架构设计:系统间通信(33)——其他消息中间件及场景应用(下3)
Posted 说好不能打脸
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了架构设计:系统间通信(33)——其他消息中间件及场景应用(下3)相关的知识,希望对你有一定的参考价值。
===================================
(接上文:《架构设计:系统间通信(32)——其他消息中间件及场景应用(下2)》)
5-7、解决方案三:非侵入式方案
以上两种方案中为了让业务系统能够集成日志采集功能,我们或多或少需要在业务系统端编写一些代码。虽然通过一些代码结构的设计,可以减少甚至完全隔离这些代码和业务代码的耦合度,但是毕竟需要业务开发团队花费精力对这些代码进行维护,业务系统部署时业务对这些代码的配置信息做相应的调整。
这里我们再为读者介绍一种非侵入式的日志采集方案。我们都知道业务系统被访问时,都会产生一些访问痕迹。 同样以“浏览商品详情”这个场景为例,当访问者打开一个“商品详情”页面时(URL记为A),那么首先nginx的access日志就会有相应的80端口的访问日志,如果“商品详情”的信息并非全静态的,那么接下来业务服务上工作的代码还会在Log4j文件上输出相应的访问信息(如果开发人员使用了Log4j的话)。我们要做的事情就是找一款软件,将这些日志信息收集起来并存放在合适的位置,以便数据分析平台随后利用这些数据进行分析工作。
当然为了保证这些日志信息中有完整的原始属性,业务系统的开发人员和运维人员应该事先协调一种双方都认可的日志描述格式,以及日志文件的存储位置和存储规则等信息。
5-7-1、Flume介绍
Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture based on streaming data flows. It is robust and fault tolerant with tunable reliability mechanisms and many failover and recovery mechanisms. It uses a simple extensible data model that allows for online analytic application.
以上文字引用来自Apache Flume官网(http://flume.apache.org/)。大意是:Flume是一个分布式的、具有高可靠的、高可用性的用于有效地收集、汇总日志数据的服务。它的架构基于数据流,简单灵活。。。我们要介绍的非侵入日志采集方案,就基于Apache Flume进行实现。
Apache Flume非常非常简单,并且官方给出的用户手册已经足够您了解它的使用方式和工作原理(http://flume.apache.org/FlumeUserGuide.html),所以本文并不会专门介绍Flume的安装和基本使用,并试着将Flume的使用融入到实例讲解中。如果您希望更深入学习Flume的设计实现,笔者还是建立您阅读Flume的源代码,在其官网的用户文档中已经给出了几个关键的实现类,通过这些实现类即可倒查Flume使用的各种设计模式:
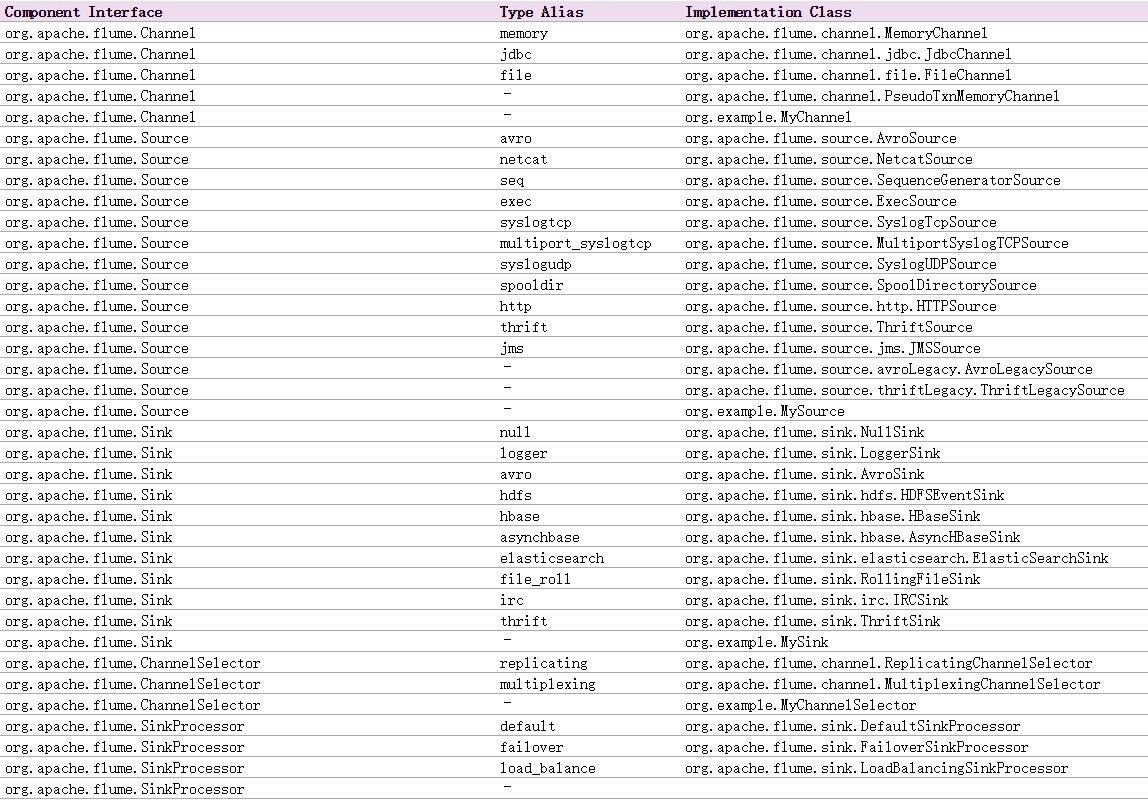
5-7-2、方案设计
