指令选择器调查
Posted wuhui_gdnt
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了指令选择器调查相关的知识,希望对你有一定的参考价值。
4. DAG覆盖
就像我们在前一章看到的,唯一地依赖树的一个内在缺点是不能正确地对公共子表达式建模。这意味着一个表达式必须要么分成一个树林,要么在每棵子树中重复操作。两者都不是好的解决案,因为它们都导致次优的代码。这个问题的一个解决方案是不要把表达式建模为树,而是有向无环图(DAG)。DAG允许节点有多个外出边,因此使得中间节点的值可以共享及重用。执行指令选择可以使用与树相同的模式匹配及选择思路(参考图4.1)。因此在大多数现代编译器中的指令选择器通常工作在表达式DAG而不是树上。特别的,这还使得多个输出的机器指令的建模成为可能,比如同时计算商与余数的divmod指令。
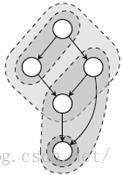
图4.1:DAG覆盖问题的例子。模式实例由虚线及包含该模式匹配的节点的阴影背景表示
不幸的是,在通用及建模能力方面收益的代价是复杂性的显著增加;尽管在树上选择最优模式可以在线性时间内完成,对于DAG同样的动作是一个NP-完全问题。Bruno与Sethi【34】,Aho等【4】已经在1976年给出了证明,尽管它们更面向最优指令调度及寄存器分配,而不是指令选择。在1995年Proebsting【186】给出了最优指令选择的一个非常简短的证明,后来由Koes与Goldstein【150】在2008年重新阐述。我们将在本报告中给出Koes与Goldstein证明的大意。注意到这不需要涉及模式匹配的任务——正如我们将看到的,如果模式包含树,这仍然可以在多项式时间内完成。
定理1。最优(从这个层面来说,最低代价)指令选择是NP-完全问题。
证明。该证明建立在把SAT(布尔可满足性)问题归纳为最优指令选择问题。SAT问题是确定一个合取范式形式(CNF)的布尔计算式是否可取值T。一个CNF表达式是一个具有形式“(x11 ∨ x12 ∨ . . .) ∧ (x21 ∨ x22 ∨ . . .) ∧ . . .”的式子;变量x还可以通过¬x取反。因为这个问题已经证明是NP完全的【59】,所有多项式时间内可以SAT归纳到的任何其他问题P必然还保留NP完全性。
首先我们将一个SAT问题转换为一个DAG。直观地,如果我们可以单位代价的模式覆盖这个DAG,这样整个代价等于节点数(假定每个变量及操作符导致一个新节点),那么对这些变量存在一个真值指派,公式对其求值的结果是T。为此,该DAG中的节点可以是类型{∨,∧,¬,v,□,⎔}。定义type(n)为节点n的返回类型,并分别称节点类型□与⎔为盒子节点(box nodes)及停止节点(stop nodes)。我们还定义children(n)来返回子节点集到n。对于每个布尔变量“x∈S”,创建两个节点v1与v2,使得type(v1) = v与type(v1) = □,以及一条有向边(v1, v2)(意即n1→ n2)。通过创建两个节点o1与o2,使得type(o1) = op与type(o1) = □,以及一条边(o1, o2),我们同样处理 每个二元布尔操作符op∈S。我们还创建(a, o1)与 (b, o1),使得a与b都是该操作输入的盒子节点(即type(a) = type(b) = □)。因为布尔or与and都是满足交换律的,就操作符节点而言,边以什么次序安排是无关紧要的。显然,对于取反我们仅创建一条这样的边。作为结果,仅该盒子节点可以有多个父亲(及多条外出边)。仅通过遍历该布尔式我们可以在线性时间构建对应的DAG。一个SAT问题转换到一个指令选择问题的例子在图4.2(b)中给出。
