HBase二级索引与Join
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase二级索引与Join相关的知识,希望对你有一定的参考价值。
转自:http://www.oschina.net/question/12_32573
二级索引与索引Join是Online业务系统要求存储引擎提供的基本特性。RDBMS支持得比较好,NOSQL阵营也在摸索着符合自身特点的最佳解决方案。
这篇文章会以HBase做为对象来探讨如何基于Hbase构建二级索引与实现索引join。文末同时会列出目前已知的包括0.19.3版secondary index, ITHbase, Facebook和官方Coprocessor方案的介绍。
理论目标
在HBase中实现二级索引与索引Join需要考虑三个目标:
1,高性能的范围检索。
2,数据的低冗余(存储所占的数据量)。
3,数据的一致性。
性能与数据冗余,一致性是相互制约的关系。
如果想实现了高性能地范围检索,必然需要依赖冗余索引数据来提升性能,而数据冗余会导致更新数据时难以实现一致性,特别是分布式场景下。
如果对范围检索的性能要求不高,那么可以不考虑冗余数据,一致性问题也可以间接避免,毕竟share nothing是公认的最简单有效的解决方案。
理论结合实际,下文会以实例的方式来阐述各个方案是如何选择偏重点。
这些方案是经过笔者资料查阅和同事的不断交流后得出的结论,如有错误,欢迎指正:
1,按索引建表
每一个索引建立一个表,然后依靠表的row key来实现范围检索。row key在HBase中是以B+ tree结构化有序存储的,所以scan起来会比较效率。
单表以row key存储索引,column value存储id值或其他数据 ,这就是Hbase索引表的结构。
如何Join?
多索引(多表)的join场景中,主要有两种参考方案:
1,按索引的种类扫描各自独立的单索引表,最后将扫描结果merge。
这个方案的特点是简单,但是如果多个索引扫描结果数据量比较大的话,merge就会遇到瓶颈。
比如,现在有一张1亿的用户信息表,建有出生地和年龄两个索引,我想得到一个条件是在杭州出生,年龄为20岁的按用户id正序排列前10个的用户列表。
有一种方案是,系统先扫描出生地为杭州的索引,得到一个用户id结果集,这个集合的规模假设是10万。
然后扫描年龄,规模是5万,最后merge这些用户id,去重,排序得到结果。
这明显有问题,如何改良?
保证出生地和年龄的结果是排过序的,可以减少merge的数据量?但Hbase是按row key排序,value是不能排序的。
变通一下 – 将用户id冗余到row key里?OK,这是一种解决方案了,这个方案的图示如下:
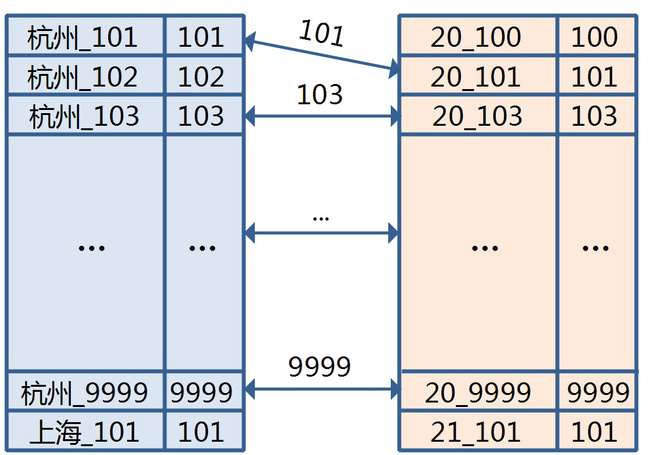
merge时提取交集就是所需要的列表,顺序是靠索引增加了_id,以字典序保证的。
2, 按索引查询种类建立组合索引。
在方案1的场景中,想象一下,如果单索引数量多达10个会怎么样?10个索引,就要merge 10次,性能可想而知。

解决这个问题需要参考RDBMS的组合索引实现。
比如出生地和年龄需要同时查询,此时如果建立一个出生地和年龄的组合索引,查询时效率会高出merge很多。
当然,这个索引也需要冗余用户id,目的是让结果自然有序。结构图示如下:

这个方案的优点是查询速度非常快,根据查询条件,只需要到一张表中检索即可得到结果list。缺点是如果有多个索引,就要建立多个与查询条件一一对应的组合索引,存储压力会增大。
在制定Schema设计方案时,设计人员需要充分考虑场景的特点,结合方案一和二来使用。下面是一个简单的对比:
| 单索引 | 组合索引 | |
| 检索性能 | 优异 | 优异 |
| 存储 | 数据不冗余,节省存储。 | 数据冗余,存储比较浪费。 |
| 事务性 | 多个索引保证事务性比较困难。 | 多个索引保证事务性比较困难。 |
| join | 性能较差 | 性能优异 |
| count,sum,avg,etc | 符合条件的结果集全表扫描 | 符合条件的结果集全表扫描 |
从上表中可以得知,方案1,2都存在更新时事务性保证比较困难的问题。如果业务系统可以接受最终一致性的话,事务性会稍微好做一些。否则只能借助于复杂的分布式事务,比如JTA,Chubby等技术。
count, sum, avg, max, min等聚合功能,Hbase只能通过硬扫的方式,并且很悲剧,你可能需要做一些hack操作(比如加一个CF,value为null),否则你在扫描时可能需要往客户端传回所有数据。
