ceph 译文 RADOS:A Scalable, Reliable Storage Service for Petabyte-scale Storage Clusters
Posted Jason__Zhou
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ceph 译文 RADOS:A Scalable, Reliable Storage Service for Petabyte-scale Storage Clusters相关的知识,希望对你有一定的参考价值。
RADOS:A Scalable, Reliable Storage Service for Petabyte-scale Storage Clusters
论文翻译
摘要
块式和面向对象的存储架构形成了一种以提升扩展性的存储cluster。然而,现存的系统继续把存储节点作为一个被动的设备,尽管他们有能力展示智能和自治。我们提出RADOS的设计和实现,RADOS是一个可靠的面向对象服务,通过利用每个独立节点的智能可以扩展到数千台设备。当允许节点半自治地通过利用集群地图来进行自我复制,错误检测,错误恢复,RADOS保护数据的一致性和强壮的安全语义。我们的实现提供了极好的性能,可靠性,可扩展性,同时,提供给客户端一个逻辑的对象存储。
1 介绍
提供可靠的高性能的规模不断扩大的存储给系统设计者们带来了挑战。高吞吐和低延时的面向文件系,数据库和相关抽象的存储对广泛的应用来说是很重要的。基于砖式存储或者对象存储设备(OSD)的聚合集群存储架构正在寻求将低层次的块分配解决方案和安全强制措施分布到智能化存储设备上,从而,通过促进客户端直接访问数据来解决智能化存储设备,简化数据分布和消除IO瓶颈的相关问题。基于商用组件的OSD结合了CPU,网络接口,本地缓存,基础的磁盘或者RAID,把基于块设备接口的存储替换为一个基于命名的变长的对象。
然而,采取这种架构的大规模系统地无法利用设备的智能。因为协议化的存储系统是基于本地或者存储网络的存储设备或者这些兼容T10OSD协议的设备,设备被动地相应读写命令,尽管他们有潜力封装明显的智能。当存储集群增长到数千节点或者更多时,数据迁移的一致性管理,错误检测,错误恢复将给客户端,控制器,元数据目录节点带来极大的压力,限制了可扩展性。
我们已经设计并实现了RADOS,一个可靠的自动的分布式对象存储,它能寻求将设备智能分布到复杂的涉及数据一致性访问,冗余存储,错误检测和恢复登问题的数千节点规模的集群。作为Ceph分布式系统的一部分,RADOS促成了一个优化的平衡的分布式数据和负载,这些数据和负载分布在动态的不均匀的存储集群上,与此同时,RADOS为applications提供一个单一的具有良好的安全语义和强一致保障的逻辑对象存储。
对于PB级的规模,存储系统动态化是有必要的:它们被动态的扩建,它们增长并且与新部署的存储建立联系或使老设备退役,设备出错和恢复是基于连续的数据基础,大量的数据被建立和删除。RADOS确保数据分布对系统的一致性,以及基于cluster map的对象读写的一致性。这个map被复制到所有的节点上(存储和客户端节点),并且被Lazy propagation的增量更新。
通过提供给存储节点以完整的数据在系统中的分布信息,设备能够半自治地通过类似点对点的协议来自我管理数据复制,一致和安全的过程更新,参与错误检测,及时响应错误和数据对象复制迁移带来的数据分布变化。这减轻了管理着cluster map主副本的小型monitor集群上的压力,从而,使得剩余的存储集群能够是系统无缝地从几十个节点扩展到数千个节点。
我们的prototype实现提供可供在byte范围可读写的对象接口(就像文件那样),因为那是我们最原始的Ceph的需求。为了防止节点错误和保护数据对象,在OSD集群中数据对象通过N条路被复制。然而,RADOS的可扩展性无法依赖在特定的对象接口或者冗余策略;存储Key-Value的对象和RAID冗余都被计划中。
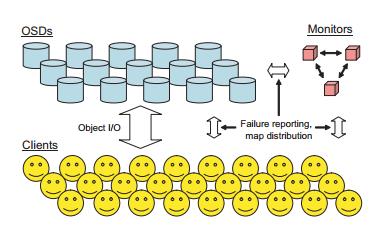
2 可扩展的集群管理
一个RADOS的系统包括含有大量OSD节点的集合加上一个规模小的负责管理OSD cluster membership的Monitor 集合。每一个OSD节点包括一个CPU,一些易失性内存,一个网络接口和本地磁盘或者RAID。Monitors是有单机进程并且需要少量的本地存储。
2.1 Cluster Map
