第三范式之上
Posted gggong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第三范式之上相关的知识,希望对你有一定的参考价值。
说到范式,经常碰到的一个说法就是,数据库设计满足第三范式就可以了,足够了。这个说法有时给人一种暗示,满足更高的范式是件复杂的事情,或至少是件繁琐的事情,没必要。
但实际上,很多模型一旦满足了第三范式,往往也已经满足了更高的范式。一些以第三范式为标准设计的库,很可能也已满足第四甚至第五范式,尽管它称呼起来都是说满足了第三范式。
现实中的业务往往有着自身的规律与约束,一个库模型,在满足第三范式时也满足了更高的范式,有时是一个很自然的事。相反,满足了第三范式但违反了更高的范式,这时候就要小心对待,这里很容易发生设计错误。
在实际的操作中,高范式往往代表着更多的连接,有时为了更好的响应速度、更便捷的某些操作,设计时会特意降低范式或违反范式。这种设计理念与本文的重点----“满足了第三范式但违反了更高的范式,这时候很容易发生设计错误”要注意区分开。
在继续下文前,先回顾下前三个范式的概念:
第一范式,表的列(关系的属性)是不可再分的,不能是复合的,每一列各自表示一个属性。这个也是关系数据库最基本的要求,不满足第一范式也就无法说什么关系的数据库。
第二范式,在第一范式的基础上,表中的每一行可以被唯一地区分。
第三范式,满足第二范式,并在候选键上不存在传递依赖。
“一个设计满足了第三范式,但可能违反了更高范式”--这条警示什么时候该响起?以下诸情况就是一些高危区:1.一个表是否与多个表关联,特别是参与了多个多对多关系。2表包含着复合键。3使用的不是自然键而是代理键。
下面以一些容易出错的关系表举例:
1.满足第三范式,但不满足第四范式
第四范式关注的是多值依赖。
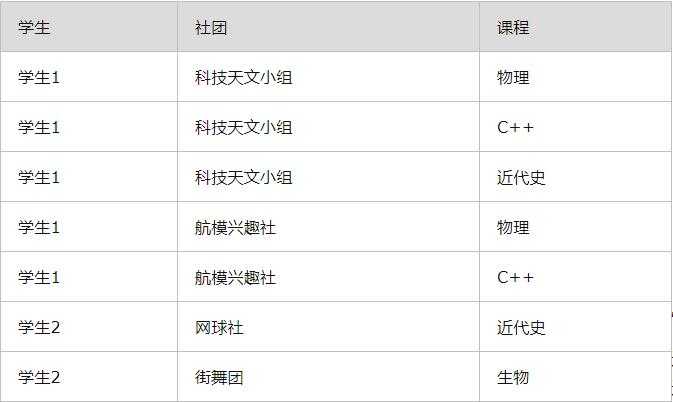
1.1 学生关系表
学生关系表(学生,社团,课程)
