Spark02
Posted qidi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark02相关的知识,希望对你有一定的参考价值。
1. RDD是什么?
- 官方定义:
- 不可变(immutable):RDD集合类似于Scala中不可变的集合,例如List,当对集合中的元素进行转换操作时,产生新的集合RDD
- 分区的(Partitioned):每个RDD集由有多个分区组成,分区就是很多部分。
- 并行操作(Parallel):对RDD集合操作时,可以同时对多有的分区并行操作
- 容灾分配(failure recovery):RDD分区中书数据具有恢复功能,每个RDD记录从哪里来,如何依赖。
- 查看源码发现特点:
* Internally, each RDD is characterized by five main properties:
* - A list of partitions
第一点:一个RDD有一系列分区Partition组成
protected def getPartitions: Array[Partition]
* - A function for computing each split
第二点:RDD中每个分区数据可以被处理分析(计算)
def compute(split: Partition, context: TaskContext): Iterator[T]
* - A list of dependencies on other RDDs
第三点:每个RDD依赖一些列RDD
protected def getDependencies: Seq[Dependency[_]] = deps
* - Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
第四点:可选的特性,针对KeyValue类型RDD,可以设置分区器,将每个RDD中各个分区数据重新划分,类似MapReduce中分区器Partitioner。
@transient val partitioner: Option[Partitioner] = None
* - Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
第五点:可选的特性,对RDD中每个分区数据处理时,得到最好路径,类似MapReduce中数据本地性
protected def getPreferredLocations(split: Partition): Seq[String] = Nil
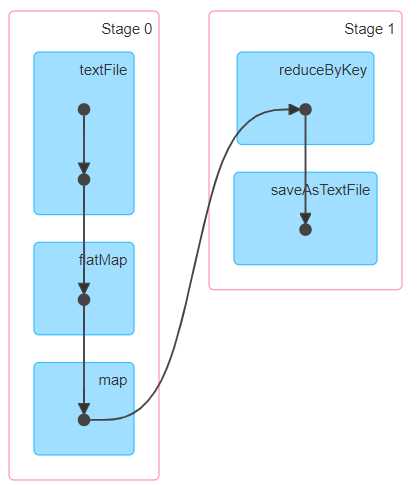
总结来说具有以下五点:
- 分区列表
- 计算函数
- 依赖关系
- 分区函数
- 最佳位置
2. 创建RDD

A:读取外部数据源的数据
def textFile(
path: String, // 第一个参数表示:数据路径,可以是LocalFS、也可以是HDFS
minPartitions: Int = defaultMinPartitions // 第二参数表示:RDD分区数目
): RDD[String]
B:并行化集合
将Scala或者Java或者Python中集合转换为RDD
def parallelize[T: ClassTag](
seq: Seq[T], // 集合,针对Scala语言来说,就是序列Seq
numSlices: Int = defaultParallelism // 表示RDD分区数目
): RDD[T]
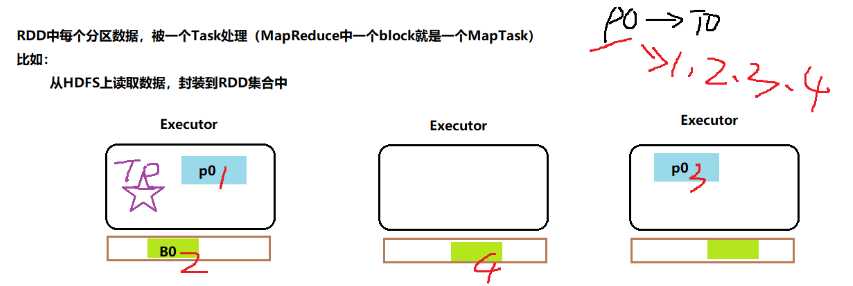
C:从Hdfs或者LocalFS读取文件的时候RDD的默认分区是如何确定的?