Flume和业务服务系统在物理服务器上分别独立工作,在操作系统层面上是两个独立的进程,并没有任何关联。Flume只对操作系统上的文件系统、或者指定的网络端口又或者RPC服务进行数据流监控(Flume中称之为Source)。当指定的文件、指定的网络端口或者指定的RPC服务有新的数据产生时,Flume就会按照预先的配置将这些数据传输到指定位置(Flume中称之为Sink)。这个指定位置可以是网络地址、可以是文件系统还可以是另一个软件。Source和Sink之间的数据流传输通告,称之为Channel。
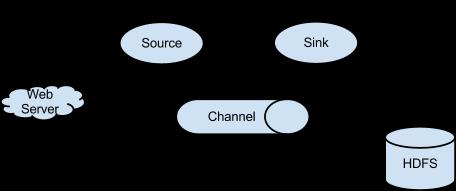
上图来源于Apache Flume官方网站,是一个关于Flume中Source、Sink的例子。在这个例子中,Flume采用一个HTTP Source,用来接收外部传来的HTTP协议的数据;Flume的Sink端采用HDFS Sink,用来将从Channel中得到的数据写入HDFS。那么基于上文介绍的Apache Flume工作特性,我们采用如下思路进行日志采集方案三的设计:
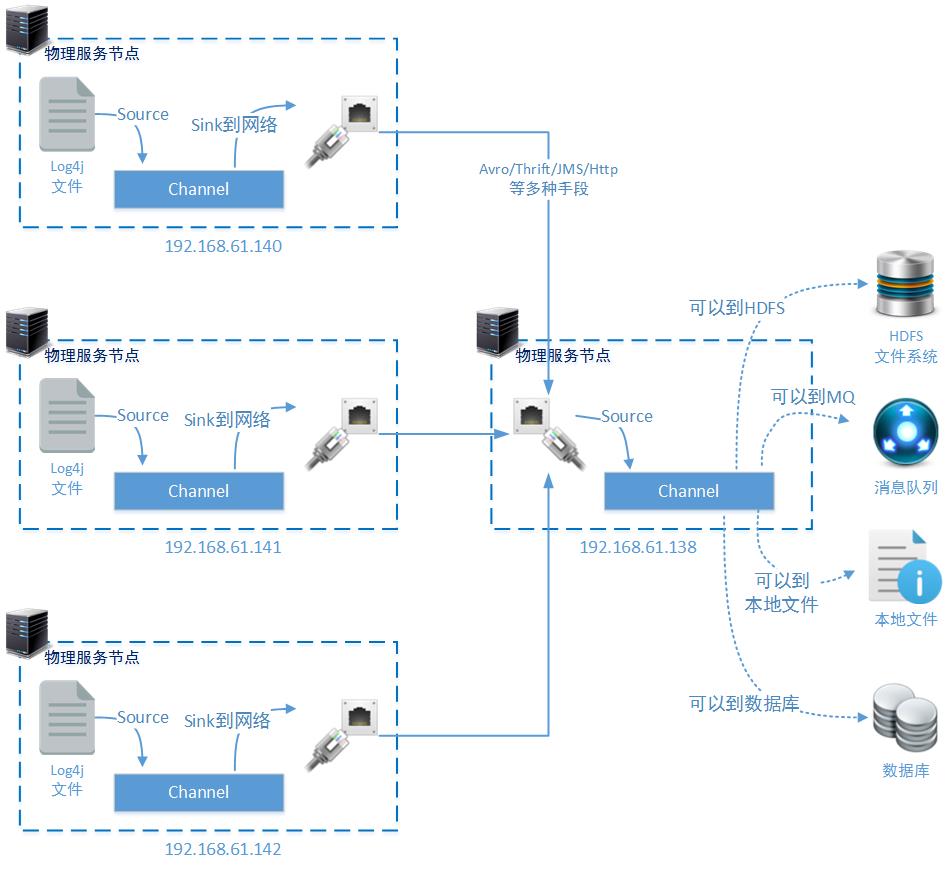
- 日志数据的来源和收集
上图中业务系统工作在140、141、142三个物理节点上,并产生Log4j文件。当然您也可以直接使用JBOSS、Tomcat等服务的原生日志文件作为日志数据来源。有的情况下,我们需要对Nginx等代理服务上Http请求情况进行分析,那么可以使用Nginx的access.log文件作为日志数据的源是来源。您还可以根据设计需要,在每一个物理节点上同时监控多个文件。
在140、141、142三个物理节点上,还分别安装了Apache Flume。他们的工作任务都是一样的,即从指定的需要监控的日志文件中读取数据变化,通过配置好的Channel送到指定的Sink中。在上图的设置中既是监控Log4j文件的变化,通过Channel使用Thrift RPC方式传输到远程服务器192.168.61.138的6666端口。
- 日志数据集中
物理节点192.168.61.138负责收集来自于140、141、142三个物理节点通过Thrift RPC传输到6666端口的日志数据信息。并且通过Channel传输到适当的存储方案中,这些适当的存储方案可能是HDFS、可能是某一种MQ还可能是某种对象存储系统(例如Ceph)、甚至可能就是本地文件系统。
5-7-3、方案配置过程
- 192.168.61.140
上文已经说明,192.168.61.140物理节点上Apache Flume的主要任务是监控业务服务的Log4j日志文件,当日志文件产生新的数据时,通过Flume中已经配置好的Channel发送至指定的Sink。配置信息如下:
agent.sources = s1
agent.channels = c1
agent.sinks = t1
# source ===========================
# log4j.log文件的变化将作为flume的源
agent.sources.s1.type = exec
agent.sources.s1.channels = c1
agent.sources.s1.command = tail -f /logs/log4j.log
# channel ==================================
# 连接source和sink的通道
agent.channels.c1.type = memory
agent.channels.c1.capacity = 1000
# sink t1 ===================================
# 通过通道送来的数据,将通过 thrift RPC调用,送到138节点的6666端口
agent.sinks.t1.type = thrift
