散列表简介
Posted 谭兄
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了散列表简介相关的知识,希望对你有一定的参考价值。
散列表也叫哈希表,是一种根据关键字直接访问内存存储位置的数据结构,它是用一个数组实现的无序符号表.将键作为数组的索引而数组中键i处存储的就是它对应的值,这样就可以实现快速访问任意键的值.散列表是算法在时间和空间上做出权衡的经典例子.
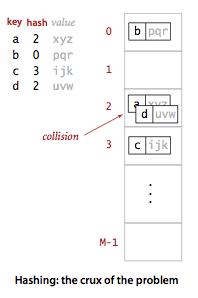
散列表的查找算法分为两步:
1.用散列函数将键转化为数组索引,可能会出现多个键散列到相同的索引值上面,这是就要进行第二步了.
2.处理碰撞冲突(拉链法和线性探测法).
散列函数的概念
散列函数应该易于计算并且能够均匀分布所有的键, 即对于任意键, 0到M-1之间每个整数都有相同的可能性与之对应(与键无关), 严格地说每种类型的键都应该有对应的散列函数.
正整数: 一般用除留余数法,选择素数为M的数组,对于任意正整数k,计算k除以M的余数.可以有效的散布在0-M-1之间.如果M不是素数,可能不会均匀散布.
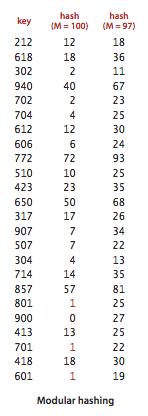
浮点数:java中将键表示为二进制然后使用除留取余法
.
字符串:java中charAt()返回一个非负16位整数,只要R足够小,不造成溢出,那么结果就会落在0至M-1之间
int hash = 0; for (int i = 0; i < s.length(); i++) hash = (R * hash + s.charAt(i)) % M;
组合键:如果键中含有多个整型变量, 我们可以和String类型一样将它们混合起来,例如Date类型, 含有几个整型的域: day, month和year, 我们可以这样计算散列值:
int hash = (((day * R + montn) % M) * R + year) % M;
只要R足够小不造成溢出,也可以得到一个0至M-1之间的散列值.
软缓存
如果散列值的计算很耗时,我们可以将每个键的散列值缓存起来,即每个键中使用一个hash变量保存它的hasCode()的返回值。
基于拉链法的散列表
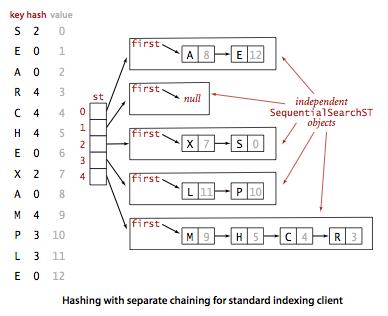


public class SeparateChainingHashST<Key, Value> { private int N; //键值对总数 private int M; //散列表大小 private SequentialSearchST<Key,Value>[] st; //存放链表对象的数组 public SeparateChainingHashST(){ this(100); } public SeparateChainingHashST(int M){ //创建M条链表 this.M = M; st = (SequentialSearchST<Key,Value>[]) new SequentialSearchST[M]; for(int i=0; i<M; i++){ st[i] = new SequentialSearchST(); } } private int hash(Key key){ return (key.hashCode() & 0x7fffffff) % M; } private Value get(Key key){ return (Value)st[hash(key)].get(key); } private void put(Key key,Value val){ st[hash(key)].put(key, val); } }
这里实现了一个链表数组, 用散列函数来为每个键选择一条链表, 在创建st[]时需要进行类型转换, 因为java不允许泛型的数组.