Monitor集群通过管理Cluster Map从而使存储集群被互斥地管理。Cluster Map指定了集群包括哪些OSDs,并简洁地指定了全体数据在系统中的分布。Cluster Map被每一个存储节点和那些与RADOS系统交互的客户端所复制。因为Cluster Map完整地指定了数据分布,客户端提供一个简单的接口用来把整个存储集群(可能一万个节点)虚拟成一个单一的逻辑对象存储。
每一次因为OSD状态变化(例如设备错误)或者其他的触发数据分布的事件所引起的Cluster Map的改变,都会触发map epoch递增。Map epochs允许通信双方约定当前的数据分布是什么,决定什么时候他们的信息超时。因为Cluster Map改变很频繁,在非常大的集群中OSDs错误检测和恢复很平常更新和分发map 增量(Cluster Map):小信息来表述两个成功的map epoch间的差异。在大多数情况,这些更新只是说明了一个或者多个OSD节点出错或者错误恢复,尽管一般情况这些更新可能包括很多设备的状态改变,很多更新被集中捆绑以便描述间隔比较长的的map版本。
2.2 数据放置
RADOS使用一种将数据伪随机地分布到设备的协议。当新的设备被添加,一个随机的现存数据的副本将迁徙到新的设备上以实现负载均衡。这种策略使系统维护了一定概率的均衡分布,基本上,保持所有的设备有相似的负载,允许系统在任何可能的负载下都能很好的运行。最重要的,数据复制是一个两阶段的过程,计算了正确的对象存储位置;而且不需要一个大型且笨重的集中分配表。
每个存在系统的对象首先先被映射到放置组(Placement Group),一个被同一组的设备复制的逻辑对象集合。每个对象的PG是由对象名o的Hash值,数据主从复制的等级r,和一个控制PG总数的位掩码m来决定的。那么说,pgid=(r,hash(o)& m),m = 2的k次方 - 1,从而限制PG的数量是2的N次方。
对于集群来说,它是周期性的必要, 通过改变m来调整放置组的总数,这是逐渐进行的来减少设备间的PG的迁移.
基于Cluster Map,Placement Group被分配给OSD节点,每个PG被映射到有序的包含r个OSD节点的链表中,数据副本将存储在这些映射的PG上。我们的实现利用了CRUSH,一个鲁棒性的副本分布算法,用来计算出稳定的,伪随机地映射。(其他可能的复制策略;对于超大型集群,即使是一个映射PG到设备的表也仍然相对较小(MB级。)从高层上看,CRUSH的行为类似于HASH函数:Placement Groups是确定且是伪随机分布的。和Hash函数不同的是,CRUSH是稳定的:当一个节点加入或者离开集群,PGs仍然在原来的存储位置不变;CRUSH只转移足够的数据来维护一个均衡的分布。相对的,HASHING更倾向于强制地对主要的映射进行重新洗牌。CRUSH也会通过权值控制那些基于容量和性能被分配到每个设备的数据。
PG提供了一种方法控制副本分布策略的级别,分布析散(replication declustering)。也就是说,一个OSD不是与另外一个或者多个设备共享所有副本(镜像),也不是与其他不同的设备共享每个对象(complete declustering),副本Peer数量与它存储的PG数量u有关,典型的是顺序100PG每个OSD。由于分布是随机的,u也会影响设备利用率的方差:OSD上的PG越多分布越均衡。更重要的是,declustering有利用分布式,通过允许每个PG独立被重新复制到其他OSD可以并行错误恢复。在同一时间,系统可以限制同时出现故障的设备,通过限制每个设备共享相同数据的数量。
2.3 Device State 设备状态
Cluster Map中包含了设备的描述信息,设备状态信息,以及数据分布信息。包含所有OSD的当前在线的网络地址,并指明哪些设备是不可达的(down)。RADOS会把OSD的活跃度考虑进去。
对于每个PG,CRUSH会从mapping中找到r个OSD。RADOS然后会过滤掉那些down状态的设备,为PG产生一个avtive状态的OSD列表。如果这个active列表是空的,PG数据就会不可用,IO就会被Block。
对应活跃的IO服务,OSD通常是up和in状态。如果它出错,应该是down和out状态,产生一个actvie列表对应 r个OSD。OSD也可能处在down但是仍然是in 某个Mapping,意味着他们目前是不可达的,但是PG数据还没有被remapped到其他OSD(类似于degraded mode在RAID系统中)。反过来,它们也可能是up和out状态,意味着他们是在线的,但是仍然处在空闲状态。这有利于应对各种场景,包括对间歇性的不可用容忍(例如:OSD重启或网络间歇性中断)而不初始化任何数据迁移;新的部署存储而暂时不使用(例如:用来测试),并且在就设备推出前,将数据安全的迁移出去。
