CS231n 卷积神经网络与计算机视觉 9 卷积神经网络结构分析
Posted bea_tree
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CS231n 卷积神经网络与计算机视觉 9 卷积神经网络结构分析相关的知识,希望对你有一定的参考价值。
终于进入我们的主题了ConvNets或者CNNs,它的结构和普通神经网络都一样,之前我们学习的各种技巧方法都适用,其主要不同之处在于:
ConvNet假定输入的是图片,我们根据图片的特性对网络进行设定以达到提高效率,减少计算参数量的目的。
1. 结构总览
首先我们分析下传统神经网络对于图片的处理,如果还是用CIFAR-10上的图片,共3072个特征,如果普通网络结构输入那么第一层的每一个神经单元都会有3072个权重,如果更大的像素的图片进入后参数更多,而且用于图片处理的网络一般深度达10层之上,加在一起参数的量实在太大,参数过多也会造成过拟合,而且图片也有自身的特点,我们需要利用这些特点,将传统网络改革,加快处理速度和精确度。
我们注意到图片的像素是由3个通道构成的,我们就利用了这个特点将其神经元安置到了三维空间(width, height, depth),分别对应着图片的32x32x3(以CIFAR为例)如下图:
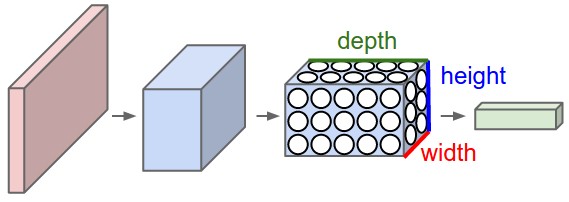
红色是输入层这里的深度是3,输出层是1x1x10的结构。其他几层的含义后面会介绍,现在先知道每层都是height × width × depth结构。
2. 卷积神经网络的层
卷积神经网络有三种层:卷积层、池化层和全连接层(Convolutional Layer, Pooling Layer, 及 Fully-Connected Layer)。
以处理CIFAR-10的卷积神经网络为例,简单的网络应包含这几层:
[INPUT - CONV - RELU - POOL - FC]也就是[输入-卷积-激活-池化-分类得分],各层分述如下:
- INPUT [32x32x3] 输入长32宽32带有三个通道的图片
- CONV :计算图片的局部区域,如果我们想要使用12个过滤器fliters,他的体积将是 [32x32x12].
- RELU :还是一个激励层max(0,x) ,尺寸还是 ([32x32x12]).