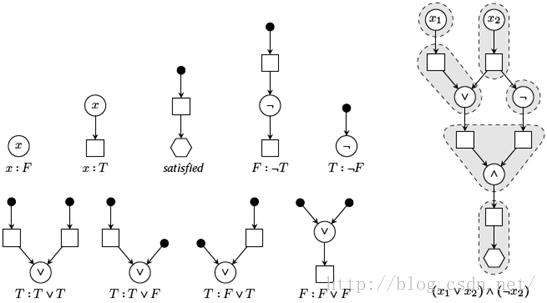
(a) SAT模式。所有模式具有单位代价。简短而言,∧操作的 (b)一个SAT问题转换到
模式是流出的,但可以很容易从∨模式推导。 一个指令选择问题的例子
图4.2:SAT到指令选择的归纳(来自【150】)
我们构建一组树模式P,它允许我们推断应该如何设置变量来满足该表达式。这个模式集显示在图4.2(a)中。这样形成模式,如果该值是假定设置给T的,使得它具有一个盒子节点作为叶子。另外,如果该操作的结果是对F求值,模式具有一个盒子节点作为根节点。看待它的一种方式是,如果模式中的一个操作消耗了一个盒子节点,那么这个值必须设置为T,而如果该操作符产生一个盒子节点,那么结果必须取值为F。要迫使整个表达式取值为T,仅有的包含一个停止节点的模式也消耗一个盒子节点。
除了节点类型可以出现在DAG表达式里,模式节点还可以使用一个额外的节点类型●,我们称为锚节点(anchor nodes)。现在我们说带有根节点pr的一个树模式匹配一个节点v∈V,其中V是表达式DAG D = (V,E)中的节点集,当且仅当:
1. type(v) = type(pr),
2. |children(v)| = |children(pr)|及
3. ∀cv ∈ children(v), cr ∈ children(pr): (type(cr) = ●) ∨ (cr匹配cv).
换而言之,树模式的结构必须对应子图的结构,除了锚节点可以在任何节点处匹配。我们还引入两个新的定义:matchset(v),它返回P中匹配v的树模式集合;以及mpi→v(vp),它返回对应在匹配模式pi的节点vp的DAG节点v∈V。最后,我们说一个DAG D = (V, E)被一个从DAG节点到模式的映射函数f:V → 2T所覆盖,当且仅当∀v ∈ V:
1. p ∈ f(v) => p匹配v且p ∈ P,
2. in-degree(v) = 0=> |(v)| > 0,且
3. ∀p ∈ f(v),∀vp ∈ p s.t. type(vp) = ● => |f(mpi→v(vp))| >0。
第一个限定强制每个选中的模式是匹配的且是一个真实的模式。第二个限定强制停止节点的匹配,而第三个限定强制DAG余下部分的匹配。D = (V,E)的一个最优覆盖是覆盖D且使得
最小。其中cost(t)返回模式p的代价。
现在假设如果最优覆盖有一个等于DAG中非盒子节点数量的总体代价,那么对应的SAT问题是可以满足的。这应该是清楚的,因为P中所有的树模式实际上覆盖了一个非盒子节点,且具有均等的单位代价;如果DAG中的每个非盒子节点正好被一个模式所覆盖,那么我们可以容易地通过查看选择了哪些模式来覆盖那些节点,推导出布尔变量的赋值。通过执行DAG的一个简单的深度优先遍历,查找这些模式可以在线性时间内完成。
这样我们已经展示SAT问题的一个实例可以通过在多项式时间归纳为最优指令选择问题的一个实例来解决。因此最优指令选择问题是NP-完全性的。
4.1. DAG上的树模式匹配
Aho等【4】在第一批文献中提供了在DAG上工作的代码生成方法。在他们的论文里,发表在1976年,Aho等提出了某些简单、贪婪的启发式,以及一个对符合交换律、单寄存器机器产生代码的最优代码生成器。不过,他们的方法假定程序节点与机器指令间存在一一对应的关系,因此实际上忽略了最优指令选择的问题。
4.1.1. 去dag化
