一、生产者消费者模型
我们去超市商店等地购买商品时,我们大部分人都会说自己是消费者,而超市的各大供货商、工厂等,自然而然地也就成了我们的生产者。如此一来,生产者有了,消费者也有了,那么将二者联系起来的超市又该作何理解呢?诚然,它本身是作为一座交易场所而诞生。
上述情形类比到实际的软件开发过程中,经常会发现:某个线程或模块的代码负责生产数据(工厂),而生产出来的数据却不得不交给另一模块(消费者)来对其进行处理,在这之间使用了队列、栈等类似超市的东西来存储数据(超市),这就抽象除了我们的生产者/消费者模型。
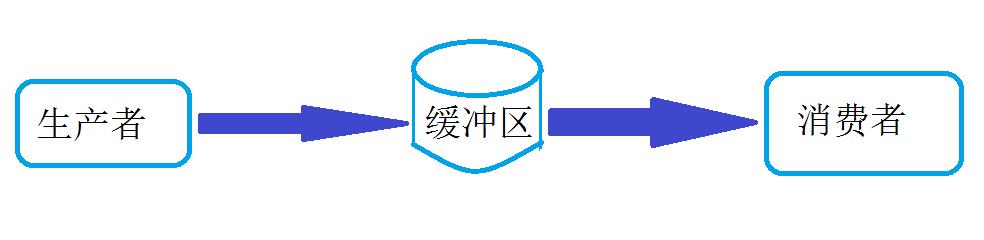
其中,产生数据的模块,就形象地称为生产者;而处理数据的模块,就称为消费者;生产者和消费者之间的中介就叫做缓冲区。
在来一个列子:
我们在使用QQ, 微信通信过程,或者邮件
- 我们写信、写消息,然后将消息发送过去, ---相当于生产者,发布消息
-中 间QQ、微信、邮件服务器收到数据(等于缓冲区), ---相当于缓冲区,队列queue等 - 然后收消息的人上线,从服务端取出消息,邮件,去办理相关的业务 ----相当于消费者处理数据
1.1 生产者消费者模型的好处
生产者消费者模式就是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。这个阻塞队列就是用来给生产者和消费者解耦的。
在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这种生产消费能力不均衡的问题,所以便有了生产者和消费者模式。
优点:
-
解耦,即降低生产者和消费者之间的依赖关系。
比如我们在修改消费者功能时,不需要考虑生产者模块的代码,同理对于生产者 -
支持并发,即生产者和消费者可以是两个独立的并发主体,互不干扰的运行。
在生产者和消费者之间,因为是通过队列通讯,互不干扰,所以可以起两个线程,各自完成自己的工作 -
支持忙闲不均,如果制造数据的速度时快时慢,缓冲区可以对其进行适当缓冲。当数据制造快的时候,消费者来不及处理,未处理的数据可以暂时存在缓冲区中。等生产者的制造速度慢下来,消费者再慢慢处理掉。
二、通过queue来实现一个生产者消费者模型
import threading
import queue
import time
q= queue.Queue(10)
def producer(worker,q):
count = 0
while True:
if not q.full():
q.put(count)
print(\'[{}] 生产了 {}\'.format(worker, count))
count += 1
time.sleep(0.3)
def consumer(name, q):
while True:
print(\'{} 消费了 {}\'.format(name, q.get()))
time.sleep(1)
if q.qsize() == 0:
break
p1 = threading.Thread(target= producer, args= (\'lina\', q))
c1 = threading.Thread(target= consumer, args= (\'david\', q))
c2 = threading.Thread(target= consumer, args= (\'sven\', q))
p1.start()
c1.start()
c2.start()
#执行结果为
[lina] 生产了 0
david 消费了 0
[lina] 生产了 1
sven 消费了 1
[lina] 生产了 2
[lina] 生产了 3
david 消费了 2
[lina] 生产了 4
sven 消费了 3
[lina] 生产了 5
[lina] 生产了 6
david 消费了 4
[lina] 生产了 7