Ceph分布式存储双活服务配置
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Ceph分布式存储双活服务配置相关的知识,希望对你有一定的参考价值。
Ceph天生带两地三中心概念,所谓的双活就是两个数据中心(multi-site)。Ceph两数据中心可以在一个集群也可以在不同的集群中。架构图(它山之石)如下所示: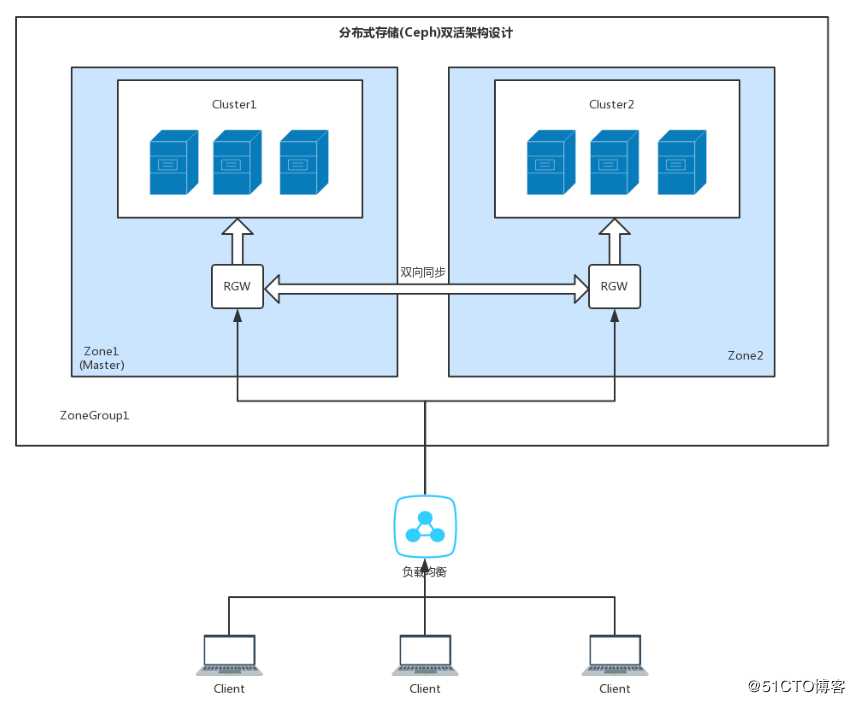
1、环境信息
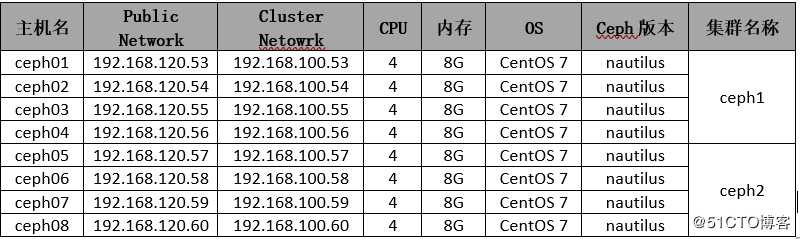
2、创建Master zone
在一个multi-site配置当中的所有rgw都会接收来自master zone group中的mater zone对应的ceph-radosgw的相关配置。因此必须先配置一个master zone group和一个master zone。
2.1 创建realm
一个realm包含multi-site配置中的zone groups以及zones,并且在该realm中作为全局唯一的名称空间。在主集群任意一个节点上执行下面的命令创建:
[root@ceph01 ~]# radosgw-admin -c ceph1 realm create --rgw-realm=xzxj --default
{
"id": "0f13bb55-68f6-4489-99fb-d79ba8ca959a",
"name": "xzxj",
"current_period": "02a14536-a455-4063-a990-24acaf504099",
"epoch": 1
}realm只用于本集群的话,则添加--default选项,radosgw-admin就默认会使用该realm。
2.2 创建master zonegroup
一个realm必须至少有一个master zone group。
[root@ceph01 ~]# radosgw-admin --cluster ceph1 zonegroup create --rgw-zonegroup=all --endpoints=http://192.168.120.53:8080,http://192.168.120.54:8080,http://192.168.120.55:8080,http://192.168.120.56:8080 --rgw-realm=xzxj --master --default当realm只有一个zone group的话,则指定--default选项,在添加新的zones时就会默认添加到该zone group中。
2.3 创建master zone
为一个multi-site配置添加新的master zone:z1,如下:
[root@ceph01 ~]# radosgw-admin --cluster ceph1 zone create --rgw-zonegroup=all --rgw-zone=z1 --endpoints=http://192.168.120.53:8080,http://192.168.120.54:8080,http://192.168.120.55:8080,http://192.168.120.56:8080 --default这里并未指定--access-key与--secret。在下面的步骤中,创建用户的时候会自动的把这些设置添加到zone中。
2.4 创建系统账户
ceph-radosgw守护进程来拉取realm以及period信息之前必须进行认证。在master zone中,创建一个系统用户来在不同daemon之间完成认证:
[root@ceph01 ~]# radosgw-admin --cluster ceph1 user create --uid="sync-user" --display-name="sync user" --system
{
"user_id": "sync-user",
"display_name": "sync user",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"subusers": [],
"keys": [
{
"user": "sync-user",
"access_key": "ZA4TXA65C5TGCPX4B8V6",
"secret_key": "BEYnz6QdAvTbt36L7FhwGF2F5rHWeH66cb0eSO24"
}
],
"swift_keys": [],
"caps": [],
"op_mask": "read, write, delete",
"system": "true",
"default_placement": "",
"default_storage_class": "",
"placement_tags": [],
"bucket_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"temp_url_keys": [],
"type": "rgw",
"mfa_ids": []
}当secondary zones需要和master zone完成认证时,需要系统账户的access_key与secret_key。最后,将系统用户添加到master zone中并更新period:
[root@ceph01 ~]# radosgw-admin --cluster ceph1 zone modify --rgw-zone=z1 --access-key=ZA4TXA65C5TGCPX4B8V6 --secret=BEYnz6QdAvTbt36L7FhwGF2F5rHWeH66cb0eSO24
[root@ceph01 ~]# radosgw-admin --cluster ceph1 period update --commit2.5 更新ceph配置文件
编辑配置文件ceph.conf,添加rgw_zone选项,该选项的值为master zone的名称。这里rgw_zone=z1,有多少个rgw节点,就加多少个,如下:
[root@ceph01 ~]# vi /etc/ceph/ceph1.conf
[client.rgw.ceph01.rgw0]
host = ceph01