显然,学生可以参加多个社团,也需要学习多个课程,这个表中社团属性依赖于学生,课程属性也依赖于学生,然后这2个属性有多种组合数据,这违反了第四范式。
现实中社团与课程的组合意义不大,容易判断。
如下面关系表的记录。注意这里为方便描述给的是模拟记录,实际中三个字段存的更可能是id值并且是三个表的外键。
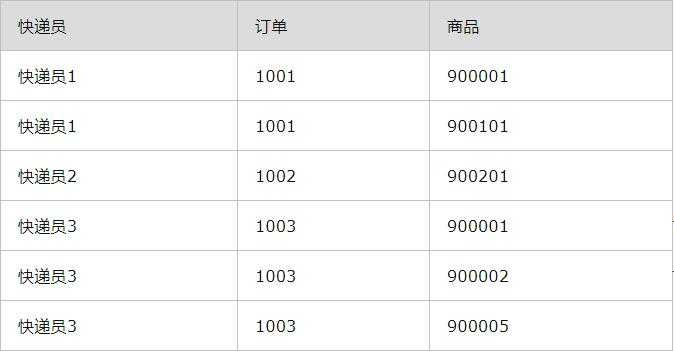
1.2 快递送货表
快速送货表(快递员,订单,商品)
这里快递员按照订单进行派送,将订单上的所有商品送到顾客手上。
这种类型的模型也包含着多值依赖,并且这种模型一个高危的地方在于,每安排一个订单,可能需要插入多条数据,如某订单中包含3件商品,就必须插入三条数据。这里的更新容易造成数据不当。
该模型可以分解为2个关系表:
关系表1
(快递员,订单)
关系表2
(订单,商品)
2. 满足第三范式,但违反第五范式
第五范式要求候选键能推导出所有连接依赖。
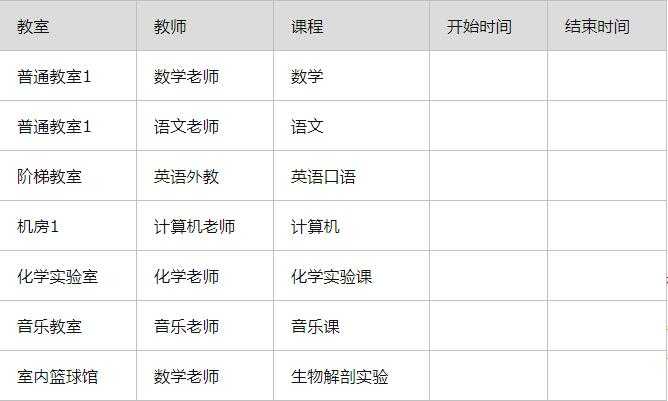
2.1 教学日程计划表
教学日程计划表(教室 ,教师 ,课程)
在这个模型中,教师有教学任务,课程安排在具体的教室进行。即使老师们个个都是全能,什么课都能教,课程安排也要与教室类型匹配,生物课拿着待解剖的青蛙跑到钢琴教室显然不合适,现实中的老师也各有所长,虽然数学语文老师常来教体育课,但你应该不希望你的数学语文是体育老师教的。调侃的话不多说,这个模型里有2个依赖:1.课程依赖教室的类型。2.教师依赖具体的课程。
如下教学日程计划表模拟数据:
模型涉及的表如下:
教师表(TeacherID,Name)
教室表(RoomID,RoomName)
课目表(CourseID,CourseName)
教师任教表(TeacherID,CourseID)
教室科目表(RoomID,CourseID)
日程计划表(TeacherID,CourseID,RoomID,StartTime,EndTime)