- POOL: 沿着图片的(width, height)采样, 减小长宽的维度,例如得到的结果是 [16x16x12].
- FC (i.e. fully-connected) 计算分类得分最终尺寸是 [1x1x10], 这层是全连接的,每一个单元都与前一层的各个单元连接。
注意:
1. 卷及神经网络包含不同的层 (e.g. CONV/FC/RELU/POOL 也是最受欢迎的)
2. 每一层都输入输出3d结构的数据,除了最后一层
3. 有些层可能没有参数,有些层可能有参数 (e.g. CONV/FC do, RELU/POOL don’t)
4. 有些层可能有超参数有些层也可能没有超参数(e.g. CONV/FC/POOL do, RELU doesn’t)
下图是一个例子,没法用三维表示只能展成一列的形式了。
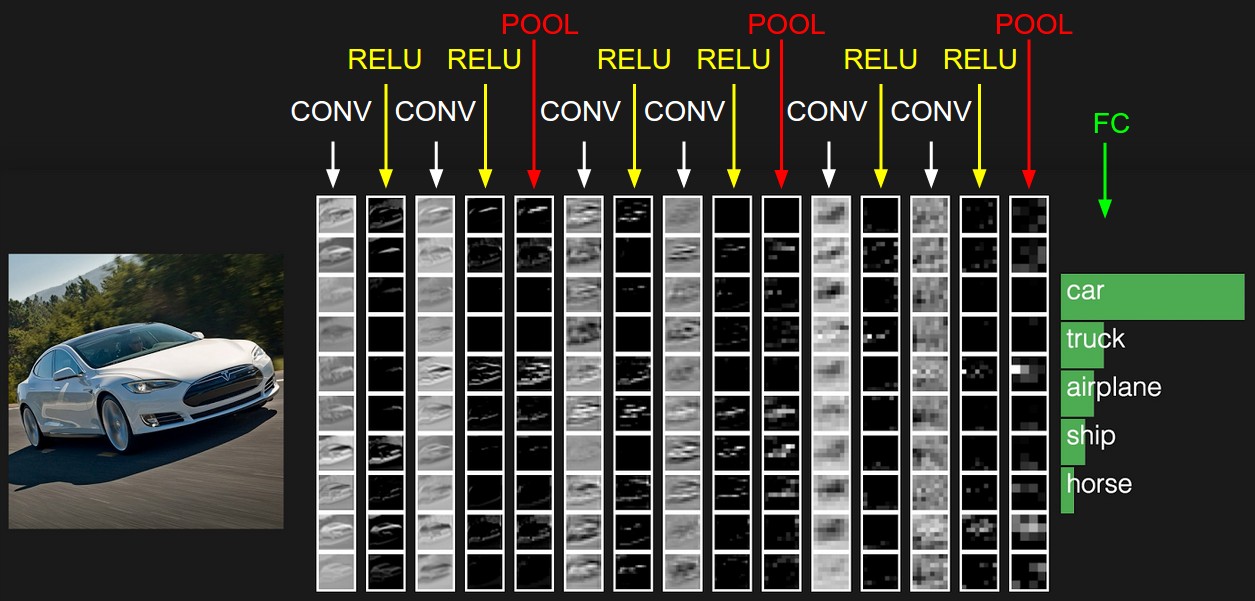
下面展开讨论各层具体细节:
2.1 卷积层
卷积层是卷积神经网络的核心层,大大提高了计算效率。
卷积层由很多过滤器组成,每个过滤器都只有一小部分,每次只与原图像上的一小部分连接,UFLDL上的图:
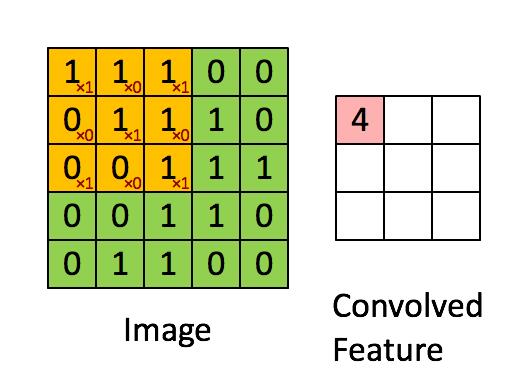
这是一个过滤器不停滑动的结果,
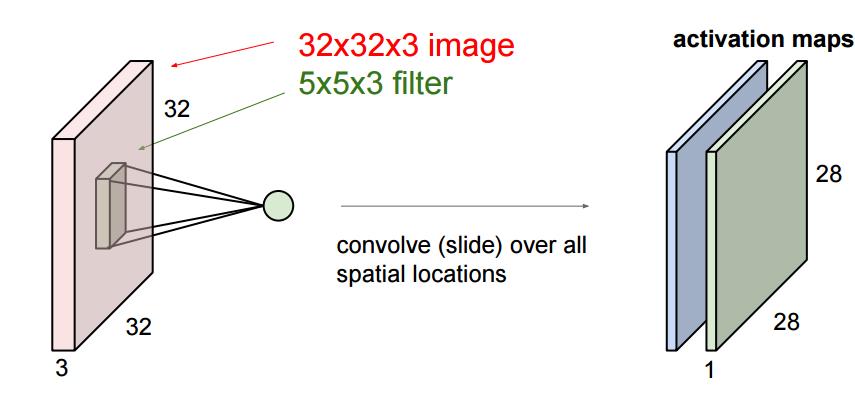
我们这里要更深入些,我们输入的图像是一个三维的,那么每个过滤器也是有三个维度,假设我们的过滤器是5x5x3的那么我们也会得到一个类似于上图的激活值的映射也就是convolved feature 下图中叫作 activion map,其计算方法是
wT×x+b
其中w是5x5x3=75个数据,也就是权重,他是可以调节的。
我们可以有多个过滤器:
更深入一些,当我们滑动的时候有三个超参数:
1. 深度,depth,这是过滤器的数量决定的。
2. 步长,stride,每次滑动的间隔,上面的动画每次只滑动1个数,也就是步长为1.
3. 补零数, zero-padding,有时候根据需要,会用零来拓展图像的面积,如果补零数为1,变长就+2,如下图中灰色的部分就是补的0
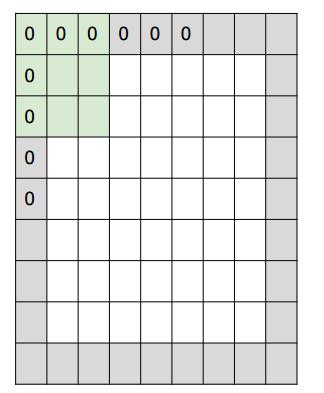
下面是一个一维的例子:

其输出的空间维度计算公式是
以上是关于CS231n 卷积神经网络与计算机视觉 9 卷积神经网络结构分析的主要内容,如果未能解决你的问题,请参考以下文章