因为DAG上的指令选择是非常困难的,最早处理这样输入的方法仅仅是把它们去dag化成为一个树林。这可以两个方式来完成。第一个方法是从共享节点(即出现重用)分裂边,这导致一组没有联系的树。树之间一个隐含的联系通过强制共享节点写入一个特定的位置(比如内存),后续的树将其读入作为输入来维护。这个技术用于比如Dagon,由Keutzer【145】开发的一个技术包装器(technology binder)。第二个方法是为每次重用复制子树,这也导致了一组没有联系的树。然后每棵树可以使用传统的树覆盖方法单独处理。这两个概念都显示在图4.3中。
尽管去dag化使得在DAG上应用已知的做法进行指令选择成为可能,它有一个重要的缺点:太激进的分裂妨碍了复杂模式的应用,因为它产生了许多小的树;而太激进的复制产生低效的代码,因为在最终代码里许多操作没有必要地重复执行了。因此这两个做法都导致了次优的代码。另外, 一个分裂的DAG的中间结果必须被临时保存,这对于内存-寄存器混杂架构来说是麻烦的。最后这个问题由Araujo等【17】调查。
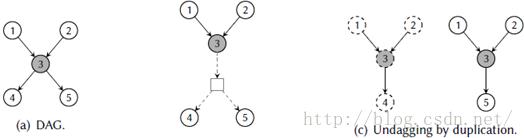
图4.3:去dag化的例子。(b)中的方形节点与虚线只是展示数据依赖性,并不是图的实际部分。
Fauth等【86,174】提出一个尝试通过平衡复制与分裂缓解这个缺陷的做法。在实现CBC代码生成器时,他们应用一个偏向复制的启发式算法,直到复制被认为代价太高为止。这时,算法转向分裂。通过比较两个解决方案的代价,选择代价最小的那个来决定复制还是分裂。以树节点数与每条执行路径上期望执行节点数(分别是代码大小与执行时间的一个粗略估计)的一个加权总和来计算代价。这一旦完成,每棵结果树传给一个改进的支持扩展匹配条件的IBURG。不过,实验数据充其量是有限的,这使得将该算法的效率与简单纯朴的去dag化进行比较变得困难。
4.1.2. 将树解析扩展到DAG
在1999年Ertl【80】发表了一篇论文,把树解析思想扩展到DAG,而无需首先将DAG分解为树。
该思想是,首先在DAG上执行一个自底向上遍,就像它是一棵树,并且使用第三章描述的传统DP方法为每个非终结符计算每节点的最小代价。这样每个节点被标记上相同的代价,就好像该DAG首先通过复制被归约到一棵树。不过,Ertl认识到如果几个模式期望归纳某个子节点到相同的非终结符,那么可以在这些模式间共享该非终结符的归约。在代码流出期间这使得对一个给定的非终结符组合仅流出一次代码。从而有效地减小了代码的大小,同时提升了性能,因为重复操作的个数减少了。图4.4给出了一个例子说明这一点。在那里,我们看到加法操作将被实现两次,因为它被两个独立的模式覆盖,每个模式归约到不同的非终结符。不过,reg节点被两次归约到相同的非终结符,因此可以在不同的模式间共享。
Ertl的方法优于单纯的去dag化,且通过维护合适的访问者集合,在执行时间上是线性的。不过,尽管论文的标题是那样宣称,除了对于某组树语法,它不是最优的。因此,论文还描述了检测这样语法的一个方法。直觉是,检查每个局部最优的决定是否也是全局最优的。这可以通过使用Burg的思想来实现,Ertl实现了一个称为DBURG的检查器,它在所有可能的输入DAG集合上执行一个归纳证明。
Koes与Goldstein【150】最近通过一个启发式扩展了Ertl的思想,该启发式在估计复制将不利于代码质量的点上分裂输入DAG。像Ertl,该算法首先在DAG上执行一个自底向上遍,忽略节点共享。然后在共享节点处(即多个模式重叠处)计算两个代价:重叠代价,模式重叠(即复制)的一个估计;及cse代价,将共享节点分散入不同树的一个估计。如果cse代价低于重叠代价,那么共享节点被标记为固定(fixed)。一旦处理了所有的共享节点,被标记为固定的共享节点被划分入不同的树。然后在整个输入图上执行第二次自底向上DP遍,接着一个流出机器指令的自顶向下遍。Koes与Goldstein还测试了他们的实现,一个称为Noltis的线性时间算法,以一个ILP(整数线性规划,integer linear programming)实现为标准,发现在99.7%的测试用例中,Noltis生成了最优方案。不过,像Ertl,两个做法局限在处理树模式,这排斥了对必须被建模为DAG模式的复杂机器指令的选择。