当然你可以在这个场景上做一些优化,比如增加状态表等,但复杂性带来的风险会更高。
还有一种终极解决方案就是在业务上只提供上一页和下一页,这或许是最简单有效的方案了。
2,单张表多个列族,索引基于列
Hbase提供了列族Column Family特性。
列索引是将Column Family做为index,多个index值散落到Qualifier,多个column值依据version排列(CF, Qualifer, Version Hbase会保证有序,其中CF和Qualifier正序,Version倒序)。
举个典型的例子,就是用户卖了很多商品,这些商品的标题title需要支持like %title%查询。传统基于RDMBS就是模糊查询,基于search engine就是分词+倒排表。
在HBase中,模糊查询显然不满足我们的要求,接下来只能通过分词+倒排的方式来存储。基于CF的倒排表索引结构见下图:
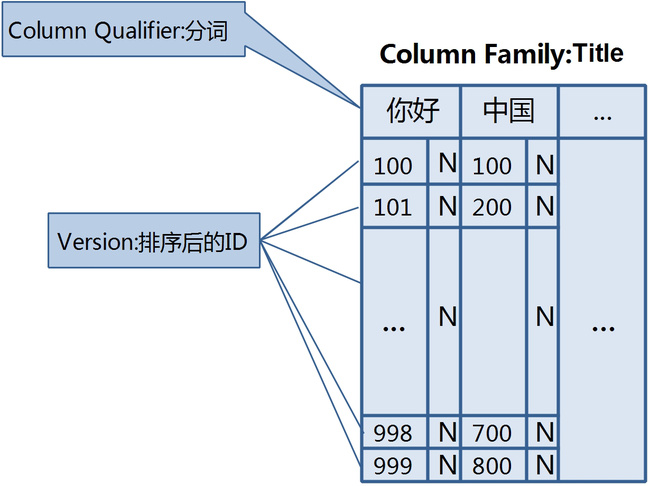
取数据的时候,只需要根据用户id(row key)定位到一个row,然后根据分词定位到qualifier,再通过version的有序list,取top n条记录即可。不过大家可能会发现个问题,version list的总数量是需要scan全version list才能知道的,这里需要业务系统本身做一些改进。
如何join?
实现方式同方案1里的join,多个CF列索引扫描结果后,需要走merge,将多个索引的查询结果conjunction。
两个方案的对比似乎变化就是一个表,一个列,但其实这个方案有个最大的好处,就是解决了事务性的问题,因为所有的索引都是跟单个row key绑定的,我们知道单个row的更新,在hbase中是保证原子更新的,这就是这个方案的天然优势。当你在考虑单索引时,使用基于列的索引会比单表索 引有更好的适用性。
而组合索引在以列为存储粒度的方案里,也同样可以折中实现。理解这种存储模式的同学可能已经猜到了,就是基于qualifier。
下表对比了表索引和列索引的优缺点:
| 列索引 | 表索引 | |
| 检索性能 | 检索数据需要走多次scan,第一次scan row key,第二次scan qualifier,第三次scan version。 | 只需要走一次row key的scan即可。 |
| 存储 | 在没有组合索引时,存储较节省 | 在没有组合索引时,存储较节省 |
| 事务性 | 容易保证 | 保证事务性比较困难 |
| join | 性能较差,只有在建立组合条件Qualifier的时候性能会有所改善 | 性能较差,只有在建立组合表索引的时候性能会有所改善 |
| 额外的问题 | 1,同一个row里每个qualifier的version是有大小限制的,不能超过Int的最大值。(别以为这个值很大,对于海量数据存储,上亿很平常) 2,version的count总数需要额外做处理获取。 3,单个row数据超过split大小时,会导致不能compaction或compaction内存吃紧,增加风险。 |
|
| count,sum,avg,etc | 符合条件的结果集全表扫描 | 符合条件的结果集全表扫描 |
虽然列索引缺点这么多,但是存储节省带来的成本优势有时还是值得我们去这么做的,何况它还解决了事务性问题,需要用户自己去权衡。
值得一提的是,Facebook的消息应用服务器就是基于类似的方案来实现的。
3,ITHBase
方案一中的多表,解决了性能问题,同时带来了存储冗余和数据一致性问题。这两个问题中,只要解决其中一项,其实也就满足了大多数业务场景。
本方案中,着重关注的是数据一致性。ITHbase的全称是 Indexed Transactional HBase,从名字中就能看出,事务性是它的重要特性。
ITHBase的事务原理简介
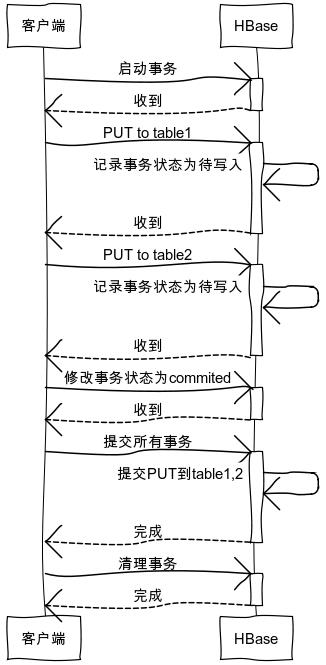
建一张事务表__GLOBAL_TRX_LOG__,每次开启事务时,在表中记录状态。因为是基于Hbase的HTable,事务表同样会写WAL用于恢复,不过这个日志格式被ITHbase改造过,它称之为THLog。
客户端对多张表更新时,先启动事务,然后每次PUT,将事务id传递给HRegionServer。
ITHbase通过继承HRegionServer和HReogin类,重写了大多数操作接口方法,比如put, update, delete, 用于获取transactionalId和状态。