keyring = /var/lib/ceph/radosgw/ceph1-rgw.ceph01.rgw0/keyring
log file = /var/log/ceph/ceph1-rgw-ceph01.rgw0.log
rgw frontends = beast endpoint=192.168.120.53:8080
rgw thread pool size = 512
rgw_zone=z1
[client.rgw.ceph02.rgw0]
host = ceph02
keyring = /var/lib/ceph/radosgw/ceph1-rgw.ceph02.rgw0/keyring
log file = /var/log/ceph/ceph1-rgw-ceph02.rgw0.log
rgw frontends = beast endpoint=192.168.120.54:8080
rgw thread pool size = 512
rgw_zone=z1
[client.rgw.ceph03.rgw0]
host = ceph03
keyring = /var/lib/ceph/radosgw/ceph1-rgw.ceph03.rgw0/keyring
log file = /var/log/ceph/ceph1-rgw-ceph03.rgw0.log
rgw frontends = beast endpoint=192.168.120.55:8080
rgw thread pool size = 512
rgw_zone=z1
[client.rgw.ceph04.rgw0]
host = ceph04
keyring = /var/lib/ceph/radosgw/ceph1-rgw.ceph04.rgw0/keyring
log file = /var/log/ceph/ceph1-rgw-ceph04.rgw0.log
rgw frontends = beast endpoint=192.168.120.56:8080
rgw thread pool size = 512
rgw_zone=z1编辑完成后,同步ceph配置文件至其他集群节点,然后在所有rgw节点重启rgw服务:
[root@ceph01 ~]# systemctl restart ceph-radosgw@rgw.`hostname -s`.rgw03、创建slave zone
3.1 从master zone拉取realm
使用master zone group中master zone的URL路径、access key以及secret key来拉取realm到secondary zone对应的宿主机上。如果要拉取一个非默认的realm,请使用--rgw-realm或--realm-id选项:
[root@ceph05 ~]# radosgw-admin --cluster ceph2 realm pull --url=http://192.168.120.53:8080 --access-key=ZA4TXA65C5TGCPX4B8V6 --secret=BEYnz6QdAvTbt36L7FhwGF2F5rHWeH66cb0eSO24
{
"id": "0f13bb55-68f6-4489-99fb-d79ba8ca959a",
"name": "xzxj",
"current_period": "913e666c-57fb-4992-8839-53fe447d8427",
"epoch": 2
}注:这里的access key 和secret是master zone上system 账户的access key和secret。
3.2 从master zone拉取period
使用master zone group中master zone的URL路径、access key以及secret key来拉取period到secondary zone对应的宿主机上。如果是从一个非默认的realm中拉取period,请使用--rgw-realm或--realm-id选项:
[root@ceph05 ~]# radosgw-admin --cluster ceph2 period pull --url=http://192.168.120.53:8080 --access-key=ZA4TXA65C5TGCPX4B8V6 --secret=BEYnz6QdAvTbt36L7FhwGF2F5rHWeH66cb0eSO243.3 创建slave zone
使用master zone group中master zone的URL路径、access key以及secret key来拉取period到secondary zone对应的宿主机上。如果是从一个非默认的realm中拉取period,请使用--rgw-realm或--realm-id选项。默认情况下所有的zone都是以active-active配置方式运行,即一个RGW客户端可以向任何一个zone写数据,这个zone会向处于同一个group中的其他zone复制数据。假如secondary zone并不能接受写操作的话,请指定--read-only选项来创建一个active-passive配置的zone。另外,需要提供master zone中的access key以及secret key。
[root@ceph05 ~]# radosgw-admin --cluster ceph2 zone create --rgw-zonegroup=all --rgw-zone=z2 --endpoints=http://192.168.120.57:8080,http://192.168.120.58:8080,http://192.168.120.59:8080,http://192.168.120.60:8080 --access-key=ZA4TXA65C5TGCPX4B8V6 --secret=BEYnz6QdAvTbt36L7FhwGF2F5rHWeH66cb0eSO243.4 更新period
[root@ceph05 ~]# radosgw-admin --cluster ceph2 period update --commit
{
"id": "913e666c-57fb-4992-8839-53fe447d8427",