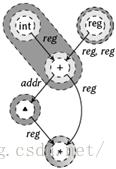
图4.4:一个选择了最优模式的DAG树解析。阴影表示了模式间的关系,而边上的文字表示每个模式归约到的非终结符。注意reg节点实际上被两个模式覆盖(由双虚线模式表示),这两个模式都归约到相同的非终结符,因此共享。
4.1.3. 基于DAG的其他树的方法(Other trees-on-DAGapproaches)
LLVM【219】编译器基础架构使用不同于上面讨论的一个技术。关于LLVM中指令选择如何进行的文档非常少;找到的仅有的来源是Bendersky的博客【26】。指令选择器基本上是一个贪婪的DAG到DAG的重写器,其中基本块的机器无关DAG表示被重写为一个机器相关的表示。由条件语句或循环导致的跳转是基本块的部分,这使得跳转模式可以像其他模式那样处理。模式,被限制为树,以一个允许把公共特性提取为抽象指令的机器描述格式来表示。然后机器描述被一个称为TableGen的工具展开为完整的模式。接着这些模式被一个匹配程序生成器处理,它首先在模式上执行一个字典序排序——一开始根据复杂性降低(这是模式大小与某些常量的和),接着由代价的递增,最后由输出模式大小的递增。然后每个模式被转换为一个递归的匹配程序,它本质上是一个检查该模式是否匹配输入DAG中一个给定节点的小程序。这些匹配程序接着被编译为一个字节码形式并组装入一个在指令选择期间查询的匹配程序表。这些表是这样安排的,使得模式以这个字典序进行检查。一旦找到一个匹配,模式被贪婪地选中,输入DAG中匹配的子图被归约为匹配模式的输出(通常是单个节点)。尽管强大且使用广泛,LLVM的指令选择器有几个缺点。主要的缺点是,任何不能被TableGen处理的模式必须通过定制的C函数手工处理。因为模式局限于树形式,这排斥了所有多输出模式。另外,贪婪的方案在代码的质量方面做了妥协。
4.2. DAG上的DAG模式匹配
1.1.1. 将DAG模式分裂为树
在DAG上匹配DAG模式的一个通常的做法是将模式分解为多棵树,执行树模式匹配,然后将匹配树的组合重写组装为原始的DAG形式。通常这可以在O(n2)时间内完成。
Leupers与Marwedel【156,161】开发了一个技术,部分解决了动态规划方法不能匹配包含多个不连贯子模式的模式的缺点。发表在1996年,他们的论文描述了一个处理模式的方法,这种模式包含多个不连贯、执行单个操作的节点,作者称之为复杂模式。这样的模式首先被分解为它们各自的组件,然后将模式集转换为关联的树模式(它们从包含单个节点的复杂模式导出)。那么模式匹配包含两个阶段:在第一个阶段,应用IBURG找出输入DAG的所有匹配树;然后第二个阶段通过一个整数规划(IP)模型【47,204】,将指令选择与调度限制作为线性不等式(这些一会儿再讨论),将单节点模式改组为复杂模式实例。不过,因为这个IP问题在最坏情形下解决时间是指数级的,由Leupers与Marwedel的实现产生的解决方案不一定是最优的。
Leupers【158】扩展这个模型来处理SIMD指令。论文中展示的模型假定SIMD指令涵盖两个输入数,合称为一个SIMD对,不过这个思想可以很容易地扩展到带有n个输入数的SIMD指令。对于SIMD对,线性不等式如下:
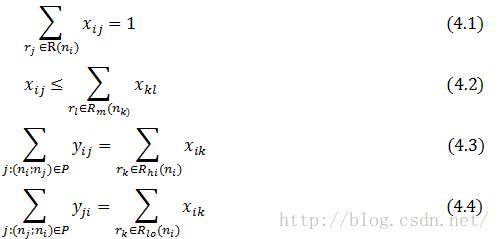
方程4.1 强调输入DAG中的每个节点为某个规则涵盖(R(ni)表示在节点ni匹配的规则集,或模式集,xij是一个表示节点ni是否为规则rj涵盖的布尔变量)。方程4.2强调对节点ni所有子节点选中的规则与对ni选中的规则归约到相同的非终结符(nk表示父节点ni的第m个子节点,而Rm(nk)表示匹配第m个子节点且归约到规则rj的第m个非终结符的规则集)。方程4.3与方程4.4强调应用一条SIMD指令实际上覆盖一个SIMD对,而且任何节点可以为最多一个这样的指令所覆盖(yij是一个布尔变量,表示两个节点ni与nj是否封装在一条SIMD指令中,而Rhi(ni)与Rlo(ni) 分别表示节点ni操作一个寄存器高低部分的规则集)。yij与yji还用于额外的限定里维持可调度性(这我们这里不讨论)。那么目标是最大化SIMD指令的使用,这由下面的目标函数来表示:
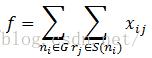
其中G是输入DAG中的节点集,而S(ni) = Rhi(ni) ∪ Rlo(ni)⊂R(ni)。该论文包含了某些实验数据,暗示对于选择的测试用例及目标平台,使用SIMD指令使代码减小了75%。不过,该做法假定SIMD指令的每个独立操作可以被表示为输入DAG中的单个节点。因此不清楚这个方法是否能推广到更复杂的SIMD指令,以及是否能扩展到更大的输入程序。后来Tanaka等【216】扩展了这项工作,在选择SIMD指令的同时考虑数据传输的代价。这通过引入传输节点与传输模式来实现(Tanaka等称之为封包与拆包)。
Bashford与Leupers【24】应用了相同的想法,但在模式匹配后,他们将模式选择问题表示为一个约束规划模型(constraint programming (CP) model)【196】。对于输入DAG中的每个节点,基于在该节点匹配的模式,形成一个分解寄存器传输(factorised register transfer (FRT))。一个FRT的 正式定义是
(Op, D, [U1,... , Un], F, C, T, CS]).
Op是该节点的操作。D是结果可以写入的寄存器集。类似的,Ui是操作可以读入输入i的寄存器集。F,C与T表示扩展资源信息(the extended resource information(ERI)),它们指定了在哪个功能单元将以何代价(C),及由哪条机器指令(T)执行(F)该操作。最后的变量CS,是模式可以应用的限定集。例如,如果在U1中一个功能单元A仅可以写寄存器r,那么这可以表示为U1 = A ⇒ D = r。限定可以任意复杂,以确保生成的代码是正确的。因为最优指令选择是NP-完全的,Bashford与Leupers应用了一个启发式,在共享节点处将输入DAG分成更小的片段,然后在每个片段上孤立地执行指令选择。应用CP到指令选择的这个做法看上去有希望,因为目标架构的任意限制仅被表示为额外的限定;确实,这个做法的目的是瞄准非常规的DSP架构。不过,不清楚它是否能扩展到更大的输入DAG以及模式集。
受前面这些思想的影响,Scharwaechter等【202】开发了另一个方法来处理多个输出的机器指令。首先,在为目标机器定义指令语法时,允许规则在左手侧有多个非终结符。在他们的论文里,Scharwaechter等区分了仅有一个非终结符的规则与包含多个非终结符的规则,分别称它们为规则与复杂规则。规则内非终结符的定义被称为简单规则,复杂规则内的非终结符定义被称为分裂规则(split rules)。这也可以显示为以下形式:

在模式匹配期间,匹配程序仅工作在简单及分裂规则上,并维护分裂规则实例与IR节点间的一个映射。在找到所有这样的匹配后,分裂规则实例被合并为恰当的复杂规则实例,排除违反数据流的组合。然后,每当一个简单规则及一个复杂规则的部分匹配到相同的节点并归约到相同的非终结符,就使用简单规则或复杂规则进行一个代价比较。选择一个复杂模式对输入DAG余下部分的可用模式是有影响的。这是因为复杂模式内节点的中间结果不能重用于其他模式,因此可能需要复制。不过众所周知,复制导致额外的开销。因此指令选择器仅在一种情况下选择复杂模式,如果一个复杂模式替换一组简单模式节省的开销大于复制导致的开销。在完成了这些开销比较后,某些剩下的复杂模式可能覆盖相同的节点,因此必须移除。这个问题通过公式化最大加权独立集(MWIS)问题来解决,其中从一个无向加权图选择一组节点,使得没有被选中的节点是相邻的。另外,选中节点的权重和必须是最大的。在4.3节我们将更深入讨论这个思想。在MWIS图中每个复杂模式形成一个节点,如果两个模式重叠,就在这两个节点间引入一条边。权重被计算为复杂模式中分裂规则开销和的负数(关于分裂规则开销如何计算,该论文是模棱两可的)。因为这个问题已知是NP完全性的,作者应用了一个Sakai等【199】称为GWMIN2的贪婪启发式。最后,在流出代码之前,没有合并入复杂模式的分裂规则被简单规则替代。Scharwaechter等在CBURG中实现了这个方法,作为OLIVE的一个扩展,并通过为一个MIPS架构生成代码来运行某些实验。CBURG产生了利用复杂指令的代码,,然后与仅使用了简单指令的代码比较。结果显示CBURG展示了近乎线性的复杂度,且在这个情形下产生的代码性能提高了25%,大小减少了22%。不过,这个代码生成器不保证最优。后来Ahn等【2】通过包括复杂模式间的调度依赖性冲突,从而形成了一个候选干涉图,拓展了这项工作。那么MWIS问题在这张图上解决。Ahn等还整合了一个带有寄存器分配的反馈循环,以便利寄存器合并(register coalescing)。
在Scharwaechter等与Ahn等描述的两个做法里,复杂规则仅可以包含多个不关联的简单规则(即简单规则间没有共享节点)。在一篇2011年的论文里,它是【202】的修改与扩展,Youn等【243】通过为复杂规则的操作数说明引入索引下标来处理这个问题。不过,这些下标限制在模式的输入节点。因此完全任意的DAG模式仍然是不支持的。
Arnold与Corporaal【18,19,20】提出了另一个处理DAG模式的方法,在输出节点处将相联的单节点模式分解为多个部分树模式(参考图4.5)。 使用一个专有的O(n2)算法,在输入DAG上匹配树模式以找出所有模式实例。匹配之后,该算法尝试把不完全的模式实例恰当地组合合并为完整的复杂模式实例。通过维护一个将模式节点映射到输入DAG中被覆盖节点的数组,然后检查两个不完全模式是否属于同一个原始DAG模式且没有冲突,来实现每个模式实例。换而言之,在原始DAG模式中,没有两个对应同一个节点的模式节点会在输入DAG中覆盖不同的节点。选择通过传统的动态规划来完成,如果原始模式仅包含树,这是最优的,但在DAG模式的情形下产生次优的覆盖。这是因为最好的选中模式可能重叠,因此导致执行操作的重复。
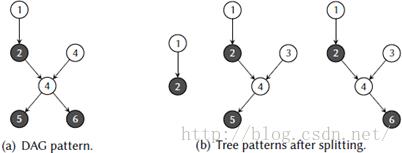
Farfeleder等【84】提出了一个类似的做法,通过应用一个LBURG的扩展版本进行树模式匹配,后跟一个遍尝试合并来自多输出机器指令的匹配模式。不过,第二个遍包含了专门的(ad-hoc)函数,且不是从机器描述自动推导的。
4.2.2. 直接DAG上的DAG匹配
