shell脚本---grepawksed工具
Posted wanglelelihuanhuan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了shell脚本---grepawksed工具相关的知识,希望对你有一定的参考价值。
grep:Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。grep是一种查找过滤工具,正则表达式在grep中用来查找符合模式的字符串。
grep有三种变形:
1.grep:标准grep命令主要讨论此格式。
2.egrep:扩展grep,支持基本及扩展的正则表达式
3.fgrep:快速grep,允许查找字符串而不是一个模式。这里的快速并不是值速度快
格式
grep [options]
主要参数
[options]主要参数:
-c:只输出匹配行的计数。
-I:不区分大 小写(只适用于单字符)。
-h:查询多文件时不显示文件名。
-l:查询多文件时只输出包含匹配字符的文件名。
-n:显示匹配行及 行号。
-s:不显示不存在或无匹配文本的错误信息。
-v:显示不包含匹配文本的所有行。
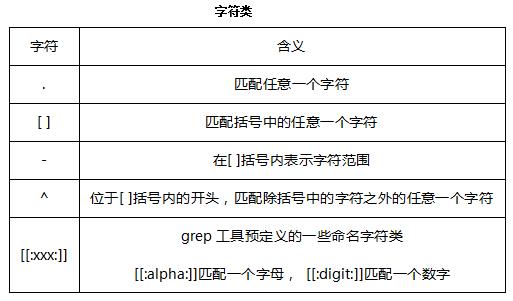
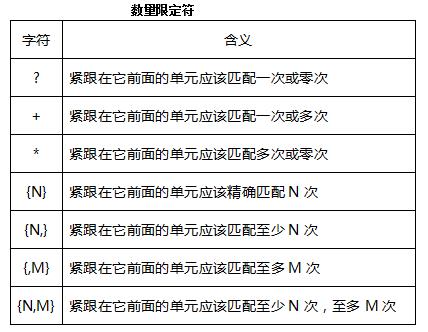

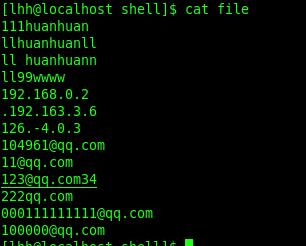

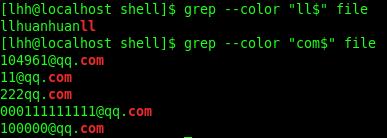


grep与正则表达式
规定一些特殊语法表示字符类、数量限定符和位置关系,然后用这些特殊语法和普通字符一起表示 一个模式,这就是正则表达式(Regular Expression)。