agent.sinks.t1.channel = c1
agent.sinks.t1.hostname = 192.168.61.138
agent.sinks.t1.port = 6666192.168.61.141和192.168.61.142两个物理节点也承载了业务服务,并且业务服务会将日志输出到同样的Log4j的位置。所以这两个节点上Apache Flume的配置和以上140物理节点中Apache Flume的配置一致。这里就不再对另外两个物理节点的配置进行赘述了。
另外需要注意的是agent.sources.s1.command配置的Linux tail 命令。tail命令可以显示当前文件的变化情况,如果您只代有-f参数,即表示从文件末尾的最后10行开始对文件的变化情况进行监控。如果这样配置,那么当Flume启动时,就会认为Log4j文件中已经存在的10行记录为新收到的日志数据,造成误发。
要解决这个问题可以使用-n参数,并指定从文件的最末尾开始监控文件变化情况:
# 应该使用
tail -f -n 0 /logs/log4j.log
# 注意:tail -f /logs/log4j.log 命令相当于:
# tail -f -n 10 /logs/log4j.log- 192.168.61.138
192.168.61.138节点上的Flume,用来收集140-142节点通过Thrift RPC传来的日志数据。这些数据收集后,将被138节点上的Flume存放到合适的位置。这些位置可以是HDFS,HBASE、本地文件系统还可以是Apache Kafka等。
agent.sources = s1
agent.channels = c1
agent.sinks = t1
# thrift ==================
# 使用thrift rpc监听节点的6666端口,以便接收数据
agent.sources.s1.type = thrift
agent.sources.s1.channels = c1
agent.sources.s1.bind = 0.0.0.0
agent.sources.s1.port = 6666
# sink hdfs ==============
# agent.sinks.t1.type = hdfs
# agent.sinks.t1.channel = c1
# agent.sinks.t1.hdfs.path = hdfs://ip:port/events/%y-%m-%d/%H%M/%S
# agent.sinks.t1.hdfs.filePrefix = events-
# agent.sinks.t1.hdfs.round = true
# agent.sinks.t1.hdfs.roundValue = 10
# agent.sinks.t1.hdfs.roundUnit = minute
# sink=====================
# 为了检测整个配置是否正确,可先输出到控制台
agent.sinks.t1.type = logger
agent.sinks.t1.channel = c1
# channel=================
agent.channels.c1.type = memory
agent.channels.c1.capacity = 1000以上配置文件中,为了查看这个采集系统的配置是否成功,我们将在Flume控制台作为Sink进行输出。注释的信息是HDFS作为Sink的配置。
5-8、解决方案三优化
