第一个spark程序
Posted 南边雪
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第一个spark程序相关的知识,希望对你有一定的参考价值。
Scala开发,sbt打包,spark运行
1、创建文件目录结构:

2、创建Scala程序 SimpleAPP.Scala:

import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object SimpleApp {
def main(args: Array[String]) {
val logFile = "file:///mnt/hgfs/share/resource/jitanjiali.docx"
//Should be some file on your system
val conf = new SparkConf().setAppName("Simple Application")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2).cache()
val numAs = logData.filter(line => line.contains(\'a\')).count()
val numBs = logData.filter(line => line.contains(\'b\')).count()
println("Lines with a : %s, Lines with b: %s".format(numAs, numBs))
}
}
3、使用sbt打包Scala程序
该程序依赖 Spark API,因此需要通过 sbt 进行编译打包。 在./sparkapp 中新建文件 simple.sbt,添加如下内容,声明该独立应用程序的信息以及与 Spark 的依赖关系:


文件 simple.sbt 指明 Spark 和 Scala 的版本。在上面的配置信息中,scalaVersion用来指定scala的版本,sparkcore用来指定spark的版本。
为保证 sbt 能正常运行,先执行如下命令检查整个应用程序的文件结构:
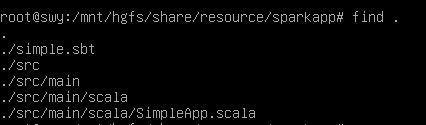
将整个应用程序打包成 JAR(首次运行需要下载依赖包 ):

打包成功:

4、运行
将生成的 jar 包通过 spark-submit 提交到 Spark 中运行

自此完成第一个spark程序
以上是关于第一个spark程序的主要内容,如果未能解决你的问题,请参考以下文章
spark关于join后有重复列的问题(org.apache.spark.sql.AnalysisException: Reference '*' is ambiguous)(代码片段