2.4 Map传播(Map Propagation)
由于RADOS集群坑内包含成千上万的设备,简单的广播Map更新消息到每个节点是不实际的。幸运的是不同ma版本的不同是很明显的,只有当两个通信的OSD(或者一个客户端和OSD)不同时,他们才会根据适当的规则更新。这个特性可以是RADOS分发延迟分发Map更新,通过经OSD内部消息结合,高效的转移分布负载。
每个OSD都会维护map更新的历史记录,为每个消息带一个epoch的tag,并持续跟踪出现在每个peer中的最新的epoch。如果OSD接收到一个peer带来一个老的map,它就会将必要的增量带给这个peer以保持同步。类似的当发送peer有一个老的map,增量更新也会从对端共享。心跳消息会周期的交换以检测异常保证更新快速扩散,对于一个有n个OSD的集群,用到的时间为O(logn)。
例如,当一个OSD启动时,它会通过OSDboot消息通知一个monitor,这个消息中包含了其最新的map epoch。Monitor集群更新该OSD的状态为up,然后将更新后的cluster Map带给该OSD,当这个新的OSD与其他OSD通信时,这个状态更新后的Map就会共享给这些OSD。因为这个新OSD不知道其他Peer拥有的epoch,它会共享一个安全的当前增量更新历史。
这种Map共享机制是保守的:一个OSD与其他Peer联系时都会共享和更新Map,另外,当这个peer以及看到它时,就会导致OSD接收到充分的更新信息。然而,一个OSD接收到重复的Map的数量是与它有多少Peer有关,这个数量又由它管理PG的数量u决定。实际情况下,我们发现update重复的级别原少于这个值。
3 智能存储设备
数据分布的信息封装在了Cluster Map中,这使得RADOS可以将存储集群的数据冗余管理、故障检测和故障恢复分布到各个OSD上。通过采用类似P2P的协议,在高性能的集群环境中,充分利用了OSD节点的智能性。
RADOS实现了结合每个对象版本和短的日志的多路复制。复制是由OSD自己完成的:客户端只会提交一个写的操作到主OSD,主OSD复制一致性和安全更新所有副本。这样移动和复制相关的操作利用的是存储集群内部的网络带宽,同时这样也可以简化客户端的设计。对象版本和日志有助于节点故障时快速恢复。
我们将主要描述RADOS集群架构,特别是Cluster Map是如何将复制和故障恢复分布化,已经如何将这个能力推广到引入其他冗余机制(例如基于RAID码的分片)。

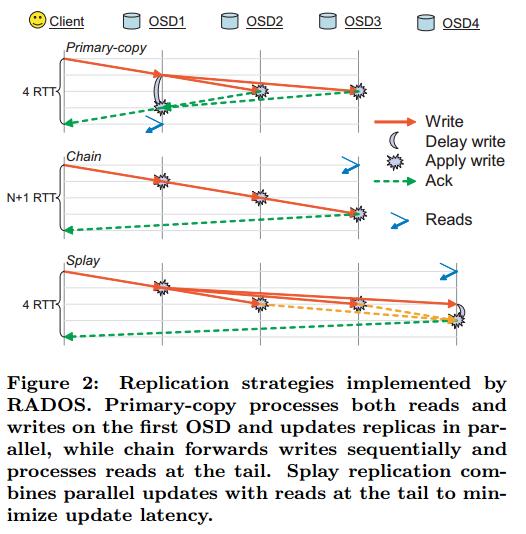
图2
3.1 复制
RADOS实现了三种不同的复制策略:Primary copy、chain、splay。更新操作的消息交换可以参考图2。在所有的情况下,客户端发送IO操作到一个OSD,集群来保证副本能够安全地更新以及一致性的读和写。一旦所有的副本被更新,就会返回一个ACK消息给客户端。
Primary-copy 复制并行地更新所有的副本,并处理读和写在primary OSD。Chain采用串行更新的方式:当写命令发送给Primary节点,而读命令发送给Tail节点,保证read总是可以反映整个副本的更新。Splay是将Primary-copy中的并行更新和chain-copy中的读写角色分离想结合,这个好处是减少了消息的跳数对于两路镜像。
3.2 强一致性
所有的RADOS消息(包括从客户端发起的消息,以及从其他OSD发起的消息)都携带了发送端的map epoch,以保证所有更新操作都能够在最新的版本上保持一致。如果一个客户端因为使用了一个过期的map,发送一个IO到一个错误的OSD,OSD会回复一个适当的增量,客户端再重新发送这个请求到正确的OSD。这就避免了主动共享map到客户端,客户端会在与Cluster联系的时候更新。大部分时候,他们都会在不影响当前操作的时候学到更新,让接下来的IO能够准确的定位。
如果cluster map的主拷贝已经更新,改变了一个特定的PG的成员,老的成员仍然可以处理更新,就像没有感觉到变化一样。如果这个改变先被一个PG副本节点知道,它将被发现,当主OSD转发更新消息到副本节点,副本节点就会返回map的增量给主OSD。这是完全安全的,因为任何新负责一个PG的一组OSD都需要与之前负责这个PG的OSD联系,以保证PG的内容是正确的,这样就可以保证之前的OSD能够学到这个Map的改变,并在新的OSD接手之前停止执行IO操作。