RDD的分区数目通常是Spark Application中Executor CPU Core核数之和的2-3倍。比如Spark Application有5个Executor,每个Executor的CPU核数为8核。计算RDD分区的数目最好为多少?
all-executor-cpu-cores = 5 * 8 = 40
所以:
rdd-partitions = 40 * 2 - 40 * 3 = 80 - 120 之间
总结:开发测试时,数据量很小,无论是parallelize还是textFile,手动指定分区的数目为2,在实际开发中,往往是在hdfs中读取数据,并且数据量很多,使用默认的即可。
3. RDD Operations
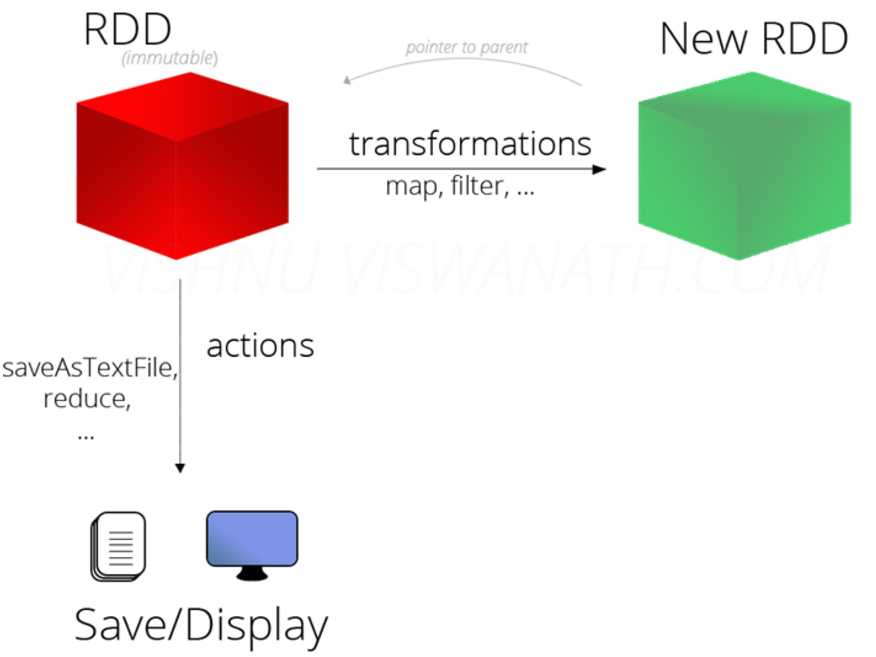
A:转换函数
- RDD调用转换函数后产生一个新的RDD
- 使用最多如,map,flatMap,reduceByKey
- 调用转换函数后,不会立即执行,需要等待触发函数执行
B:Action函数
- 此类函数触发job的执行,count
C:持久化函数
- 将数据集RDD保存到内存或磁盘中
4. RDD重要函数
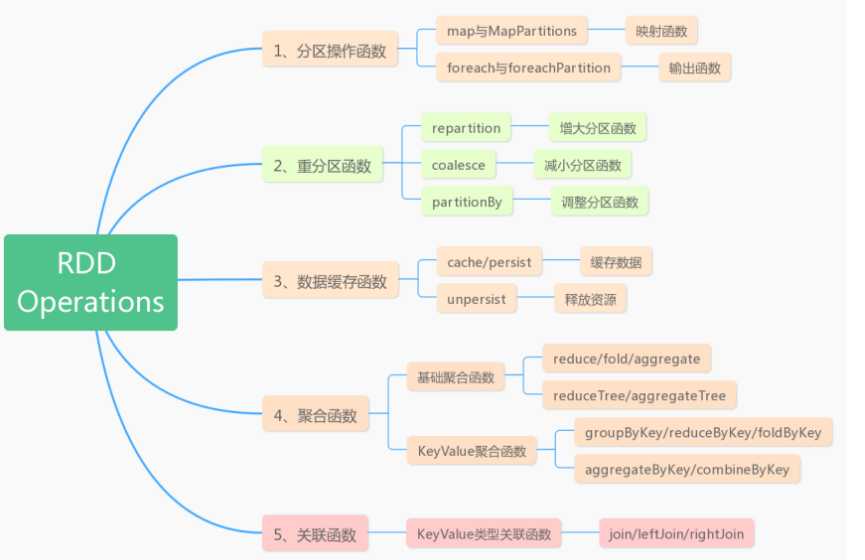
A:分区操作函数


// 1. 映射函数 map和mapPartitions def map[U: ClassTag](f: T => U): RDD[U] // 针对每个元素处理操作 def mapPartitions[U: ClassTag]( // 将每个分区数据封装到迭代器Iterator中 f: Iterator[T] => Iterator[U], preservesPartitioning: Boolean = false ): RDD[U] // 2. 输出函数 foreach和foreachPartition /** * Applies a function f to all elements of this RDD. */ def foreach(f: T => Unit): Unit /** * Applies a function f to each partition of this RDD. */ def foreachPartition(f: Iterator[T] => Unit): Unit
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * 词频统计WordCount,使用分区函数操作RDD中数据:mapPartitions和foreachPartition */ object SparkIterWordCount { def main(args: Array[String]): Unit = { // TODO: 构建SparkContext上下文实例对象 val sc: SparkContext = { // a. 创建SparkConf对象,设置应用配置信息 val sparkConf = new SparkConf() .setMaster("local[2]") .setAppName(this.getClass.getSimpleName.stripSuffix("$")) // b. 