5.3.1 sequenceFile读写文件记录边界同步点压缩排序格式
Posted bclshuai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了5.3.1 sequenceFile读写文件记录边界同步点压缩排序格式相关的知识,希望对你有一定的参考价值。
5.3.1 sequenceFile读写文件、记录边界、同步点、压缩排序、格式
HDFS和MapReduce是针对大文件优化的存储文本记录,不适合二进制类型的数据。SequenceFile作为小文件的容器,SequenceFile类型将小文件包装起来,可以获得更高效率的存储和处理。sequenceFile类非常适合日志形式的存储方式,将日志记录按照【key,value】(key对应行号,valuse内容,key和value不一定需要writable类型,可以任意可序列化的类型)对格式存储,sequenceFile可以高效存储小文件。
(1)写入数据到文件
通过createWriter创建写入对象writer,通过writer的append函数追加到文件末尾,写完后调用close关闭。
public class SequenceFileWriteDemo {
private static final String[] DATA = { "One, two, buckle my shoe",
"Three, four, shut the door", "Five, six, pick up sticks",
"Seven, eight, lay them straight", "Nine, ten, a big fat hen" };
public static void main(String[] args) throws IOException {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
IntWritable key = new IntWritable();
Text value = new Text();
SequenceFile.Writer writer = null;
try {
//根据文件系统,配置,路径,键值的类名创建writer
writer = SequenceFile.createWriter(fs, conf, path, key.getClass(), value.getClass());
for (int i = 0; i < 100; i++) {
key.set(100 - i);
value.set(DATA[i % DATA.length]);
System.out.printf("[%s] %s %s ", writer.getLength(), key,
value);
//append追加数据
writer.append(key, value);
}
} finally {
//关闭数据流
IOUtils.closeStream(writer);
}
}
}
(2)从文件读取数据
通过SequenceFile.Reader reader =SequenceFile.Reader(fs, path, conf);函数返回reader对象,然后通过reader.next(key,value)去遍历获取数据,末尾返回false;
public class SequenceFileReadDemo {
public static void main(String[] args) throws IOException {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
SequenceFile.Reader reader = null;
try {
reader = new SequenceFile.Reader(fs, path, conf);
Writable key = (Writable) ReflectionUtils.newInstance(
reader.getKeyClass(), conf);
Writable value = (Writable) ReflectionUtils.newInstance(
reader.getValueClass(), conf);
long position = reader.getPosition();
while (reader.next(key, value)) {
String syncSeen = reader.syncSeen() ? "*" : "";
System.out.printf("[%s%s] %s %s ", position, syncSeen, key,
value);
position = reader.getPosition(); // beginning of next record
}
} finally {
IOUtils.closeStream(reader);
}
}
}
(3)其他序列化框架调用方法
对于其他非Writable类型的序列化框架(比如Apache Thrift),则应该使用下面两个方法:
public Object next(Object key) throws IOException
public Object getCurrentValue(Object val) throws IIOException
在这种情况下,需要确保io.serializations属性已经设置了你想使用的序列化框架。如果next()方法返回的是非null对象,则可以从数据流中读取键、值对,并且可以通过getCurrentValue()方法读取该值。否则,如果next()返回null值,则表示已经读到文件末尾。
(4)记录边界和同步点
记录边界:是每条记录和前后记录交界的地方,是一记录开始或结束的地方。使用reader.next()获取记录时需要从记录边界开始读取,否则会出现IOException。
同步点:同步点是由SequenceFile.Writer记录的,在顺序文件写入过程中插入一个特殊项以便每隔几个记录便有一个同步标识。同步点会占用很小的存储空间。同步点是为了方便读取数据而设立的,读取数据时,由于搜索而跑到任意位置,非记录边界读取会引起异常,这时就需要通过同步点找下一个记录边界。
通过同步点查找记录边界。SequenceFile.Reader记录sync(long position)方法可以将读取位置定位到position之后的下一个同步点。如果position之后没有同步了,那么当前读取位置将指向文件末尾。这样,我们对数据流中的任意位置调用sync()方法(不一定是一个记录的边界)而且可以重新定位到下一个同步点并继续向后读取:
reader.sync(360);
assertThat(reader.getPosition(), is(2021L));
assertThat(reader.next(key, value), is(true));
assertThat(((IntWritable) key).get(), is(59));
SequenceFile.Writer对象有一个Sync()方法,该方法可以在数据流的当前位置插入一个同步点。
另外一种搜索记录边界的方法是调用seek(int position)方法,但是只能知道提前知道记录边界的指定位置。该方法将读指针指向文件中指定的position位置。例如,可以按如下方式搜查记录边界:
reader.seek(359);
assertThat(reader.next(key, value), is(true));
assertThat(((IntWritable) key).get(), is(95));
但如果给定位置不是记录边界,调用next()方法时就会出错:
reader.seek(360);
reader.next(key, value); // fails with IOException
(5)查看序列化文件
可以用hadoop fs –text number.seq | head查看文件的文本。可以识别gzip压缩文件,顺序文件和Avro数据文件。
(6)输出排序后的sequenceFile文件
Hadoop执行mapreduce任务时,指定sort -r进行排序,inFormat指定指定输入文件类型,outFormat指定输出文件类型,outKey指定输出键类型,outValue指定输出值类型,最后加上出入文件和输出文件路径,执行完任务后,在输出文件夹sorted中有生成的输出文件,是排好序的。
(7)sequenceFile文件格式
SequenceFile文件内容由文件头hearder(SEQ、版本、键和值类的名称、数据压缩细节、用户定义的元数据),记录,同步标识组成。
记录的内部结构取决于是否启用压缩。压缩方式有记录压缩和数据块压缩。记录压缩是单挑记录值进行压缩,数据块压缩是一次性对多条记录压缩,可以不断向数据块中压缩记录,直到块的字节数不小于io.seqfile.compress.blocksize属性中设置的字节数:默认为1MB。每一个新块的开始处都需要插入同步标识。
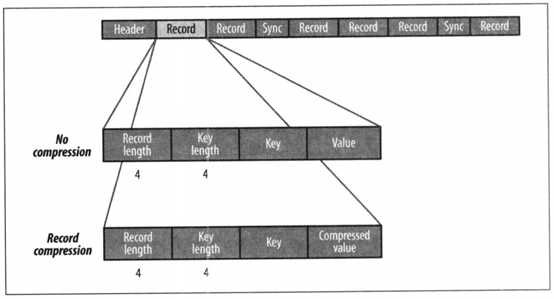
记录压缩
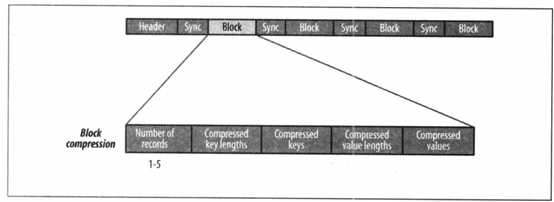
数据块压缩
以上是关于5.3.1 sequenceFile读写文件记录边界同步点压缩排序格式的主要内容,如果未能解决你的问题,请参考以下文章
Hadoop IO操作之SequenceFile 和 MapFile
大数据系列基于MapReduce的数据处理 SequenceFile序列化文件
执行Hadoop job提示SequenceFile doesn't work with GzipCodec without native-hadoop code的解决过程记录