"epoch": 4,
"predecessor_uuid": "02a14536-a455-4063-a990-24acaf504099",
"sync_status": [],
"period_map": {
"id": "913e666c-57fb-4992-8839-53fe447d8427",
"zonegroups": [
{
"id": "8259119d-4ed7-4cfc-af28-9a8e6678c5f7",
"name": "all",
"api_name": "all",
"is_master": "true",
"endpoints": [
"http://192.168.120.53:8080",
"http://192.168.120.54:8080",
"http://192.168.120.55:8080",
"http://192.168.120.56:8080"
],
"hostnames": [],
"hostnames_s3website": [],
"master_zone": "91d15c30-f785-4bd1-8e80-d63ab939b259",
"zones": [
{
"id": "04231ccf-bb2b-4eff-aba7-a7cb9a3505cf",
"name": "z2",
"endpoints": [
"http://192.168.120.57:8080",
"http://192.168.120.58:8080",
"http://192.168.120.59:8080",
"http://192.168.120.60:8080"
],
"log_meta": "false",
"log_data": "true",
"bucket_index_max_shards": 0,
"read_only": "false",
"tier_type": "",
"sync_from_all": "true",
"sync_from": [],
"redirect_zone": ""
},
{
"id": "91d15c30-f785-4bd1-8e80-d63ab939b259",
"name": "z1",
"endpoints": [
"http://192.168.120.53:8080",
"http://192.168.120.54:8080",
"http://192.168.120.55:8080",
"http://192.168.120.56:8080"
],
"log_meta": "false",
"log_data": "true",
"bucket_index_max_shards": 0,
"read_only": "false",
"tier_type": "",
"sync_from_all": "true",
"sync_from": [],
"redirect_zone": ""
}
],
"placement_targets": [
{
"name": "default-placement",
"tags": [],
"storage_classes": [
"STANDARD"
]
}
],
"default_placement": "default-placement",
"realm_id": "0f13bb55-68f6-4489-99fb-d79ba8ca959a"
}
],
"short_zone_ids": [
{
"key": "04231ccf-bb2b-4eff-aba7-a7cb9a3505cf",
"val": 1058646688
},
{
"key": "91d15c30-f785-4bd1-8e80-d63ab939b259",
"val": 895340584
}
]
},
"master_zonegroup": "8259119d-4ed7-4cfc-af28-9a8e6678c5f7",
"master_zone": "91d15c30-f785-4bd1-8e80-d63ab939b259",
"period_config": {
"bucket_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
}
},
"realm_id": "0f13bb55-68f6-4489-99fb-d79ba8ca959a",
"realm_name": "xzxj",
"realm_epoch": 2
}3.5 更改ceph配置文件并重启RGW服务
编辑配置ceph.conf,加入rgw_zone=z2:
[root@ceph05 ~]# vi /etc/ceph/ceph2.conf
[client.rgw.ceph05.rgw0]
host = ceph05
keyring = /var/lib/ceph/radosgw/ceph2-rgw.ceph05.rgw0/keyring
log file = /var/log/ceph/ceph2-rgw-ceph05.rgw0.log
rgw frontends = beast endpoint=192.168.120.57:8080
rgw thread pool size = 512
rgw_zone= z2
[client.rgw.ceph06.rgw0]
host = ceph06
keyring = /var/lib/ceph/radosgw/ceph2-rgw.ceph06.rgw0/keyring
log file = /var/log/ceph/ceph2-rgw-ceph06.rgw0.log
rgw frontends = beast endpoint=192.168.120.58:8080
rgw thread pool size = 512
rgw_zone= z2
[client.rgw.ceph07.rgw0]
host = ceph07
keyring = /var/lib/ceph/radosgw/ceph2-rgw.ceph07.rgw0/keyring
log file = /var/log/ceph/ceph2-rgw-ceph07.rgw0.log
rgw frontends = beast endpoint=192.168.120.59:8080