创建SparkContext, 有就获取,没有就创建,建议使用 val context = SparkContext.getOrCreate(sparkConf) // c. 返回对象 context } sc.setLogLevel("WARN") // TODO: 读取本地文件系统文本文件数据 val datasRDD: RDD[String] = sc.textFile( "datas/wordcount/input/wordcount.data", minPartitions = 2) println(s"Count = ${datasRDD.count()}") // 词频统计 val resultRDD: RDD[(String, Int)] = datasRDD // 数据分析,考虑过滤脏数据 .filter(line => null != line && line.trim.length > 0) // TODO: 分割单词,注意去除左右空格 .flatMap(line => line.trim.split("\\s+")) // 转换为二元组,表示单词出现一次 .mapPartitions{iter => iter.map(word => (word, 1)) } // 分组聚合,按照Key单词 .reduceByKey((tmp, item) => tmp + item) // 输出结果RDD resultRDD.foreachPartition(iter => iter.foreach(println)) // 应用结束,关闭资源 sc.stop() } }
应用场景:处理网站日志数据,数据量为10GB。统计各个省份PV和UV。假设10GB日志数据,从HDFS上读取,此时RDD的分区数目:80分区。
但是分析PV和UV有多少条数据:34,存储在80个分区中,这样有很多分区的数据就很少,所以就需要降低数据,比如设置两个分区:
p0:24条数据
p1:10条数据
0现在需要将结果RDD保存在mysql数据库表中,foreach函数就需要创建34个数据库连接,使用foreachPartition函数,针对每个分区数据操作,知足要创建两个数据库文件。
B:重分区函数
在实际项目中,需要根据需求调整分区的个数。
增加分区
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
实际项目很多时候业务数据存储到HBase表中,数据对应到各个Region中,此时要分析的就需要从HBase中读取数据,假设HBase中表的Region数目为30个,那么SparkCore读取数据以后,封装的RDD的分区数目就是30个。
默认:rdd-partitions = table-regions
但是每个Region中的数据量大概时5GB数据,对于读取到RDD的每个分区中来说,数据量也是5GB,当一个Task处理一个分区的数据,显得很大,此时需要增加RDD的分区数目。
val etlRDD = hbaseRDD.repartition(40 * 30)
etlRDD-partitions = 1200
减少分区
1、当对RDD数据使用filter函数过滤以后,需要考虑是否降低分区数目
比如从ES中获取数据封装到RDD中, 分区数目为50个分区,数据量为20GB
val etlRDD = esRDD.filter(.......)