在本报告的研究期间,没有找到直接在DAG上匹配DAG,同时仅限于DAG的方法。推测的原因是,执行DAG匹配与子图同构同样或几乎同样复杂。而后者更强大——比如它允许图带有循环边,将这样的匹配程序限制在DAG不必要也不合理。确实,正如我们将在本章看到的,几个面向DAG的方法将子图同构算法应用于模式匹配。
4.3. 归约模式选择为最大无关集问题
某些做法将模式选择问题解释为一个最大无关集(MIS)问题;我们已经在Scharwaechter等与 Ahn等的应用中看到这个思想(参考4.2.1节)。在本节我们将更深入地讨论这个技术。
对于在输入图中覆盖一个或多个节点的模式,可以形成一张对应的冲突或干涉图。图4.6给出了一个例子。在这个匹配的DAG里,显示在(a),我们看到模式p1与p2重叠,而模式p4与p2及p3重叠。对于每个模式,我们在冲突图C中产生一个节点,显示于(b),并在任意两个重叠模式间建立一条边。通过从C选择最大顶点集,使得没有被选中的节点在C中是相邻的,我们得到一组模式,使得在输入DAG中的每个节点得到覆盖,且没有重叠。正如所预期的,这个问题是NP完全问题。
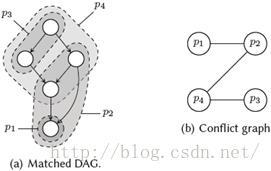
图4.6:一个匹配DAG及对应冲突图的例子
至于最优模式选择,在冲突图中,我们可以将模式代价作为一个权重附加给每个节点,并将MIS问题扩大为一个最大权重无关集(maximum weighted independent set,MWIS)问题,即选择最大顶点集S,使得它满足MIS且最大化Σs∈Sweight(s)。因为MWIS有一个最大化目标,我们只是将该模式代价的负数赋给每个权重。
Kastner等【140】开发了使用这个技术的一个方法,它瞄准指令集生成,配合混合可重配置系统。因此模式不作为一个输入给出,而作为问题本身的一部分生成。一旦生成了一个模式集,使用一个来自【71】的通用子图同构算法来找出输入DAG上所有的匹配(我们将在第五章讨论子图同构)。随后具现一个对应的MIS问题,启发式地解决。因为匹配算法不要求输入是一个DAG,该做法可以被扩展到任何基于图的输入。在该论文的一个扩展版本里,Kastner等【139】在快速排斥不相似子图方面改进了匹配算法。不过,结果代码可能是次优的,而且不清楚如何处理具有复杂限制的非常规架构。
Brisk等【33】也使用了MIS的思想在具有echo指令的架构上执行指令选择。Echo指令允许执行使用LZ77算法【247】压缩的程序。基本上,一个字符串可以通过使用指针替换字符串中之前出现的公共子字符串来缩短(即原来的字符串可以简单地通过拷贝黏贴来重建)。通过echo指令的使用,这个思想可以用于机器码。一条echo指令是援引程序前面再次执行部分的小记号,这减小了代码的大小。不过注意,这不会导致一个跳转或函数调用,因此更有效率。这也意味着模式集不是固定的,而是必须作为问题的部分来确定。就像Kastner等,Brisk等的做法也通过子图同构找出这些模式,但应用了另一个称为VF2的算法【57】。虽然这个算法在最坏情形下是O(nn!),作者报告对于实验中大多数的输入DAG,它运行得很有效率。通过聚集输入DAG中的相邻节点,形成了模式。使代码大小减少最多的模式被选中,并且通过将循环的模式实例替换为表示使用echo指令的新节点来更新输入DAG。重复这个过程直到没有发现优于某个用户定义值标准的新模式。
4.4. 其他基于DAG的做法