rgw thread pool size = 512
rgw_zone= z2
[client.rgw.ceph08.rgw0]
host = ceph08
keyring = /var/lib/ceph/radosgw/ceph2-rgw.ceph08.rgw0/keyring
log file = /var/log/ceph/ceph2-rgw-ceph08.rgw0.log
rgw frontends = beast endpoint=192.168.120.60:8080
rgw thread pool size = 512
rgw_zone= z2编辑完成后,同步ceph配置文件至其他集群节点,然后在所有rgw节点重启rgw服务:
[root@ceph05 ~]# systemctl restart ceph-radosgw@rgw.`hostname -s`.rgw04、同步状态检查
当secondary zone建立起来并成功运行之后,可以检查相应的同步状态。同步操作会拷贝在master zone中创建的users及buckets到secondary zone中。在master上创建一个candon用户,然后再slave上查看:
[root@ceph01 ~]# radosgw-admin --cluster ceph1 user create --uid="candon" --display-name="First User"
{
"user_id": "candon",
"display_name": "First User",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"subusers": [],
"keys": [
{
"user": "candon",
"access_key": "Y9WJW2H2N4CLDOOE8FN7",
"secret_key": "CsWtWc40R2kJSi0BEesIjcJ2BroY8sVv821c95ZD"
}
],
"swift_keys": [],
"caps": [],
"op_mask": "read, write, delete",
"default_placement": "",
"default_storage_class": "",
"placement_tags": [],
"bucket_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"temp_url_keys": [],
"type": "rgw",
"mfa_ids": []
}
[root@ceph01 ~]# radosgw-admin --cluster ceph1 user list
[
"sync-user",
"candon"
]
[root@ceph05 ~]# radosgw-admin --cluster ceph2 user list
[
"sync-user",
"candon"
]同步状态查看:
[root@ceph01 ~]# radosgw-admin --cluster ceph1 sync status
realm 0f13bb55-68f6-4489-99fb-d79ba8ca959a (xzxj)
zonegroup 8259119d-4ed7-4cfc-af28-9a8e6678c5f7 (all)
zone 91d15c30-f785-4bd1-8e80-d63ab939b259 (z1)
metadata sync no sync (zone is master)
data sync source: 04231ccf-bb2b-4eff-aba7-a7cb9a3505cf (z2)
syncing
full sync: 0/128 shards
incremental sync: 128/128 shards
data is caught up with source
[root@ceph05 ~]# radosgw-admin --cluster ceph2 sync status
realm 0f13bb55-68f6-4489-99fb-d79ba8ca959a (xzxj)
zonegroup 8259119d-4ed7-4cfc-af28-9a8e6678c5f7 (all)
zone 04231ccf-bb2b-4eff-aba7-a7cb9a3505cf (z2)
metadata sync syncing
full sync: 0/64 shards
incremental sync: 64/64 shards
metadata is caught up with master
data sync source: 91d15c30-f785-4bd1-8e80-d63ab939b259 (z1)
syncing
full sync: 0/128 shards
incremental sync: 128/128 shards
data is caught up with source注意: 虽然secondary zone可以接收bucket operations,但其实是通过将该操作转发给master zone来进行处理的,然后再将处理后的结果同步到secondary zone中。而假如master zone不能正常工作的话,在secondary zone中执行的bucket operations将会失败。但是object operations是可以成功的。
5、客户端测试
这里分别使用s3客户端和swift客户端测试。
5.1 s3客户端测试
[root@client1 ~]# yum -y install python-boto
[root@client1 ~]# vi s3test.py
import boto
import boto.s3.connection
access_key = ‘Y9WJW2H2N4CLDOOE8FN7‘
secret_key = ‘CsWtWc40R2kJSi0BEesIjcJ2BroY8sVv821c95ZD‘
boto.config.add_section(‘s3‘)
conn = boto.connect_s3(
aws_access_key_id = access_key,