其中用到的 SequentialSearchST实际上就是一个基于链表的符号表实现.
public class SequentialSearchST<Key, Value> { private Node first; private class Node{ //定义链表节点 Key key; Value val; Node next; public Node(Key key,Value val,Node next){ this.key = key; this.val = val; this.next = next; } } public Value get(Key key){ for(Node x = first; x != null; x = x.next){ if(key.equals(x.key)){ return (Value)x.val; //命中 } } return null; //未命中 } public void put(Key key, Value val){ //命中更新值,未命中则新建节点插入头部 for(Node x= first; x != null; x = x.next){ if(key.equals(x.key)){ x.val = val; return; } } //未命中 Node first = new Node(key,val,first); } }
基于线性探测法的散列表
当碰撞发生时,我们直接检查散列表的下一个位置(将索引值加1),可能有三种结果:
1.命中, 该位置的键和被查找的键相同;
2.未命中, 键为空(该位置没有键);
3.继续查找,该位置和被查找的键不同;
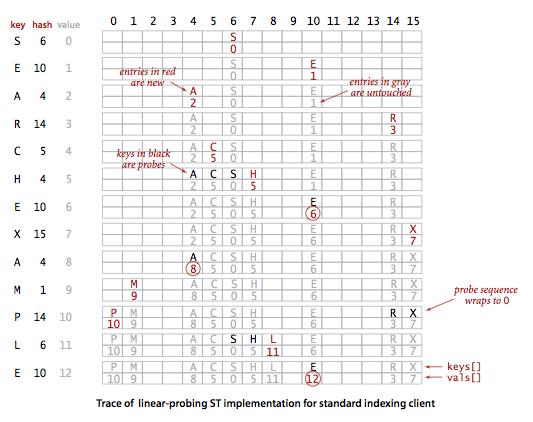
我们在实现中使用并行数组, 一条保存键, 一条保存值. 并且使用散列函数产生访问数据所需的数组索引.
使用null表示一簇键的结束,如果一个新建的散列值是一个空元素,就把它保存在那里;如果不为空,就顺序查找一个空元素来保存它.
要查找一个键, 我们从它的散列值开始顺序查找
public class LinearProbingHashST<Key, Value> { private int N; //键值对总数 private int M; //线性探测表大小 private Key[] keys; //键 private Value[] vals; //值 /*构造函数,设置初始值*/ public LinearProbingHashST(int cap){ M =cap; keys = (Key[]) new Object[M]; vals = (Value[]) new Object[M]; } private int hash(Key key){ return (key.hashCode() & 0x7fffffff) % M; } /*调整数组大小*/ private void resize(int cap){ LinearProbingHashST<Key,Value> t; t = new LinearProbingHashST<Key,Value>(cap); for(int i = 0; i < M; i++){ if(keys[i] != null){ t.put(keys[i], vals[i]); } } keys = t.keys; vals = t.vals; M = t.M; } private void put(Key key,Value val){ //调整数组大小 if(N >= M/2) resize(2*M); int i; for(i =hash(key); keys[i] != null; i=(i+1) % M){ if(keys[i].equals(key)){ vals[i] = val; return ; } } keys[i] = key; vals[i] = val; N++; } public Value get(Key key){ for(int i=hash(key); keys[i] != null; i = (i+1)%M){ if(keys[i].equals(key)){ return vals[i]; } } return null; } }
resize()方法用来调整数组大小, 保证了散列表的使用率永远不会超过1/2;
它重新创建了一个给定大小的符号表, 保存原表中的keys和values变量, 然后把原表中的所有键重新散列并插入到新表中, 这使得数组长度可以加倍.
删除操作
/*删除操作*/ public void delete(Key key){ int i = hash(key); while(!key.equals(keys[i])){ i = (i+1) % M; } keys[i] = null; vals[i] = null; i = (i+1) % M; while(keys[i] != null){ Key k = keys[i]; Value v = vals[i]; keys[i] = null; vals[i] = null; N--; /*这里减1是因为在put()方法中会自动加1*/ put(k,v); i = (i+1) % M; } N--; //调整大小 if(N>0 && N == M/8) resize(M/2); }
删除操作比较复杂, 直接把要删除的元素设置为null是不行的, 这会使得在此之后的元素不会被找到.
所以需要把这一簇中被删除键右侧的元素全部重新插入散列表中.为保证性能, 一般是散列表的使用率控制在1/8到1/2之间.
键簇:元素在插入数组后聚集形成的一组连续条目.
以上是关于散列表简介的主要内容,如果未能解决你的问题,请参考以下文章