Hanono与Devadas【120,121】提出一个类似于Wess的格栅图思想(参考3.8节)的技术。实现在一个可重定位代码生成器AVIV中,该算法接受一个输入DAG,并将每个操作节点乘以可以运行该操作的功能单元数。数据流通过特殊的分裂节点汇聚起来。如果在两个功能单元间要求一个传输操作,该算法注入记入这个开销的传输节。那么指令选择被化简为在原始的输入DAG中,查找从根节点到每个叶子的一条路径。在这个情形下,Hanono与Devadas应用了一个贪婪的启发式来查找这些路径。不过,这个技术关注VLIW架构指令调度的最优化,因此通过假定DAG节点与机器指令一一对应来简化指令选择。
Sarkar等【200】开发了一个指令选择的贪心方法,目的在于最小化寄存器压力(register pressure)以方便调度与寄存器分配。因此,每条机器指令的开销不是执行周期数,而是反映它导致的寄存器压力(论文没有详细解释这些开销如何用公式表示)。指令选择通过输入DAG去dag化为树林(它被扩展为带有额外数据依赖的图),然后在每棵树上应用传统的树覆盖方法来完成。在确定在哪里执行这些分割时,应用了一个启发式。一旦选中,输入图中被复杂模式覆盖的节点被归约为超级节点,并检查归约图是否包含任何环。如果有,这个覆盖是非法的,因为它包含了环形的数据依赖。Sarkar等在Jalapeño里——IBM开发的基于寄存器的Java虚拟机实现并测试了他们的方法——显示比缺省指令选择器在小问题集上有10%的性能提升。
Bednarski与Kessler【25】考虑了一个使用ILP的代码生成的整合方式。不像他们以前的论文(【141,142】)主要考虑指令调度与寄存器分配,这个方法对指令选择应用了新奇的技术,值得回顾;特别的,他们将模式匹配问题整合入他们的ILP模型。我们将仅简短描述模型是怎么建立的(建议感兴趣的读者参考论文,那里有详细的解释)。大致上,ILP模型假设对于给定的输入DAG G,生成了足够数量的模式实例(这使用了一个计算上限的启发式)。对于每个模式实例p,该模型包含了计算变量(solution variables):
· 将p中的一个模式节点映射到G中的一个输入节点;
· 将p中的一条模式的边映射到G中一条输入边;并且
· 确定p是否被使用(记住我们可能有额外的模式实例,意味着它们不能被全部选中)。
因此,除了实施覆盖的典型线性不等式,该模型还包括确保模式实例有效匹配的等式。使用IBM CPLEX Optimizer【220】解析ILP模型,Bednarski与Kessler在OPTIMIST框架里实现了这个做法。为了评估,他们将他们的实现与一个整合的DP方法比较(也是由他们开发的;参见【141】),发现ILP方法显著地减少了代码生成的时间,同时产生同样质量的代码。不过,对于几个测试用例——最大的输入DAG仅包含33个节点——ILP方法无论如何都不能产生任何代码。因此不作进一步改进,这个技术看起来不适用于产品品质编译器。相同的做法也被Eriksson等【79】采用。
4.5. 总结
在这一章我们调查了几个以这种那种方式依赖DAG的方法。在DAG而不是树上操作有几个好处。最重要的,公共子表达式及多个输出的机器指令可以直接塑造,这使得DAG覆盖成为在现代编译器的指令选择中应用得最多的技术。
不过,将树转换到DAG的开销使最优指令选择不再能在线性时间内完成,因为这个问题是NP完全问题。同时,不是所有类型的输入与模式都可以被表示为DAG。例如,程序的循环导致了循环边,这将DAG覆盖限制在基本块作用域。这显然排除了实现循环计算的复杂机器指令,但更重要的,它还抑制了以不同数据形式及在函数内不同位置上保存变量或临时对象,以提升性能的优化机会。在下一章我们将看到这样的一个例子。最后,虽然某些方法处理包含不相连子模式的模式,比如SIMD指令,它们通常将每个子模式限制为非常简单的DAG(通常是单个节点)。
以上是关于指令选择器调查的主要内容,如果未能解决你的问题,请参考以下文章