过滤以后数据量为12GB,此时考虑降低分区数目
etlRDD.coalesce(35)
2、当将分析结果RDD(resultRDD)保存到外部存储系统时,需要考虑降低分区数目
resultRDD.coalesce(1).foreachPartition()
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * 词频统计WordCount,调整RDD的分区数目 */ object SparkPartitionAdjust { def main(args: Array[String]): Unit = { // TODO: 构建SparkContext上下文实例对象 val sc: SparkContext = { // a. 创建SparkConf对象,设置应用配置信息 val sparkConf = new SparkConf() .setMaster("local[2]") .setAppName(this.getClass.getSimpleName.stripSuffix("$")) // b. 创建SparkContext, 有就获取,没有就创建,建议使用 val context = SparkContext.getOrCreate(sparkConf) // c. 返回对象 context } sc.setLogLevel("WARN") // 读取本地文件系统文本文件数据 val datasRDD: RDD[String] = sc.textFile("datas/wordcount/input/wordcount.data", minPartitions = 2) //println(s"Count = ${datasRDD.count()}") // TODO: 增加RDD分区数 val etlRDD: RDD[String] = datasRDD.repartition(3) println(s"EtlRDD 分区数目 = ${etlRDD.getNumPartitions}") // 词频统计 val resultRDD: RDD[(String, Int)] = etlRDD // 数据分析,考虑过滤脏数据 .filter(line => null != line && line.trim.length > 0) // 分割单词,注意去除左右空格 .flatMap(line => line.trim.split("\\s+")) // 转换为二元组,表示单词出现一次 .mapPartitions{iter => iter.map(word => (word, 1)) } // 分组聚合,按照Key单词 .reduceByKey((tmp, item) => tmp + item) // 输出结果RDD resultRDD // TODO: 对结果RDD降低分区数目 .coalesce(1) .foreachPartition(iter => iter.foreach(println)) // 应用结束,关闭资源 sc.stop() } }
C:缓存函数
/**
* Persist this RDD with the default storage level (`MEMORY_ONLY`).
*/
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)/**
* Persist this RDD with the default storage level (`MEMORY_ONLY`).
*/
def cache(): this.type = persist()
缓存级别
// 不缓存
val NONE = new StorageLevel(false, false, false, false)// 缓存数据到磁盘
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2) // 副本数//缓存数据到内存(Executor中内存)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
// 是否将数据序列化以后存储内存中
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)// 缓存数据到内存和磁盘,当内存不足就缓存到磁盘,使用最多
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)// 缓存数据到系统内存中
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
常用
MEMORY_AND_DISK_2
MEMORY_AND_DISK_SER_2
具体代码
datasRDD.persist(StorageLevel.MEMORY_AND_DISK_2)
何时缓存
1、当某个RDD被使用多次,大于等于2次以上
2、当某个RDD来之不易,使用不止一次,建议缓存
释放数据
def unpersist(blocking: Boolean = true): this.type
D:聚合函数
def reduce[A1 >: A](op: (A1, A1) => A1): A1
def fold[A1 >: A](z: A1)(op: (A1, A1) => A1): A1

def reduce(f: (T, T) => T): T
// 可以初始化聚合中间临时变量的值
def fold(zeroValue: T)(op: (T, T) => T): T
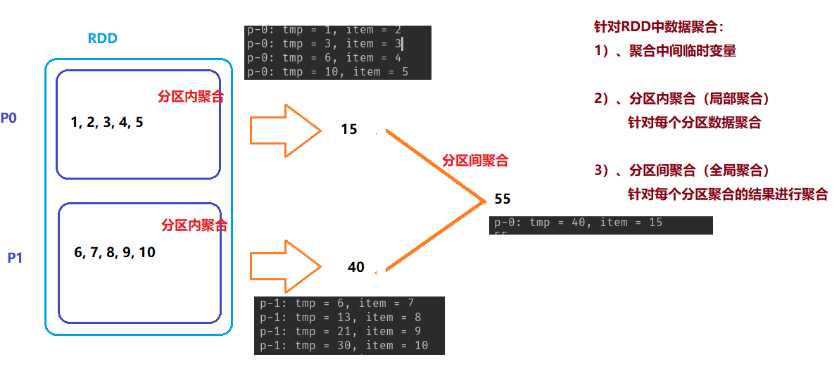