当server收到操作和事务id后,先确认服务端收到,标记当前事务为待写入状态(需要再发起一次PUT)。当所有表的操作完成后,由客户端统一做commit写入,做二阶段提交。
4,Map-reduce
这个方案没什么好说的,存储节省,也不需要建索引表,只需要靠强大的集群计算能力即可导出结果。但一般不适合online业务。
5,Coprocessor协处理器
官方0.92.0新版正在开发中的新功能-Coprocessor,支持region级别索引。详见:
https://issues.apache.org/jira/browse/HBASE-2038
协处理器的机制可以理解为,server端添加了一些回调函数。这些回调函数如下:
The Coprocessor interface defines these hooks:
- preOpen, postOpen: Called before and after the region is reported as online to the master.
- preFlush, postFlush: Called before and after the memstore is flushed into a new store file.
- preCompact, postCompact: Called before and after compaction.
- preSplit, postSplit: Called after the region is split.
- preClose and postClose: Called before and after the region is reported as closed to the master.
The RegionObserver interface is defines these hooks:
- preGet, postGet: Called before and after a client makes a Get request.
- preExists, postExists: Called before and after the client tests for existence using a Get.
- prePut and postPut: Called before and after the client stores a value.
- preDelete and postDelete: Called before and after the client deletes a value.
- preScannerOpen postScannerOpen: Called before and after the client opens a new scanner.
- preScannerNext, postScannerNext: Called before and after the client asks for the next row on a scanner.
- preScannerClose, postScannerClose: Called before and after the client closes a scanner.
- preCheckAndPut, postCheckAndPut: Called before and after the client calls checkAndPut().
- preCheckAndDelete, postCheckAndDelete: Called before and after the client calls checkAndDelete().
利用这些hooks可以实现region级二级索引,实现count, sum, avg, max, min等聚合操作而不需要返回所有的数据,详见 https://issues.apache.org/jira/browse/HBASE-1512。
二级索引的原理猜测
因为coprocessor的最终方案还未公布,就提供的这些hooks来说,二级索引的实现应该是拦截同一个region的put, get, scan, delete等操作。与此同时在同一个reigon里维护一个索引CF,建立对应的索引表。
基于region的索引表其实有很多局限性,比如全局排序就很难做。
不过我觉得Coprocessor最大的好处在于其提供了server端的完全扩展能力,这对于Hbase来说是一个大的跃进。
如何join?