上一小节的解决方案三中,最薄弱的位置是承担日志数据汇总任务的138节点。整个日志收集主架构中只存在一个这样的汇总节点,一旦138节点由于各种原因宕机主架构就将崩溃。即使138节点能够稳定工作,由于138节点同时承担多个物理节点传来的数据日志,那么它也极有可能成为性能瓶颈。所以我们需要找到一种方案三中薄弱位置的办法。
5-8-1、Flume支持的高可用模式
还好,Apache Flume为我们提供了非常简单实用的高可用模式:Load_balance模式和Failover模式。这两种工作模式都是对多个Sink如何配合工作进行描述:
- Load_balance模式:
这种工作模式提供了多个sinks负载均衡的能力。Load_balance会维护一个active sinks列表,基于这个列表,使用round_robin(轮询调度) 或者 random(随机) 的选择机制(默认为:round_robin),向sinks集合。基本上这两种选择方式已经够用了,如果您对调度选择有特别的要求,则可以通过继承AbstractSinkSelector类来实现自定义的选择机制。
- Failover模式:
这种工作模式提供了多个sinks的故障转移能力。Failover维护了两个sinks列表,Failover list和Live list,在Failover模式下,Flume会优先选择优先级最高的Sink作为主要的发送目标。当这个Sink连续失败时Flume会把这个Sink移入Failover list,并且设置一个冷冻时间。在这个冷冻时间之后,Flume又会试图使用这个Sink发送数据,一旦发送成功,这个Sink会被重新移入Live list。
为了保证能够为数据汇总节点分担性能压力,我们使用Load_balance模式进一步演示对数据汇总节点的优化。
5-8-2、使用Load_balance模式
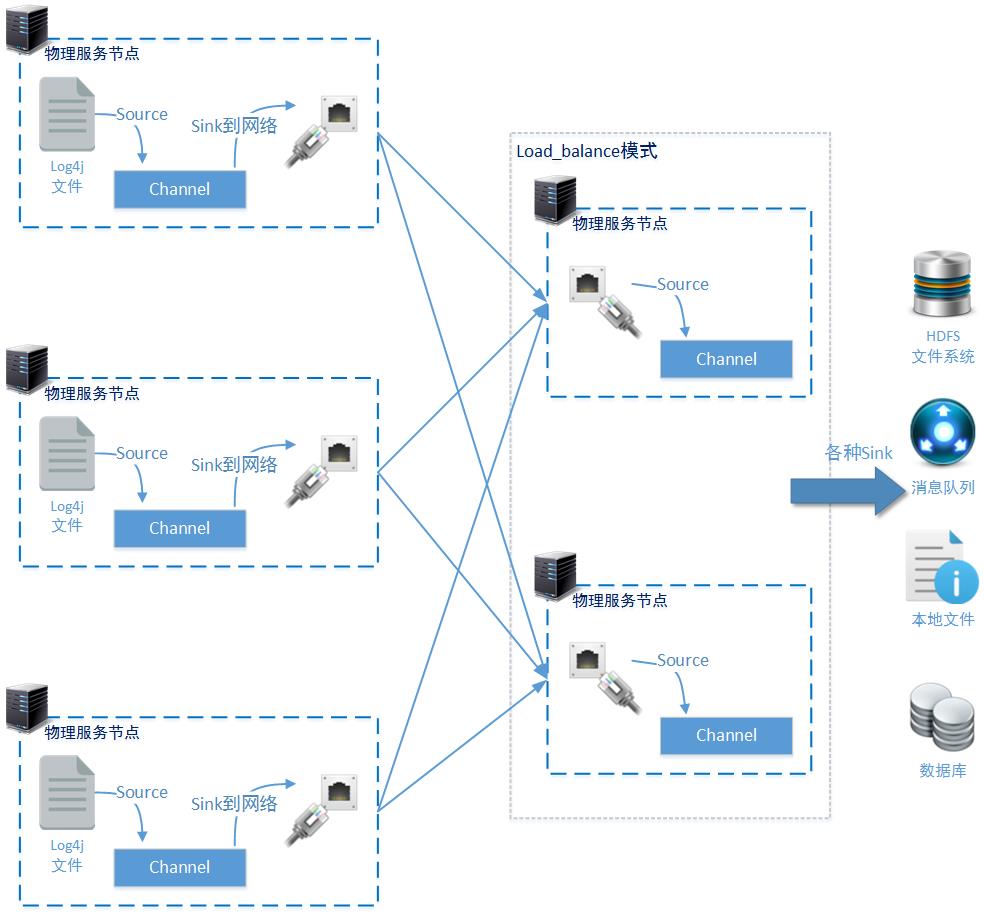
从上图中可以看到在方案三的优化方法中,我们使用一个新的节点(192.168.61.139)和原有的138节点一起构成一组负载节点,共同承担日志数据的汇总任务。那么前端日志监控节点(140、141、142三个节点)也需要做相应的配置文件修改。
5-8-3、Load_balance配置过程
- 修改192.168.61.140节点
agent.sources = s1
agent.channels = c1
# 设置了两个sink
agent.sinks = lt1 lt2
agent.sinkgroups = g1
# source ===========================
# 数据源还是来自于log4j日志文件的新增数据
agent.sources.s1.type = exec
agent.sources.s1.channels = c1
agent.sources.s1.command = tail -f -n 0 /log/log4j.log
# sink lt1 ===================================
agent.sinks.lt1.type = thrift
agent.sinks.lt1.channel = c1
agent.sinks.lt1.hostname = 192.168.61.138
agent.sinks.lt1.port = 6666
# sink lt2 ==================================
agent.sinks.lt2.type = thrift
agent.sinks.lt2.channel = c1
agent.sinks.lt2.hostname = 192.168.61.139
