MapReduce基本认识
Posted msq2000
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MapReduce基本认识相关的知识,希望对你有一定的参考价值。
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。
主要由Split、Map、Partition、Sort、Combine(需要自己写)、Merge、Reduce组成,一般来说Split、Partition、Sort、Merge不需要工程师编程但是可以改写,主要是写出Map和Reduce中对数据的操作。
概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
统计单词个数
有Combine
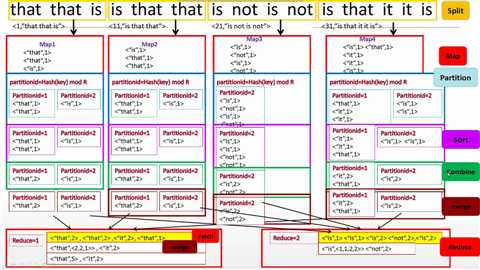
无Combine
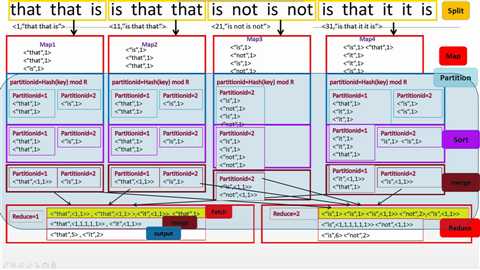
代码:
WordCount.java
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
/**
* @param args
* @throws IOException
* @throws InterruptedException
* @throws ClassNotFoundException
*/
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
Job job=Job.getInstance(conf,"WordCount");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordMapper.class);
//job.setCombinerClass(WordCount)
job.setReducerClass(WordReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job,new Path("/input"));
FileOutputFormat.setOutputPath(job, new Path("/output"));
System.exit(job.waitForCompletion(true)?0:1);
}
public static class WordMapper extends Mapper<Object ,Text, Text, IntWritable>{
protected void map(Object key, Text value ,Mapper<Object ,Text, Text, IntWritable>.Context context) throws IOException, InterruptedException{
String[] words = value.toString().split(" ");
for (String word:words){
context.write(new Text(word),new IntWritable(1));
}
}
}
public static class WordReducer extends Reducer<Text, IntWritable,Text, IntWritable>{
protected void reducer(Text key, Iterable<IntWritable> nums ,Reducer<Text, IntWritable,Text, IntWritable>.Context context) throws IOException, InterruptedException{
int sum=0;
for (IntWritable num:nums){
sum+=num.get();
}
context.write(key,new IntWritable(sum));
}
}
}
以上是关于MapReduce基本认识的主要内容,如果未能解决你的问题,请参考以下文章