完成类似读的一致性操作会没有更新那么自然。当网络故障时,会导致一个OSD部分不可达,为某个PG提供读服务的OSD可能被标记为故障,但是可能对那些拥有过期的map的client是可达的。同时,更新后的map可能指定了一个新的OSD。为了避免新的更新由一个新的OSD处理后,老的OSD还能处理接收到的读操作,我们需要周期性的心跳报文,在那些负责相同PG的OSD之前,为了保持这个PG是可读的。如果一个提供读的OSD在H秒钟没有听到其他副本的心跳报文,读操作就会被阻塞。在其他OSD接收一个PG的主要角色前,他必须获得老的OSD的确认(保证它们都知道自己的角色发生了变化),或延迟一定的时间间隔。目前的实现,我们采用2秒钟一个相对较小的心跳间隔。这可以抱着故障可以及时的被侦测,并且当主OSD故障是可以保证数据不可用的时间很短。
3.3 故障检测
RADOS采用一种异步、有序点到点的消息传递库进行通信。当TCP套接字发生故障是会导致有限次的重新连接尝试,然后才报告monitor集群。存储节点会周期性的交换心跳报文与他们的对端(那些与他们共享相同PG数据的OSD),以保证设备故障能够及时侦测到。当OSD发现他们已经被标记成为down状态,会同步硬盘数据,然后将kill自己保证行为的一致性。
3.4 数据迁移和故障恢复
RADOS数据迁移和故障恢复完全是由Cluster Map的更新和PG到OSD映射改变驱动的。这个改变可能是由于设备故障、恢复,集群扩展或收缩,已经有一新的CRUSH策略导致所有数据的重新分布。设备故障只是许多可能引起建立新的集群数据分布的一个原因之一。
RADOS没有对数据连续性做任何假设。在所有情况下,RADOS采用了一个鲁棒性peering算法,通过这个算法可以建立一个一致性的PG内容视图,并且可以恢复适当的数据分布和复制。这个策略依赖的基本的设计前提是OSD采用积极复制一个PG的日志,这个记录了一个PG当前内容是什么(即:包含的对象的版本),即使当前对象副本可能本地丢失。因此,即使恢复很慢,一些时候对象安全被降级,PG的元数据能够被保证,从而简化了恢复算法,并且允许系统检测到数据丢失。
3.4.1 Peering
当一个SD接收到一个Cluster Map更新,它会遍历所有先的Map增量,通过最近的检查和可能的调整PG的状态值。任何本地存储的PG的atcive list中的OSD发生改变必须重新re-peer。考虑到所有的map epoch(不只是最近的),确保中间数据分布要被考虑:如果一个OS从一个PG移除,然后有加入进来,要确认PG的内容可能在中间发生更新,这一点很重要。与复制、对等以及其他后续的更新对系统中的每个PG进行处理。
Peering是由OSD中的Primary OSD驱动的。对于每个PG不是Primary的OSD,通知消息都发送给primary OSD。这个消息包括:本地存储的PG的基本状态信息,包括最近的更新,一定范围的PG日志信息,已经最近知道的epoch。通知消息保证一个新的primary OSD对于一个PG能够发现他的新的角色,不用考虑所有可能的PG(可能有几百万个)对于每个map改变。一旦知道这些,Primary OSD就可以生成一个prior set,其包含了所有加入到这个PG的OSD,因为刚刚与这些成功建立peer关系。这个prior set可以被显式查询以达到一个稳定状态,避免对一个OSD没有政治存储这个PG的无限等待。
有了PG现有集的元数据,Primary OSD就能够决定应用于任何副本的最近更新,并且知道从prior OSD请求哪段log片段,以便是PG日志在active副本上得到更新。如果一个可用的PG日志是不充足的(例如,一个或多个OSD没有PG数据),一个完整的PG内容就会生成。对于节点重启或者其他端的中断,为了足够快的同步副本PG日志是有足够的信息。
最好,Primary OSD与其他replica OSD 共享缺失的日志片段,所有replica知道都知道PG中包含哪些对象(即使他们本地还没有保存这个对象),这样就可以在后台执行恢复进程。
3.4.2 恢复
Declustered replication的一个重要的优势是能够进行并行的故障恢复。任何单一故障的设备共享分布在其他OSD的副本,每个PG可以独立选择替换和允许重新复制一样多的OSD。平均而言,在一个大的系统中,任何一个单一故障恢复的OSD,可以采用Push和Pull的方式复制内容,是故障恢复的速度非常快。Recovery可以被激发通过观察IO读是否被限制。虽然每个独立OSD都拥有所有的PG元数据,可以独立的获取每个缺失的对象,但这个策略有两个限制。一个是多个OSD分布恢复在相同PG中的对象,这可能在相同时间,不会去下载在相同OSD上的相同对象。这可能导致最大的恢复开销是Seeking和Reading。另外,如果replica OSD缺失对象被改变,这个副本更新协议可能会变得很复杂。