aws_secret_access_key = secret_key,
host = ‘ceph01‘,
port = 8080,
is_secure=False,
calling_format = boto.s3.connection.OrdinaryCallingFormat(),
)
bucket = conn.create_bucket(‘my-new-bucket‘)
for bucket in conn.get_all_buckets():
print "{name} {created}".format(
name = bucket.name,
created = bucket.creation_date,
)
[root@client1 ~]# python s3test.py
my-new-bucket 2020-04-30T07:27:23.270Z5.2 swift客户端测试
创建Swift用户
[root@ceph01 ~]# radosgw-admin --cluster ceph1 subuser create --uid=candon --subuser=candon:swift --access=full
{
"user_id": "candon",
"display_name": "First User",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"subusers": [
{
"id": "candon:swift",
"permissions": "full-control"
}
],
"keys": [
{
"user": "candon",
"access_key": "Y9WJW2H2N4CLDOOE8FN7",
"secret_key": "CsWtWc40R2kJSi0BEesIjcJ2BroY8sVv821c95ZD"
}
],
"swift_keys": [
{
"user": "candon:swift",
"secret_key": "VZaiUF8DzLJYtT67Jg5tWZStDWHsmAi6K6KDuGQc"
}
],
"caps": [],
"op_mask": "read, write, delete",
"default_placement": "",
"default_storage_class": "",
"placement_tags": [],
"bucket_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"temp_url_keys": [],
"type": "rgw",
"mfa_ids": []
}--客户端
[root@client1 ~]# yum -y install python-setuptools
[root@client1 ~]# easy_install pip
[root@client1 ~]# pip install --upgrade setuptools
[root@client1 ~]# swift -A http://192.168.120.53:8080/auth/1.0 -U candon:swift -K ‘VZaiUF8DzLJYtT67Jg5tWZStDWHsmAi6K6KDuGQc‘ list
my-new-bucket6、failover验证
将z2设置为master:
[root@ceph05 ~]# radosgw-admin --cluster ceph2 zone modify --rgw-zone=z2 --master --default
{
"id": "04231ccf-bb2b-4eff-aba7-a7cb9a3505cf",
"name": "z2",
"domain_root": "z2.rgw.meta:root",
"control_pool": "z2.rgw.control",
"gc_pool": "z2.rgw.log:gc",
"lc_pool": "z2.rgw.log:lc",
"log_pool": "z2.rgw.log",
"intent_log_pool": "z2.rgw.log:intent",
"usage_log_pool": "z2.rgw.log:usage",
"reshard_pool": "z2.rgw.log:reshard",
"user_keys_pool": "z2.rgw.meta:users.keys",
"user_email_pool": "z2.rgw.meta:users.email",
"user_swift_pool": "z2.rgw.meta:users.swift",
"user_uid_pool": "z2.rgw.meta:users.uid",
"otp_pool": "z2.rgw.otp",
"system_key": {
"access_key": "ZA4TXA65C5TGCPX4B8V6",
"secret_key": "BEYnz6QdAvTbt36L7FhwGF2F5rHWeH66cb0eSO24"
},
"placement_pools": [
{
"key": "default-placement",
"val": {
"index_pool": "z2.rgw.buckets.index",
"storage_classes": {
"STANDARD": {
"data_pool": "z2.rgw.buckets.data"
}
},
"data_extra_pool": "z2.rgw.buckets.non-ec",
"index_type": 0
}
}
],
"metadata_heap": "",
"realm_id": "0f13bb55-68f6-4489-99fb-d79ba8ca959a"
}更新period:
[root@ceph05 ~]# radosgw-admin --cluster ceph2 period update --commit最后,重启集群节点中的每个gateway服务:
[root@ceph05 ~]# systemctl restart ceph-radosgw@rgw.`hostname -s`.rgw07、灾难恢复
