ret = f1(li) print(ret) out: [33, 44, 55] =================== li=[11,22,33,45,67,23,14,52,] def f1(a): if a > 22: return 1 res=filter(f1,li) print(type(res)) print(list(res)) out: <class \'filter\'> [33, 45, 67, 23, 52] ================= li = [11, 22, 33, 44, 55] res=filter(lambda a:a>27,li) print(list(res)) out: [33, 44, 55]
可以看出来,使用lambda表达式可使代码更简洁,因为lambda表达式是自动return,不用像函数那样特意定义返回值
li=[11,22,33,45,67,23,14,52,] res=map(lambda a:a+100,li) print(list(res)) out: [111, 122, 133, 145, 167, 123, 114, 152]
filter与map的区别:
filter()是使用函数对可迭代对象进行筛选,如果函数返回为True,将对象添加到结果中
map()是使用函数对可迭代对象进行处理,批量操作,将函数返回值添加到结果中
frozenset() :不可变集合,与set()相对
set()是可变的,有add(),remove()等方法。既然是可变的,所以它不存在哈希值
NAME = "ALEX" def show(): a = 123 c = 123 print(locals()) print(globals()) show() out: {\'c\': 123, \'a\': 123} {\'__package__\': None, \'__spec__\': None, \'__cached__\': None, \'__loader__\': <_frozen_importlib_external.SourceFileLoader object at 0x1007a5c50>, \'show\': <function show at 0x10137b620>, \'__builtins__\': <module \'builtins\' (built-in)>, \'__name__\': \'__main__\', \'__file__\': \'/Users/shane/PycharmProjects/Py_study/Base/S4/test.py\', \'__doc__\': None, \'NAME\': \'ALEX\'}
hash():生成hash值,生成的值不是固定的
exam:
s = "hhhasdfasdfasdfasdfasdfasdfasdfasdfa" \\ "sdfasdfasdfhhhasdfasdfasdfasdfasdfasdfasdfasdfasdfasdfasdf" print(hash(s)) out: 1352149349547718846
len() 计算元素的长度的,但需要注意的一点是汉字:
在2.7中,len(\'汉字\')是按字节算的,值为6
在3.5中,len(\'汉字\')是按字符算的,值为2
exam:
s=\'李杰\' print(len(s)) b=bytes(s,encoding=\'utf8\') print(len(b)) out: 2 6
>>> li=[1,2,56,7,8,90] >>> min(li) 1 >>> max(li) 90 >>> sum(li) 164 >>>
pow() 求幂,等同于**
exam:
>>> pow(10,3)
1000
>>> 10**3
1000
>>>
reversed() 反转
exam:
li = [11,22,1,1] #与 li.reverse() 相同 reversed(li) print(li) out: [11, 22, 1, 1]
round() 四舍五入
exam:
>>> round(1.4) 1 >>> round(5.8) 6 >>>
sorted() 排序
exam:
li = [11,2,1,1]
li.sort()
等同:
sorted(li)
zip() 接受任意多个(包括0个和1个)序列作为参数,返回一个tuple列表,不是很好描述
exam:
l1 = ["alex", 11, 22, 33] l2 = ["is", 11, 22, 33] l3 = ["sb", 11, 22, 33] r = zip(l1, l2, l3) print(r) print(list(r)) out: <zip object at 0x10137cfc8> #注意结果,print的话也是内存地址 [(\'alex\', \'is\', \'sb\'), (11, 11, 11), (22, 22, 22), (33, 33, 33)]
注意长度计算方式:
x = [1, 2, 3] y = [4, 5, 6, 7] xy = zip(x, y) print(list(xy)) out: [(1, 4), (2, 5), (3, 6)]
一个列表:
x = [1, 2, 3] zx=zip(x) print(list(zx)) y=[1,] zy=zip(y) print(list(zy)) out: [(1,), (2,), (3,)] [(1,)]
slice() 切片
格式:slice(start,stop,step) 也可 slice(none,stop,none)
exam:
l=list(range(10)) print(l) print(l[slice(1,6,2)]) print(l[1:8:2]) print(l[slice(5)]) out: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] [1, 3, 5] [1, 3, 5, 7] [0, 1, 2, 3, 4]
字符串也可以这么搞
s=\'abddfdfdf\' print(s[0:8:2]) print(s[slice(0,8,2)]) out: adff adff
以上是关于Python基础之内置函数的主要内容,如果未能解决你的问题,请参考以下文章