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext, TaskContext} import scala.collection.mutable import scala.collection.mutable.ListBuffer object SparkAggr { def main(args: Array[String]): Unit = { val sc: SparkContext = { val sparkConf: SparkConf = new SparkConf() .setMaster("local[2]") .setAppName(this.getClass.getSimpleName.stripSuffix("S")) val context = new SparkContext(sparkConf) context } sc.setLogLevel("WARN") val datas = 1 to 10 val datasRDD: RDD[Int] = sc.parallelize(datas, numSlices = 2) datasRDD.foreachPartition { iter => println(s"p-${TaskContext.getPartitionId()}: ${iter.mkString(", ")}") } println("=========================================") // 使用reduce函数聚合 val result: Int = datasRDD.reduce((tmp, item) => { println(s"p-${TaskContext.getPartitionId()}: tmp = $tmp, item = $item") tmp + item }) println(result) // 使用aggregate函数获取最大的两个值 val top2: mutable.Seq[Int] = datasRDD.aggregate(new ListBuffer[Int]())( // 分区内聚合函数,每个分区内数据如何聚合 seqOp: (U, T) => U, (u, t) => { println(s"p-${TaskContext.getPartitionId()}: u = $u, t = $t") // 将元素加入到列表中 u += t // // 降序排序 val top = u.sorted.takeRight(2) // 返回 top }, // 分区间聚合函数,每个分区聚合的结果如何聚合 combOp: (U, U) => U (u1, u2) => { println(s"p-${TaskContext.getPartitionId()}: u1 = $u1, u2 = $u2") u1 ++= u2 // 将列表的数据合并,到u1中 // u1.sorted.takeRight(2) } ) println(top2) } }
def aggregate[U: ClassTag]
(zeroValue: U) // 聚合中间临时变量初始值,先确定聚合中间临时变量的类型
(
// 分区内聚合函数,每个分区内数据如何聚合
seqOp: (U, T) => U,
// 分区间聚合函数,每个分区聚合的结果如何聚合
combOp: (U, U) => U
): U
4. 关联函数
class PairRDDFunctions[K, V](self: RDD[(K, V)])
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]
中RDD的关联操作 */ object SparkJoinFunc { def main(args: Array[String]): Unit = { // TODO: 构建SparkContext上下文实例对象 val sc: SparkContext = { // a. 创建SparkConf对象,设置应用配置信息 val sparkConf = new SparkConf() .setMaster("local[2]") .setAppName(this.getClass.getSimpleName.stripSuffix("$")) // b. 创建SparkContext, 有就获取,没有就创建,建议使用 val context = SparkContext.getOrCreate(sparkConf) // c. 返回对象 context } sc.setLogLevel("WARN") // 模拟数据集 val empRDD: RDD[(Int, String)] = sc.parallelize( Seq((1001, "zhangsan"), (1001, "lisi"), (1002, "wangwu"), (1002, "zhangliu")) ) val deptRDD: RDD[(Int, String)] = sc.parallelize( Seq((1001, "sales"), (1002, "tech")) ) val joinRDD: RDD[(Int, (String, String))] = empRDD.join(deptRDD) joinRDD.foreach{case (deptno, (ename, dname)) => println(s"deptno = $deptno, ename = $ename, dname = $dname") } // 应用结束,关闭资源 sc.stop() } }
5. Spark案例
60.208.6.156 - - [18/Sep/2013:06:49:48 +0000] - 5
"GET /wp-content/uploads/2013/07/rcassandra.png HTTP/1.0" 200 185524 - 5
"http://cos.name/category/software/packages/" - 1
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/29.0.1547.66 Safari/537.36"如何获取字段的值:
怎么从日志文件中获取呢???