以上介绍的是grep正则表达式的Extended规范,Basic规范也有这些语法,只是字符?+{}|()应解释 为普通字符,要表示上述特殊含义则需要加\\转义
sed:流式编辑器,也就是把前一个程序的输出引入sed的输入,经过一系列编辑命令转换为另一种格式输出。
sed 是一种在线编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有 改变,除非你使用重定向存储输出。Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等。
格式:pattern/action 其中pattern是正则表达式,action是编辑操作。sed程序一行一行读出待处理文件,如果某一行 与pattern匹配,则执行相应的action,如果一条命令没有pattern而只有action,这个action将作 用于待处理文件的每一行。
命令和选项
sed命令告诉sed如何处理由地址指定的各输入行,如果没有指定地址则处理所有的输入行。
命令
a\\ :在当前行后添加一行或多行。多行时除最后一行外,每行末尾需用“\\”续行
c\\ :用此符号后的新文本替换当前行中的文本。多行时除最后一行外,每行末尾需用”\\"续行
i\\ :在当前行之前插入文本。多行时除最后一行外,每行末尾需用”\\"续行d删除行
h : 把模式空间里的内容复制到暂存缓冲区
H :把模式空间里的内容追加到暂存缓冲区
g :把暂存缓冲区里的内容复制到模式空间,覆盖原有的内容
G:把暂存缓冲区的内容追加到模式空间里,追加在原有内容的后面
l :列出非打印字符
p :打印行
n :读入下一输入行,并从下一条命令而不是第一条命令开始对其的处理
q :结束或退出sed
r :从文件中读取输入行
! : 对所选行以外的所有行应用命令
s :用一个字符串替换另一个
g :在行内进行全局替换
w :将所选的行写入文件
x :交换暂存缓冲区与模式空间的内容
y :将字符替换为另一字符(不能对正则表达式使用y命令)
选项
-e :进行多项编辑,即对输入行应用多条sed命令时使用
-n :取消默认的输出
-f :指定sed脚本的文件名
1. /pattern/p :打印匹配pattern的行
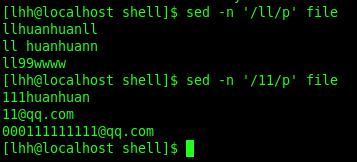
2. /pattern/d :删除匹配pattern的行
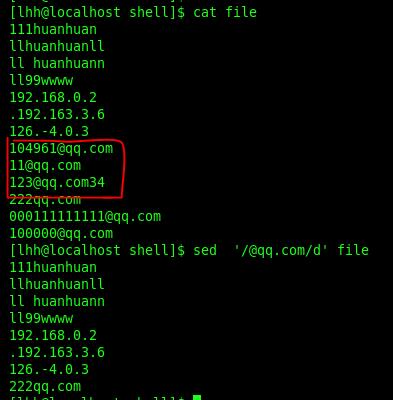
注意:sed命令不会修改原文件,删除命令只表示某些行不打印输出,而不是从原文件中删去。
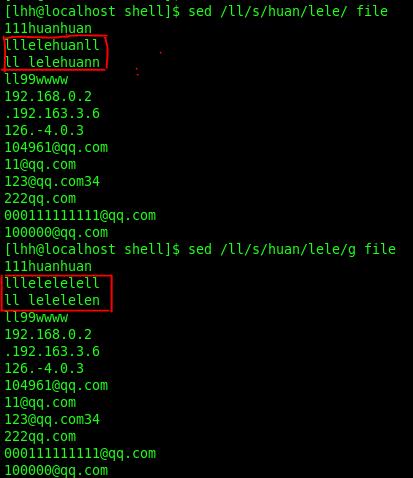
3. /pattern/s/pattern1/pattern2/:查找符合pattern的行,将该行第一个匹配pattern1的字符串替换为pattern2
4. /pattern/s/pattern1/pattern2/g:查找符合pattern的行,将该行所有匹配pattern1的字符串替换为pattern2
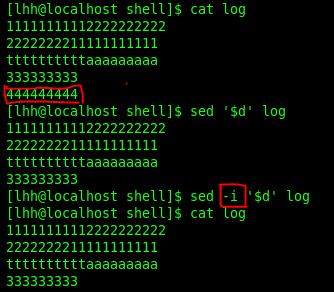
5. sed -i : 做的操作会修改原文件
6.定址
sed -n ‘3p’ file #打印第三行
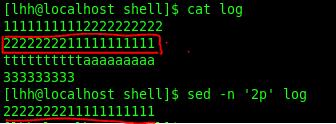
sed ‘2,5d’ file #删除第二行到第五行
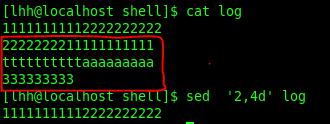
7. 退出状态
sed不像grep一样,不管是否找到指定的模式,它的退出状态都是0。只有当命令存在语法错误时,sed的退出状态才不是0。
sed与正则表达式
与grep一样,sed也支持特殊元字符,来进行模式查找、替换。不同的是,sed使用的正则表达式是括在斜杠线"/"之间的模式。
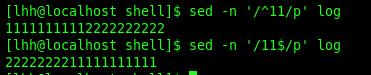
^:行首定位符:/^11/ 匹配所有以11开头的行
$:行尾定位符:/11$/ 匹配所有以11结尾的行
&:保存查找串以便在替换串中引用:s/333333/*&*/g 符号&代表查找串。