agent.sinks.lt2.port = 6666
# channel ==================================
agent.channels.c1.type = memory
agent.channels.c1.capacity = 1000
# sinkgroup ===============================
# 两个sink:lt1 lt2 设置成一组sink。并使用load_balance模式进行工作
agent.sinkgroups.g1.sinks = lt1 lt2
agent.sinkgroups.g1.processor.type = load_balance
agent.sinkgroups.g1.processor.backoff = true
agent.sinkgroups.g1.processor.selector = random141和142两个日志数据监控节点的配置和140节点的配置一致,所以同样不再赘述了。
- 新增192.168.61.139节点
agent.sources = s1
agent.channels = c1
agent.sinks = t1
# thrift==================
agent.sources.s1.type = thrift
agent.sources.s1.channels = c1
agent.sources.s1.bind = 0.0.0.0
agent.sources.s1.port = 6666
# sink=====================
agent.sinks.t1.type = logger
agent.sinks.t1.channel = c1
# channel=================
agent.channels.c1.type = memory
agent.channels.c1.capacity = 1000新增的139节点上Flume的配置信息和原有138节点上Flume的配置信息是一致的。这样保证了无论日志数据被发送到哪一个节点,都能正确进行存储。
5-9 方案三的局限性
日志采集方案三也存在局限性:这种方案不适合用于开放性日志采集系统。也就是说,如果您的日志采集系统需要像“百度站长统计工具”那样,从设计之初的目标就是要发布给互联网上各个站点使用的。那么这种基于操作系统日志变化,并采用第三方软件完成采集过程的架构方案就不适用。
另外,方案三我们使用了Thrift RPC进行网络通讯。这个方式是可以用于真正的生产环境的,但是需要进行更多的配置项指定。以下两个链接地址是分别是使用thrift作为source和sink时可以使用的配置属性。
http://flume.apache.org/FlumeUserGuide.html#thrift-source
http://flume.apache.org/FlumeUserGuide.html#thrift-sink
除了Thrift RPC以外,笔者还推荐使用Avro。
6、场景应用——Online游戏:子弹弹道日志功能
//TODO 这是一个扣子,后续的文章会讲到
7、下文介绍
经过《架构设计:系统间通信(19)——MQ:消息协议(上)》开始的14篇文章,我们基本上介绍了消息队列的基本知识和使用实战。从下文开始我们转向ESB企业服务总线的知识讲解。
以上是关于架构设计:系统间通信(33)——其他消息中间件及场景应用(下3)的主要内容,如果未能解决你的问题,请参考以下文章
架构设计:系统间通信(31)——其他消息中间件及场景应用(下1)