zipkin分布式链路追踪系统
Posted Leo_wlCnBlogs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了zipkin分布式链路追踪系统相关的知识,希望对你有一定的参考价值。
分布式服务追踪系统起源于Google的论文“Dapper, a Large-Scale Distributed Systems Tracing Infrastructure”(译文可参考此处),Twitter的zipkin是基于此论文上线较早的分布式链路追踪系统了,而且由于开源快速被各社区所研究,也诞生了很多的版本。
在这里也是对zipkin进行研究,先贴出Twitter zipkin结构图。

结构比较简单,大概流程为:
- Trace数据的收集至Scribe(Facebook开源的日志传输通路)或Kafka(Apache分布式消息系统)。
- Scribe/Kafaka中的数据由控制器存入数据库中。
- 最后由UI和Query查询展示。
这里将提到一个日志分析系统ELK,它是一个集合日志收集、日志分析查询于一体。系统主要拆分为:收集(logstash)、存储(elasticsearch)、展示(kibana)三部分,目前被我们用于做分布式服务日志系统。
在此想到尽然ELK已经帮我们收集了分布式服务的日志并统一存储,为何链路追踪系统不能直接用这些日志做查询展示呢?
所以从此角度出发,我对该方案结构进行构图,希望可行。先贴出我画的结构图(丑了些,将就看吧):
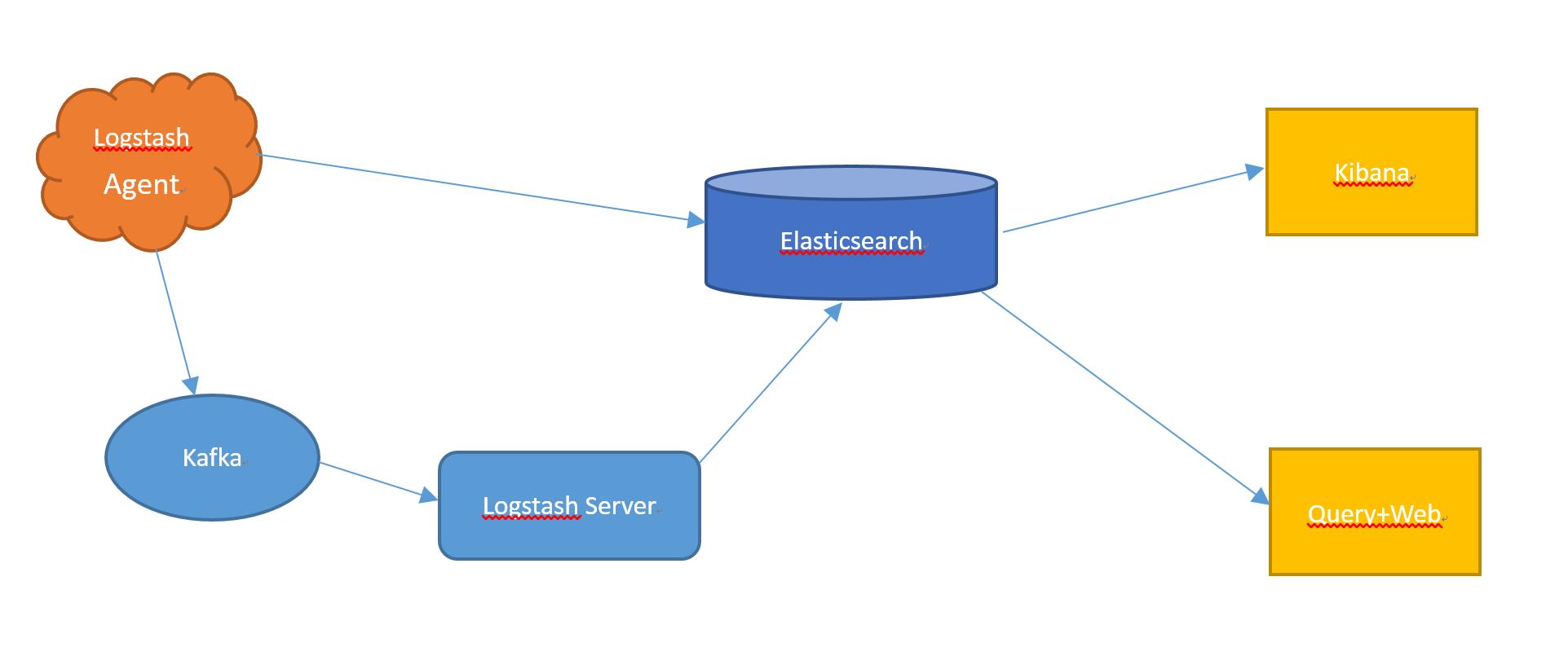
对此结构开始部署环境,环境部署在下次讲到。
当前部门研发分布式服务架构,讨论到分布式链路追踪系统。所以在这对分布式链路追踪系统进行一个学习,并写成笔记作为一个学习的动力。 笔记中所有都为个人见解,可能存在错误,望大家指出。
分类: 分布式服务架构