Kafka核心技术与实战——18 | Kafka中位移提交那些事儿
Posted minimalist
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka核心技术与实战——18 | Kafka中位移提交那些事儿相关的知识,希望对你有一定的参考价值。
- Consumer 端有个位移的概念
- 它和消息在分区中的位移不是一回事儿
- Consumer 的消费位移,它记录了 Consumer 要消费的下一条消息的位移。这可能和你以前了解的有些出入,不过切记是下一条消息的位移,而不是目前最新消费消息的位移
- Consumer 需要向 Kafka 汇报自己的位移数据,这个汇报过程被称为提交位移(Committing Offsets)
- 因为 Consumer 能够同时消费多个分区的数据,所以位移的提交实际上是在分区粒度上进行的
- 即Consumer 需要为分配给它的每个分区提交各自的位移数据
- 位移提交的语义保障是由你来负责的,Kafka 只会“无脑”地接受你提交的位移
- 特别是 KafkaConsumer API,提供了多种提交位移的方法
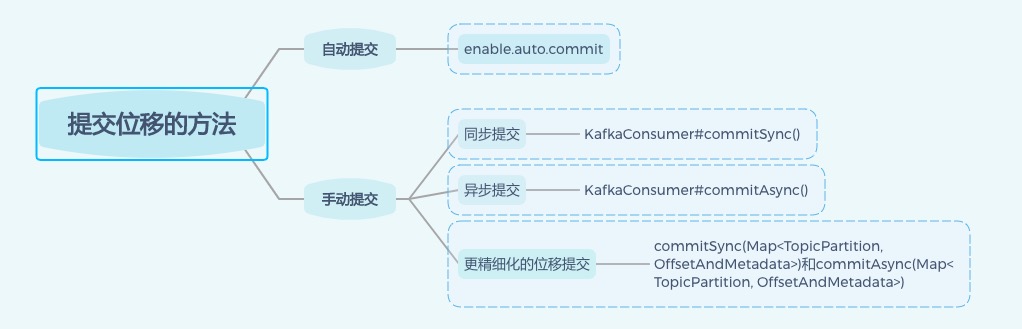
- 从用户的角度来说,位移提交分为自动提交和手动提交;
- 从 Consumer 端的角度来说,位移提交分为同步提交和异步提交
- 开启自动提交位移的方法很简单
- Consumer 端有个参数 enable.auto.commit,把它设置为 true 或者压根不设置它就可以了
- 如果启用了自动提交,Consumer 端还有个参数就派上用场了:auto.commit.interval.ms。它的默认值是 5 秒,表明 Kafka 每 5 秒会为你自动提交一次位移
- 手动提交
- 开启手动提交位移的方法就是设置 enable.auto.commit 为 false
- 仅仅设置它为 false 还不够,因为你只是告诉 Kafka Consumer 不要自动提交位移而已,你还需要调用相应的 API 手动提交位移
- 同步操作
- 最简单的 API 就是KafkaConsumer#commitSync()。该方法会提交 KafkaConsumer#poll() 返回的最新位移
- 自动提交位移的一个问题在于,它可能会出现重复消费
- 反观手动提交位移,它的好处就在于更加灵活,你完全能够把控位移提交的时机和频率。但是,它也有一个缺陷,就是在调用 commitSync() 时,Consumer 程序会处于阻塞状态,直到远端的 Broker 返回提交结果,这个状态才会结束
- 异步操作
- KafkaConsumer#commitAsync()
- 调用 commitAsync() 之后,它会立即返回,不会阻塞,因此不会影响 Consumer 应用的 TPS。由于它是异步的,Kafka 提供了回调函数(callback),供你实现提交之后的逻辑,比如记录日志或处理异常等
- 显然,如果是手动提交,我们需要将 commitSync 和 commitAsync 组合使用才能到达最理想的效果,原因有两个:
- 1、我们可以利用 commitSync 的自动重试来规避那些瞬时错误,比如网络的瞬时抖动,Broker 端 GC 等。因为这些问题都是短暂的,自动重试通常都会成功,因此,我们不想自己重试,而是希望 Kafka Consumer 帮我们做这件事。
- 2、我们不希望程序总处于阻塞状态,影响 TPS。
- 它展示的是如何将两个 API 方法结合使用进行手动提交
try { while (true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1)); process(records); // 处理消息 commitAysnc(); // 使用异步提交规避阻塞 }} catch (Exception e) { handle(e); // 处理异常} finally { try { consumer.commitSync(); // 最后一次提交使用同步阻塞式提交 } finally { consumer.close();}}- 对于常规性、阶段性的手动提交,我们调用 commitAsync() 避免程序阻塞,而在 Consumer 要关闭前,我们调用 commitSync() 方法执行同步阻塞式的位移提交,以确保 Consumer 关闭前能够保存正确的位移数据
- 对于一次要处理很多消息的 Consumer 而言,它会关心社区有没有方法允许它在消费的中间进行位移提交
- 比如前面这个 5000 条消息的例子,你可能希望每处理完 100 条消息就提交一次位移,这样能够避免大批量的消息重新消费
private Map<TopicPartition, OffsetAndMetadata> offsets = new HashMap<>();int count = 0;……while (true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1)); for (ConsumerRecord<String, String> record: records) { process(record); // 处理消息 offsets.put(new TopicPartition(record.topic(), record.partition()), new OffsetAndMetadata(record.offset() + 1); if(count % 100 == 0) consumer.commitAsync(offsets, null); // 回调处理逻辑是 null count++; }}
- 小结
- Kafka Consumer 的位移提交,是实现 Consumer 端语义保障的重要手段
- 位移提交分为自动提交和手动提交,而手动提交又分为同步提交和异步提交
- 在实际使用过程中,推荐你使用手动提交机制,因为它更加可控,也更加灵活
- 另外,建议你同时采用同步提交和异步提交两种方式,这样既不影响 TPS,又支持自动重试,改善 Consumer 应用的高可用性
- 总之,Kafka Consumer API 提供了多种灵活的提交方法,方便你根据自己的业务场景定制你的提交策略
-
以上是关于Kafka核心技术与实战——18 | Kafka中位移提交那些事儿的主要内容,如果未能解决你的问题,请参考以下文章
Kafka核心技术与实战——16 | 揭开神秘的“位移主题”面纱
Kafka核心技术与实战——03 | Kafka只是消息引擎系统吗?
Kafka核心技术与实战——02 | 一篇文章带你快速搞定Kafka术语
Kafka核心技术与实战——23 | Kafka副本机制详解