kafka理论
Posted 呢喃的歌声
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka理论相关的知识,希望对你有一定的参考价值。
一、消息队列,简称MQ,message queue
生产者:生存数据写到kafka,持久化到硬盘。对同一个Topic来讲,生产者通常只有‘一个’(可以多并发)数据保存时常可以配置,默认保存七天。
消费者:从kafka里消费数据。对同一个Topic来讲,消费者会很多,根据业务需要。
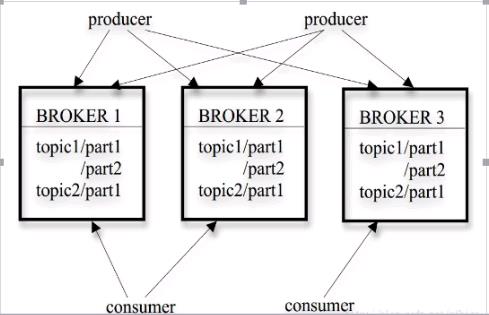
kafka的消息分几个层次:
1)Topic:一类消息,例如page view 日志,click日志等都以topic的形式存在,kafka集群能够负责多个topic分发
2)partition:topic物理上的分组,一个topic可以分为多个partition(默认为2个),每个partition是一个有序的队列。partition中的每个消息都会被分配到一个有序的id(offset,消费位置)。(位置记录在zookeeper中 可以宕机继续消费)
3)Message:消息,最小订阅单元
数据流程:
1、producer根据指定的partition方法(round-robin、hash等【不指定的话内部会自己指定】),将消息发布到指定的topic的partition里面
2、kafka集群接收到producer发过来的消息后,将其持久化到硬盘,并保留消息指定时常(可配置,默认7天),而不关注消息是否是否被消费。
3、Consumer从kafka集群消费(pull)数据,并控制获取消息的offset偏移量。
(kafka消费都采用pull方式,即客户端customer主动拉取数据,客户端控制offset,客户端可以根据需要随时随地进行消费,更加灵活,而且对服务端来讲更加省事)
(push方式为服务端推送数据到客户端,kafka不支持,服务端控制offset)
比如消费同一个topic的作业有100个,如果服务端维护offset很麻烦,增加服务端的工作量。
kafka为何能支持高吞吐量?
1)数据磁盘持久化:消息不存在内存中cache,直接写入磁盘,充分利用磁盘的顺序读写性能,所以borker没内存压力
2)zero-copy:减少IO操作步骤
3)数据批量发送
4)数据压缩
5)Topic划分为多个partition,提高parallelism(并行度)
(如果内存加硬盘不是更快,但是kafka是先进先出,消费旧数据,内存是缓存最新的不适合kafka特性,所以不缓存到内存中)
kafka如何做到负载均衡?
1)producer根据用户指定的算法,讲消息发送到指定的partition
2)存在多个partition,每个partition有自己的replica(副本),每个replica分布在不同的broker节点上
3)多个partition时候需要选取leader partition(通过zk的选举机制),leader partition 负责读写,并由zookeeper 负责fail over(快速失败)
4)通过zookeeper管理broker与consumer的动态加入与离开
以上是关于kafka理论的主要内容,如果未能解决你的问题,请参考以下文章