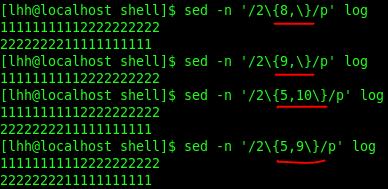
x\\{m\\}:连续m个x

x\\{m,\\}:至少m个x
x\\{m,n\\}:至少m个,但不超过n个x
awk:是一种用于处理文本的编程语言工具。AWK 实用工具的语言在很多方面类似于 shell 编程语言,尽管 AWK 具有完全属于其本身的语法。在最初创造 AWK 时,其目的是用于文本处理,并且这种语言的基础是,只要在输入数据中有模式匹配,就执行一系列指令。该实用工具扫描文件中的每一行,查找与命令行中所给定 内容相匹配的模式。如果发现匹配内容,则进行下一个编程步骤。如果找不到匹配内容,则继续处理下一行。,awk比sed强的地方在于不仅能以行为单位还能以列为单位处理文件。awk缺省的行分隔符是换行,缺省的列分隔符是连续的空格和Tab,但是行分隔符和列分隔符都 可以自定义。
awk命令行的基本形式为:
awk option 'script' file1 file2 ...
awk option -f scriptfile file1 file2 ...
和sed一样,awk处理的文件既可以由标准输入重定向得到,也可以当命令行参数传入,编辑命令可以直接当命令行参数传入,也可以用-f参数指定一个脚本文件,编辑命令的格式为:
/pattern/{actions}
condition{actions}
实用工具将每个输入行分为记录和字段。记录是单行的输入,而每条记录包含若干字段。默认的字段分隔符是空格或制表符,而记录的分隔符是换行。虽然在默认情况下将制表符和空格都看作字段分隔符(多个空格仍然作为一个分隔符),但是可以将分隔符从空格改为任何其它字符。当 AWK 读取输入内容时,整条记录被分配给变量 $0。每个字段以字段分隔符分开,被分配给变量 $1、$2、$3 等等。一行在本质上可以包含无数个字段,通过字段号来访问每个字段。
自动变量$1、$2分别表示第一列、第二列等,类似于Shell脚本的位置参数,而$0表示整个当前行。
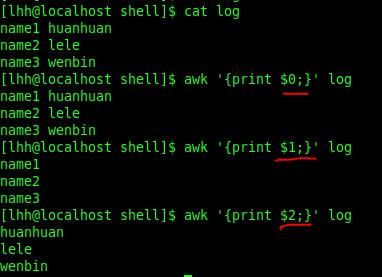
在awk 中两个特别的表达式,BEGIN和END,这两者都可用于pattern中,提供BEGIN和END的作用是给程序赋予初始状态和在程序结束之后执行一些扫尾的工作。任何在BEGIN之后列出的操作(在{}内)将在awk开始扫描输入之前执行,而END之后列出的操作将在扫描完全部的输入之后执行。因此,通常使用BEGIN来显示变量和预置(初始化)变量,使用END来输出最终结果。


awk调用方式
1.命令行方式
awk [-F field-separator] 'commands' input-file(s)
其中,commands 是真正awk命令,[-F域分隔符]是可选的。 input-file(s) 是待处理的文件。
2.shell脚本方式
将所有的awk命令插入一个文件,并使awk程序可执行,然后awk命令解释器作为脚本的首行,一遍通过键入脚本名称来调用。
相当于shell脚本首行的:#!/bin/sh
可以换成:#!/bin/awk -f
3.将所有的awk命令插入一个单独文件,然后调用:
awk -f awk-script-file input-file(s)
其中,-f选项加载awk-script-file中的awk脚本
以上是关于shell脚本---grepawksed工具的主要内容,如果未能解决你的问题,请参考以下文章