目前还未发布,不过就了解很难从本质上有所突破。解决方案无非就是merge和composite index,同样事务性是需要解决的难题之一。
业界已经公开的二级索引方案罗列:
0.19.3版Secondary Index
一直关注HBase的同学,或许知道,早在HBase 0.19.3版发布时,曾经加入过secondary index的功能,Issue详见这里。
它的使用例子也很简单:http://blog.rajeevsharma.in/2009/06/secondary-indexes-in-hbase.html
0.19.3版Secondary Index通过将列值以row key方法存储,提供索引scan。
但HBase早期的需求主要来自Hadoop。事务的复杂性以及当时发现hadoop-core里有个很难解决的与ITHBase兼容的问题,致使官方在0.20.0版将其核心代码移出了hbase-core,改为contrib第三方扩展,Issue详见这里。
Transactional tableindexed-ITHBase
这个方案就是在0.19.3版被官方剥离出核心的第三方扩展,它的方案上面已经介绍过了。目前支持最新的Hbase 0.90。
是否具备工业强度的稳定性是用户选择它的主要障碍。
https://github.com/hbase-trx/hbase-transactional-tableindexed
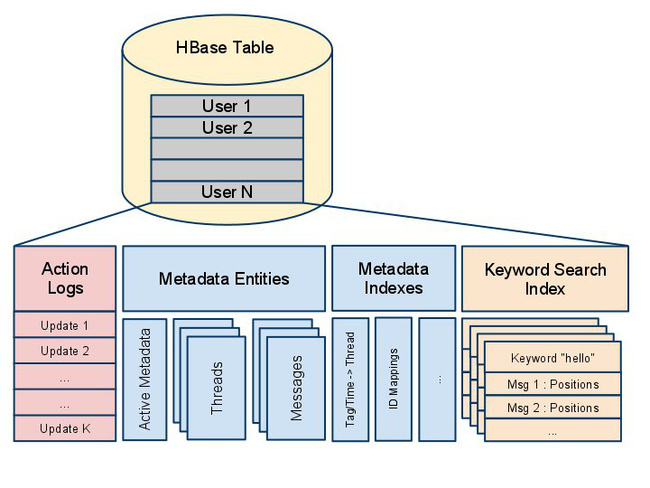
Facebook方案
facebook采用的是单表多列索引的解决方案,上面已经提到过了。很完美地解决了数据一致性问题,这主要跟他们的使用场景有关。
感兴趣的同学可以看下这篇blog,本文不作详述:
HBase官方方案 0.92.0 版开发中 – Coprocessor协处理器
还未发布,不过hbase官方blog有篇介绍:http://hbaseblog.com/2010/11/30/hbase-coprocessors
Lily Hbase indexing Library
这是一个索引构建,查询,管理的框架。结构上,就是通过一张indexmeta表管理多张indexdata索引表。
特点是,有一套非常完善的针对int, string, utf-8, decimal等类型的row key排序机制。这个机制在这篇博文中有详细介绍:
此外,框架针对join场景(原理=merge),提供了封装好的conjunction和disjunction工具类。
针对索引构建场景,Hbase indexing library也提供了很方便的接口。
IHbase
| Feature | ITHBase | IHBase | Comment |
|---|---|---|---|
| global ordering | yes | no | IHBase has an index for each region. The flip side of not having global ordering is compatibility with the good old HRegion: results are coming back in row order (and not value order as in ITHBase) |
| Full table scan? | no | no | THbase does a partial scan on the index table. ITHBase supports specifying start/end rows to limit the number of scanned regions |
| Multiple Index Usage | no | yes | IHBase can take advantage of multiple indexes in the same scan. IHBase IdxScan object accepts an Expression which allows intersection/unison of several indexed column criteria |
| Extra disk storage | yes | no | IHBase indexes are created when the region starts/flushes and do not require any extra storage |
| Extra RAM | yes | yes | IHBase indexes are in memory and hence increase the memory overhead. THBbase indexes increase the number of regions each region server has to support thus costing memory too |
| Parallel scanning support | no | yes | In ITHBase the index table needs to be consulted and then GETs are issued for each matching row. The behavior of IHBase (as perceived by the client) is no different than a regular scan and hence supports parallel scanning seamlessly. parallel GET can be implemented to speedup THbase scans |
scan的时候,IHBase会结合索引列中的标记,来加速scan。
以上是关于HBase二级索引与Join的主要内容,如果未能解决你的问题,请参考以下文章
使用HBase Indexer建立二级索引(整合最新版本的HBase1.2.6及Solr 7.2.1)