当旧master zone恢复后,如果要切换为原来的zone为master,执行下面的命令:
[root@ceph01 ~]# radosgw-admin --cluster ceph1 realm pull --url=http://192.168.120.57:8080 --access-key=ZA4TXA65C5TGCPX4B8V6 --secret=BEYnz6QdAvTbt36L7FhwGF2F5rHWeH66cb0eSO24
{
"id": "0f13bb55-68f6-4489-99fb-d79ba8ca959a",
"name": "xzxj",
"current_period": "21a6550a-3236-4b99-9bc0-25268bf1a5c6",
"epoch": 3
}
[root@ceph01 ~]# radosgw-admin --cluster ceph1 zone modify --rgw-zone=z1 --master --default
[root@ceph01 ~]# radosgw-admin --cluster ceph1 period update --commit 然后在恢复的master节点上重启各个gateway服务
[root@ceph01 ~]# systemctl restart ceph-radosgw@rgw.`hostname -s`.rgw0如果要设置standby为read-only,在standby节点上使用下面的命令:
[root@ceph05 ~]# radosgw-admin --cluster ceph2 zone modify --rgw-zone=example --read-only
[root@ceph05 ~]# radosgw-admin --cluster ceph2 period update --commit最后重启standby节点上的gateway服务
[root@ceph05 ~]# systemctl restart ceph-radosgw@rgw.`hostname -s`.rgw08、Web管理界面点击object gateway报错故障处理
如果启用了web界面并设置了multi-site服务,当点击Web管理界面点击object gateway会报错,因为默认删除了默认的ceph-dashboard账户
[root@ceph01 ~]# radosgw-admin user info --uid=ceph-dashboard
could not fetch user info: no user info saved在master节点重建此用户:
[root@ceph01 ~]# radosgw-admin user create --uid=ceph-dashboard --display-name=ceph-dashboard --system记录下用户的access_key和secret_key,然后更新rgw-api-access-key和rgw-api-secret-key:
[root@ceph01 ~]# ceph dashboard set-rgw-api-access-key FX1L1DAY3JXI5J88VZLP
Option RGW_API_ACCESS_KEY updated
[root@ceph01 ~]# ceph dashboard set-rgw-api-secret-key UHArzi8B82sAMwMxUnkWH4dKy2O1iOCK25nV0rI1
Option RGW_API_SECRET_KEY updated到此,master上可以正常访问object gateway,而slave上还需要更新下rgw-api-access-key和rgw-api-secret-key。
最后,在slave集群任意一个节点更新rgw-api-access-key和rgw-api-secret-key:
[root@ceph06 ~]# ceph dashboard set-rgw-api-access-key FX1L1DAY3JXI5J88VZLP
Option RGW_API_ACCESS_KEY updated
[root@ceph06 ~]# ceph dashboard set-rgw-api-secret-key UHArzi8B82sAMwMxUnkWH4dKy2O1iOCK25nV0rI1
Option RGW_API_SECRET_KEY updated9、删除默认的zonegroup以及zone
如果不需要默认的zonegroup或者zone,在主备节点上删除即可。
[root@ceph01 ~]# radosgw-admin --cluster ceph1 zonegroup delete --rgw-zonegroup=default
[root@ceph01 ~]# radosgw-admin --cluster ceph1 zone delete --rgw-zone=default
[root@ceph01 ~]# radosgw-admin --cluster ceph1 period update --commit然后编辑/etc/ceph/ceph.conf文件,加入以下内容:
[mon]
mon allow pool delete = true同步ceph配置文件到其他节点后,重启所有mon服务,再删除默认的pool。
[root@ceph01 ~]# systemctl restart ceph-mon.target
[root@ceph01 ~]# ceph osd pool rm default.rgw.control default.rgw.control --yes-i-really-really-mean-it
[root@ceph01 ~]# ceph osd pool rm default.rgw.meta default.rgw.meta --yes-i-really-really-mean-it
[root@ceph01 ~]# ceph osd pool rm default.rgw.log default.rgw.log --yes-i-really-really-mean-it 以上是关于Ceph分布式存储双活服务配置的主要内容,如果未能解决你的问题,请参考以下文章