基于这个原因,RADOS中的PG恢复是由primary OSD协调的。和之前类似,知道主OSD有一个本地拷贝后才对缺失的对象进行操作。因为Primary OSD通过peering的过程已经知道了所有replicas缺失哪些对象。它可以将任何对象推送到replica OSD,简化的复制楼价也保证了这在拷贝的对象只能读一次。如果主 OSD正在推送一个对象或者它已经刚刚下载了一个对象,它将总是会推送给所有replicas。因此,每个被复制的对象只读一次。
4 监视器
Monitors是一个小的集群,通过存储Cluster Map的主Copy,并周期性的更新配置的改变和OSD状态,管理整个存储系统。集群是建立在Paxos part-time parliament算法的基础上,这个算法有利与可用性和更新延迟的一致性和持久性。值得注意的是,大部分Monitors必须是可用的,为了保持Cluster Map的读取和更新,以及Cluster Map的改变能够持久性。
4.1 Paxos Service
集群是基于分布式状态机服务,基于Poxos,Cluster Map是当前的集群状态,并且每次更新都会到只一个新的Map epoch。实现轻微地简化了标准的Poxos,通过任何时候只允许一个突变对于当前的Map。将基本的Paxos算法与租约机制相结合,允许任何monitor之前直接请求,确保读和更新按照一致的顺序。集群初始化选出的一个领导这能够序列化Map更新和管理一致性。一旦被选出来,Leader就会请求每个monitor上的所有map epoch。Monitor有一个固定的时间探测和家人到quorum。如果大多数monitor是active的,Poaxos算法的第一阶段能够保证每个Monitor有一个最近提交的map epoch,然后分发短的租约到没有active monitor。每个租约都会授权给active monitor想OSD和Client分发他们请求的Cluster Map拷贝的权利。如果租约T超时,并没有更新,就认为leader已经故障,就重新进行选举。当收到租约时要给leader发送确认消息。如果leader没有及时收到确认消息,他就假设这个active monitor已经崩溃,重新选举建立一个新的quorum。当一个monitor第一次启动,或者过了一定时间间隔后之前的选举没有完成,都会激发重新选举。
当一个active monitor接收到一个更新请求(例如一个错误报告),它会先看一下这个请求是否是新的。例如一个OSD已经被标记为down,这个monitor就会给发送这个消息的OSD相应的Map增量。新的报错会转发给Leader,leader会初始化Map更新通过增加Map epoch,并使用Paxos 更新协议将共享分发给其他Monitor,同时撤销租约。如果更新被大部分Monitor确认,最后会提交新的租约消息。
一个两个阶段的指派和周期性的探测可以保证,是否active monitor集合改变,它保证所有当前的租约,在Map更新时过期。因此,任何顺序的Map更新查询和更新都能够在一个Map版本上一致的进行。重要的是Map的版本将永远不会回退,只要大部分monitor是是可用的,无论哪个Monitor消息被发送到或任何干预Monitor的错误。
4.2 工作负载和可扩展性
通常情况下,Monitor工作负载是很小的,大部分Map分发是由Storage Node完成的,设备状态的改变也是不经常发生的。
Monitor集群采用的租约机制,可以允许任何Monitor可以从OSD或者Client请求Cluster Map拷贝。这种请求很少由OSD发起,因为抢先的Map共享,Client通常请求Update只发生在OSD操作超时,或者可能发生错误的时候。Monitor集群能够分发这些复制到更大的集群。
需要Map update的请求会被转发给当前的Leader。Lead会汇集多个根系到一个Map更新,Map Update的频率是可以调节的,而且是与Cluster的大小不相关的。尽管如此,最坏的负载发生在,当大量的OSD在一个短时间内同时发生故障。如果一个OSD存放了u个PG,并且有f个OSD故障,就会有最多uf个错误报告产生。当OSD比较大时,这些消息会非常多。为了防止消息饭量,OSD会在伪随机的时间间隔发送心跳报文,保证陆续检测到这些错误,压制和分配的报告错误。那些不是Leader的monitor只会针对一个报错转发一次,这样Leader的请求负载就相应的为fm,其中m为集群中monitor的数量。
5 部分评估