模型: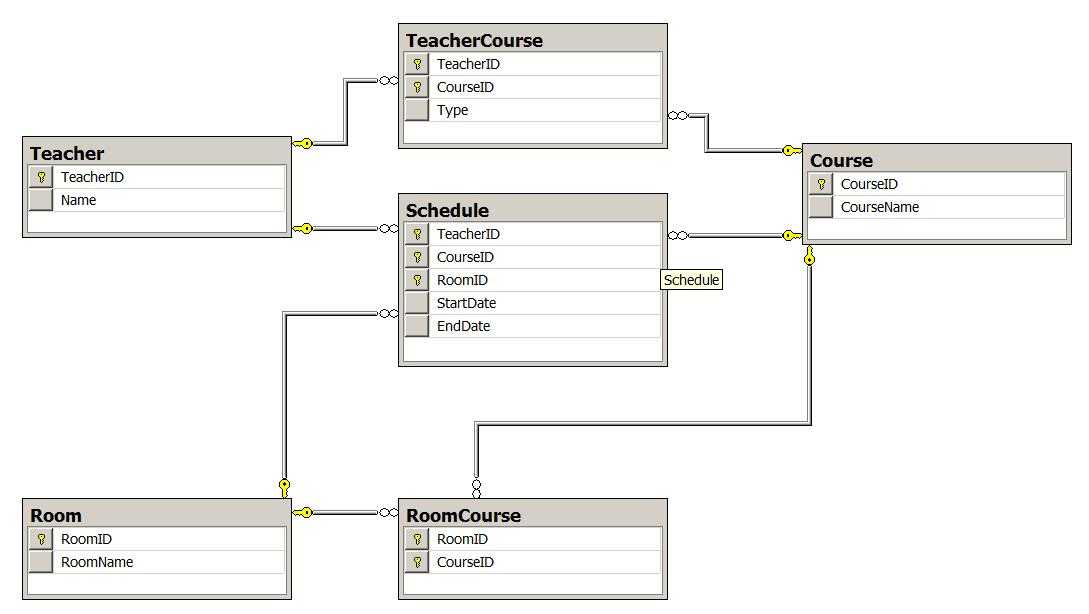
如上图,日程计划表中的三个外键TeacherID,CourseID,RoomID组成联合主键,并分别关联三个实体表Teacher,Course,Room。这种情况无法避免如上面(教学日程计划表)模拟数据最后一条记录,室内篮球馆本来应该上体育课,但安排了生物实验课,任课老师也发生错误安排了数学老师。
为防止异常数据,模型可以调整为: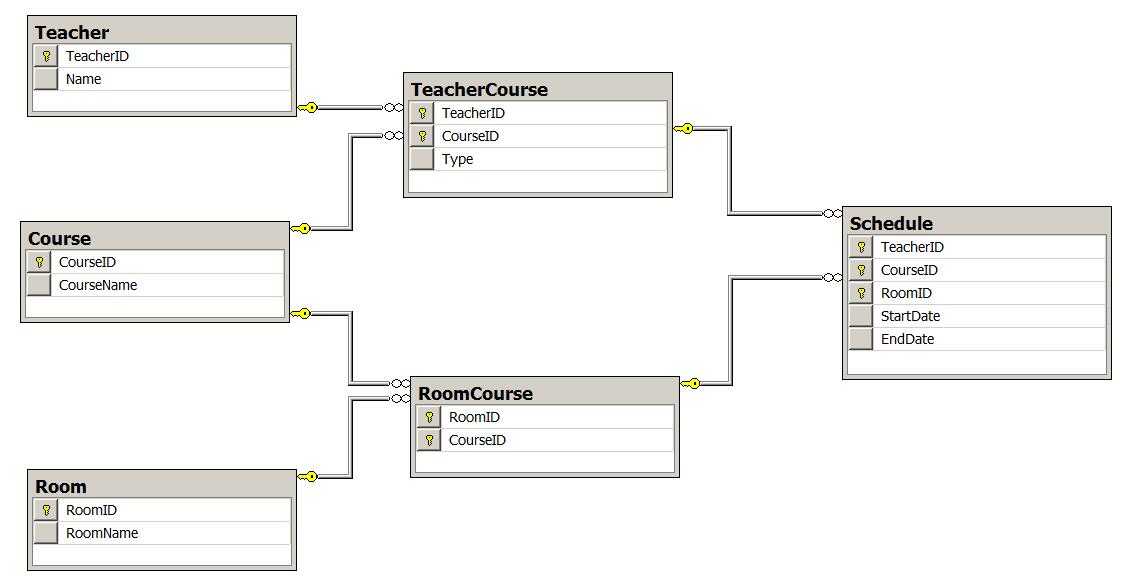
上图并没有改变表,只是改变了表之间的关系。最主要的变化是日程计划表Schedule的外键关联指向的是2张关系表TeacherCourse,RoomCourse。图中发现Schedule的三个外键仍然和原来的一样,如果对此有疑惑,不妨设想在关系表TeacherCourse,RoomCourse上各自设立代理主键key1,key2,此时Schedule的联合主键就是(key1,key2)。不过在这个模型中,代理主键会屏蔽掉很多关键信息,连接时也无必要,因此使用3个键作联合主键,但注意此时的键关系与原模型是不同的。
无损分解是一种分析是否违反较高范式的方法。当你有个大表,可以把其中的某些字段分离出来作为单独的表,经过去重DISTINCT后做驱动表与原来的表进行左外连接 LEFT OUTER JOIN,如果得到的结果没有任何数据丢失,则原来的表可能违反了一些范式,需要检查是否存在异常数据。当进行这样的分析时,表中应该有足够的数据,少量的数据不一定能满足判断。
总结:
1.大多数数据模型已经满足了高范式,明显违反高范式时需要注意。
2.多对多关系、复合键、代理键是容易出现违反高范式的地方。
3.无损分解是一种有效的检测方法。
4.第六范式是将表的关系减少到只存在一个非关键属性,这样会导致表数量膨胀,但可以避免空值列。第六范式的情况很少,未在文中讨论,放在这里只是记录一下。
以上是关于第三范式之上的主要内容,如果未能解决你的问题,请参考以下文章