1)、分割获取
企业不会这么干
2)、编写正则匹配获取对应字段的值
Regex需求:PV、UV、TopK Refer(外链)
分析:
1. pv - url 第7个字段
网站页面的访问量,url 不能为null
2. uv - ip 第1个字段
独立访客数,在网站收集数据的时候,通常特定字段,标识用户的唯一性,此处使用ip地址
3. TopKey Refer - referUrl 第11个字段
统计最多的外链Refer,前20个
import org.apache.spark.rdd.RDD import org.apache.spark.storage.StorageLevel import org.apache.spark.{SparkConf, SparkContext} /** 分析: *1. pv - url * 网站页面的访问量,url 不能为null *2. uv - ip * 独立访客数,在网站收集数据的时候,通常特定字段,标识用户的唯一性,此处使用ip地址 *3. TopKey Refer - referUrl * 统计最多的外链Refer,前20个 */ object SparkAccessAnalysis { def main(args: Array[String]): Unit = { // 构建SparkContext上下文实例对象 val sc: SparkContext = { // a. 创建SparkConf对象,设置应用配置信息 val sparkConf = new SparkConf() .setMaster("local[2]") .setAppName(this.getClass.getSimpleName.stripSuffix("$")) // b. 创建SparkContext, 有就获取,没有就创建,建议使用 val context = SparkContext.getOrCreate(sparkConf) // c. 返回对象 context } sc.setLogLevel("WARN") // TODO: 从本地文件系统读取日志数据 val accessLogsRDD: RDD[String] = sc.textFile("datas/logs/access.log", minPartitions = 2) // TODO: 过滤、提取字段(数据ETL) val etlRDD: RDD[(String, String, String)] = accessLogsRDD // 过滤不合格的数据 .filter(log => null != log && log.trim.split("\\s").length >= 11) // 对每条日志数据提取ip、url和referUrl .mapPartitions{iter => iter.map{log => // 按照空格分割单词 val arr: Array[String] = log.trim.split("\\s") // 使用三元组返回(ip, url, refer) (arr(0), arr(6), arr(10)) } } // 由于后续使用ETL的RDD多次,将数据缓存 etlRDD.persist(StorageLevel.MEMORY_AND_DISK) // TODO: 业务一、pv统计 val pvTotal: Long = etlRDD // 提取出url字段 .map(tuple => tuple._2) // 过滤url为空 .filter(url => null != url && url.trim.length > 0) .count() println(s"pv = $pvTotal") // TODO: 业务二、uv统计 val uvTotal: Long = etlRDD .map(tuple => tuple._1) // 提取字段 .filter(ip => null != ip && ip.trim.length > 0) // 过滤 // 去重函数 .distinct() .count() println(s"uv = $uvTotal") // TODO: 业务三、TopKey Refer -> 词频统计WordCount变形 val topReferUrl: Array[(String, Int)] = etlRDD .map(tuple => (tuple._3, 1)) // 提取字段,表示一次 .filter(pair => null != pair._1 && pair._1.trim.length > 0) // 过滤数据 // 按照referUrl分组聚合 .reduceByKey((tmp, item) => tmp + item) // 按照次数降序排序,使用sortBy .sortBy(tuple => tuple._2, ascending = false) // 获取前20个Refer Url .take(20) topReferUrl.foreach(println) // 数据不再使用,释放资源 etlRDD.unpersist() // 应用结束,关闭资源 sc.stop() } }
6. 数据源
A:MySQL数据库交互
CREATE TABLE `tb_wordcount` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`word` varchar(255) NOT NULL,
`count` bigint(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM AUTO_INCREMENT=7 DEFAULT CHARSET=latin1;
B:保存数据到MySQL
import java.sql.{Connection, DriverManager, PreparedStatement} import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.rdd.RDD /** * 将词频统计结果保存到MySQL表中 */ object SparkWriteMySQL { def main(args: Array[String]): Unit = { // TODO: 构建SparkContext上下文实例对象 val sc: SparkContext = { // a. 创建SparkConf对象,设置应用配置信息 val sparkConf = new SparkConf() .setMaster("local[2]") .setAppName(this.getClass.getSimpleName.stripSuffix("$")) // b. 创建SparkContext, 有就获取,没有就创建,建议使用 val context = SparkContext.getOrCreate(sparkConf) // c. 