通过使用对象存储层(EBOFS)的性能,结合ceph到每个OSD性能已经被预先测量. 同样,数据分配性能CRUSH以及它们对总吞吐量集群效应在别处已经评估过。在这短短的文章中,我们只注重map分配,因为这会直接影响集群的扩展能力。我们还没有实验评估监控群集性能,虽然我们信心架构的可扩展性。
5.1 Map 传播
rados分布算法在2.4节已经讲过了,map更新logn次便可以更新完毕.
当集群增多,设备故障就好更加频发,更新次数就好增加.因为map更新和交互只发生在共享相同PG的OSD间,上限正比于单个OSD接收上的副本个数.
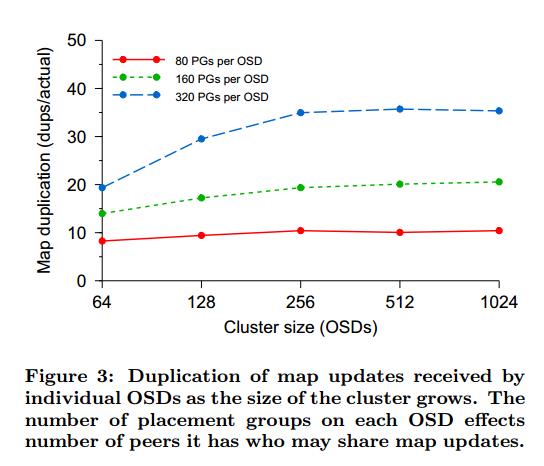
In simulations under near-worst case propagation circumstances with regular map updates, we found that update duplicates approach a steady state even with exponential cluster scaling. In this experiment, the monitors share each map update with a single random OSD, who then shares it with its peers. In Figure 3 we vary the cluster size x and the number of PGs on each OSD (which corresponds to the number of peers it has) and measure the number of duplicate map updates received for every new one (y).Update duplication approaches a constant level—less than 20% of μ—even as the cluster size scales exponentially, implying a fixed map distribution overhead.
We consider a worst case scenario in which the only OSD chatter are pings for failure detection, which means that, generally speaking,OSDs learn about map updates (and the changes known by their peers) as slowly as possible. Limiting map distribution overhead thus relies only on throttling the map update frequency, which the monitor cluster already does as a matter of course.
6 未来工作
6.1 Key-value 存储
6.2 可扩展的FIFO队列
6.3 对象的粒度快照
6.4 服务质量
6.5 基于奇偶校验的冗余
7参考:
[1]Ceph学习–RADOS论文
http://www.yidianzixun.com/news_10373a5b3e9591ba337dc85059854d90
[2]RADOS论文
http://blog.csdn.net/agony000/article/details/22697283
[3]RADOS:一种可扩展高可用的PB级存储集群(Ceph)
http://blog.csdn.net/user_friendly/article/details/9768577
[4]Weil S A, Leung A W, Brandt S A, et al. RADOS: a scalable, reliable storage service for petabyte-scale storage clusters[C]// International Workshop on Petascale Data Storage: Held in Conjunction with Supercomputing. ACM, 2007:35-44.
以上是关于ceph 译文 RADOS:A Scalable, Reliable Storage Service for Petabyte-scale Storage Clusters的主要内容,如果未能解决你的问题,请参考以下文章