返回对象 context } sc.setLogLevel("WARN") // TODO: 读取本地文件系统文本文件数据 val datasRDD: RDD[String] = sc.textFile("datas/wordcount/input/wordcount.data", minPartitions = 2) // 词频统计 val resultRDD: RDD[(String, Int)] = datasRDD // 数据分析,考虑过滤脏数据 .filter(line => null != line && line.trim.length > 0) // TODO: 分割单词,注意去除左右空格 .flatMap(line => line.trim.split("\\s+")) // 转换为二元组,表示单词出现一次 .mapPartitions{iter => iter.map(word => (word, 1)) } // 分组聚合,按照Key单词 .reduceByKey((tmp, item) => tmp + item) // 输出结果RDD resultRDD // 对结果RDD保存到外部存储系统时,考虑降低RDD分区数目 .coalesce(1) // 对分区数据操作 .foreachPartition{iter => // val xx: Iterator[(String, Int)] = iter saveToMySQL(iter) } // 应用结束,关闭资源 sc.stop() } /** * 将每个分区中的数据保存到MySQL表中 * * @param datas 迭代器,封装RDD中每个分区的数据 */ def saveToMySQL(datas: Iterator[(String, Int)]): Unit = { // a. 加载驱动类 Class.forName("com.mysql.jdbc.Driver") // 声明变量 var conn: Connection = null var pstmt: PreparedStatement = null try{ // b. 获取连接 conn = DriverManager.getConnection( "jdbc:mysql://bigdata-cdh01.itcast.cn:3306/", "root", "123456" ) // c. 获取PreparedStatement对象 val insertSql = "INSERT INTO test.tb_wordcount (word, count) VALUES(?, ?)" pstmt = conn.prepareStatement(insertSql) // d. 将分区中数据插入到表中,批量插入 datas.foreach{case (word, count) => pstmt.setString(1, word) pstmt.setLong(2, count.toLong) // 加入批次 pstmt.addBatch() } // TODO: 批量插入 pstmt.executeBatch() }catch { case e: Exception => e.printStackTrace() }finally { if(null != pstmt) pstmt.close() if(null != conn) conn.close() } } }
C:MySQL表读取数据
class JdbcRDD[T: ClassTag](
// 表示SparkContext实例对象
sc: SparkContext,
// 连接数据库Connection
getConnection: () => Connection,
// 查询SQL语句
sql: String,
// 下限
lowerBound: Long,
// 上限
upperBound: Long,
// 封装数据RDD的分区数目
numPartitions: Int,
// 表示读取出MySQL数据库表中每条数据如何处理,数据封装在ResultSet
mapRow: (ResultSet) => T = JdbcRDD.resultSetToObjectArray _
) extends RDD[T](sc, Nil)
import java.sql.{DriverManager, ResultSet} import org.apache.spark.rdd.JdbcRDD import org.apache.spark.{SparkConf, SparkContext} /** * 从MySQL数据库表中读取数据 */ object SparkReadMySQL { def main(args: Array[String]): Unit = { // TODO: 构建SparkContext上下文实例对象 val sc: SparkContext = { // a. 创建SparkConf对象,设置应用配置信息 val sparkConf = new SparkConf() .setMaster("local[2]") .setAppName(this.getClass.getSimpleName.stripSuffix("$")) // b. 创建SparkContext, 有就获取,没有就创建,建议使用 val context = SparkContext.getOrCreate(sparkConf) // c. 返回对象 context } sc.setLogLevel("WARN") // TODO: 读取MySQL数据库中db_orders.so表的数据 /* class JdbcRDD[T: ClassTag]( // 表示SparkContext实例对象 sc: SparkContext, // 连接数据库Connection getConnection: () => Connection, // 查询SQL语句 sql: String, // 下限 lowerBound: Long, // 上限 upperBound: Long, // 封装数据RDD的分区数目 numPartitions: Int, // 表示读取出MySQL数据库表中每条数据如何处理,数据封装在ResultSet mapRow: (ResultSet) => T = JdbcRDD.resultSetToObjectArray _ ) */ val sosRDD: JdbcRDD[(Long, Double)] = new JdbcRDD[(Long, Double)]( sc, // () => { // a. 加载驱动类 Class.forName("com.mysql.jdbc.Driver") // b. 获取连接 val conn = DriverManager.getConnection( "jdbc:mysql://bigdata-cdh01.itcast.cn:3306/", "root", "123456" ) // c. 返回连接 conn }, // "select user_id, order_amt from db_orders.so where ? <= order_id and order_id <= ?", // 314296308301917L, // 314296313681142L, // 2, // (rs: ResultSet) => { // 获取user_id val userId = rs.getLong("user_id") // 获取order_amt val orderAmt = rs.getDouble("order_amt") // 返回二元组 (userId, orderAmt) } ) println(s"count = ${sosRDD.count()}") sosRDD.foreach(println) // 应用结束,关闭资源 sc.stop() } }
列举RDD中常用函数及其功能,使用场景
以上是关于Spark02的主要内容,如果未能解决你的问题,请参考以下文章