CDN+Kafka 的初步认识与入门
Posted ronaldo-hd
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CDN+Kafka 的初步认识与入门相关的知识,希望对你有一定的参考价值。
前言
项目中用到了Kafka 这种分布式消息队列来处理日志,本文将对Kafka的基本概念和原理做一些简要阐释
Kafka 的基本概念
官网解释:
Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
消息处理方式有点对点,发布-订阅模式,Kafka就是一种发布-订阅模式。
主要应用场景是:日志收集系统和消息系统。
Kafka主要设计目标如下:
- 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能。
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。
- 同时支持离线数据处理和实时数据处理。
- Scale out:支持在线水平扩展
那么我们就从Kafka的消息队列处理模式开始,逐步了解它的原理和构成。
Kafka 的消息处理模式
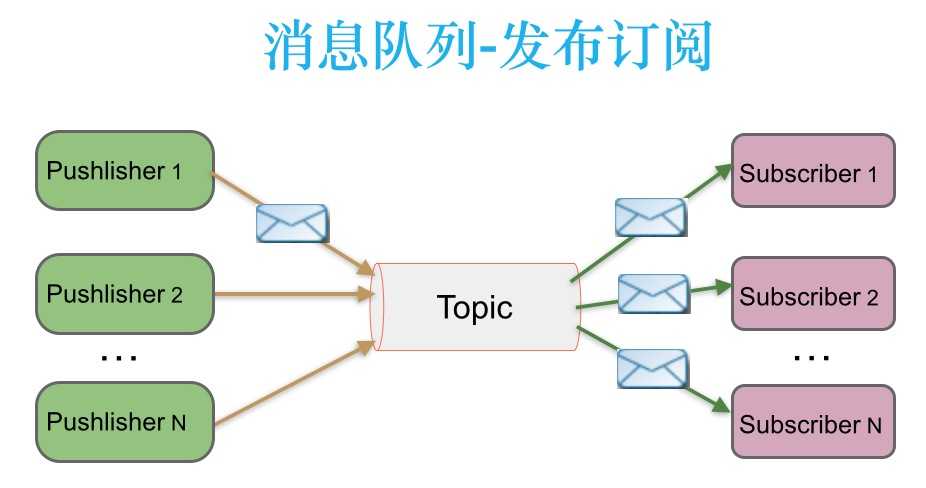
如上图所示,消息被持久化到一个topic中。消费者可以订阅一个或多个topic,消费者可以消费该topic中所有的数据,同一条数据可以被多个消费者消费,数据被消费后不会立马删除。在发布-订阅消息系统中,消息的生产者(producers)称为发布者,消费者(consumers)称为订阅者。
Kafka中的生产者-消费者模型
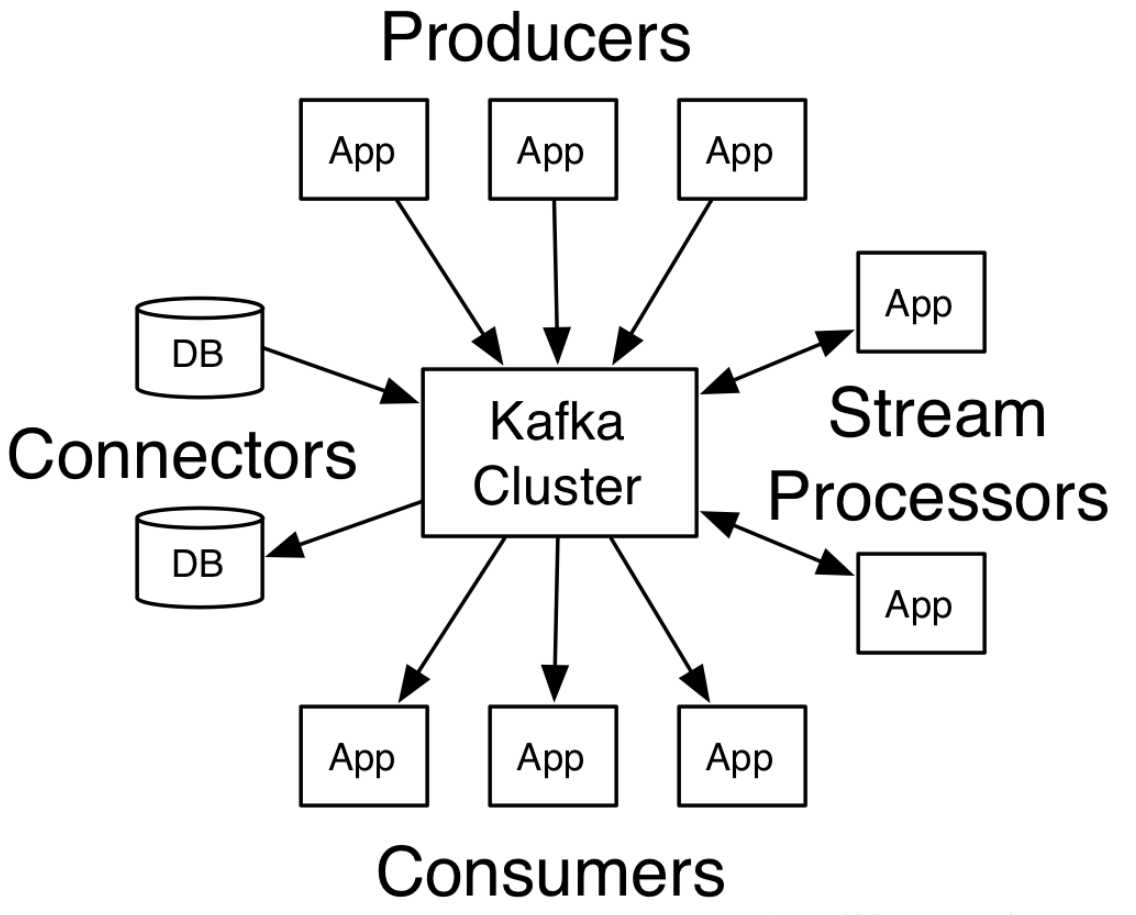
Producers : 主要数据来源是各种日志,mysql-source, Ngnix-source ,Hive,HDFS,各种数据库等等
Consumers: Spark 处理日志格式,内容等等,继续下发到Kylin
Brokers:服务器节点称为broker,指的是下图中间的kafka cluster,负责存储消息,是由多个server组成的集群。
Kafka中的Topic与Partition
上面的生产-消费模型里面提到了kafka里面的基本概念topic和partition ,那么它们是什么呢?
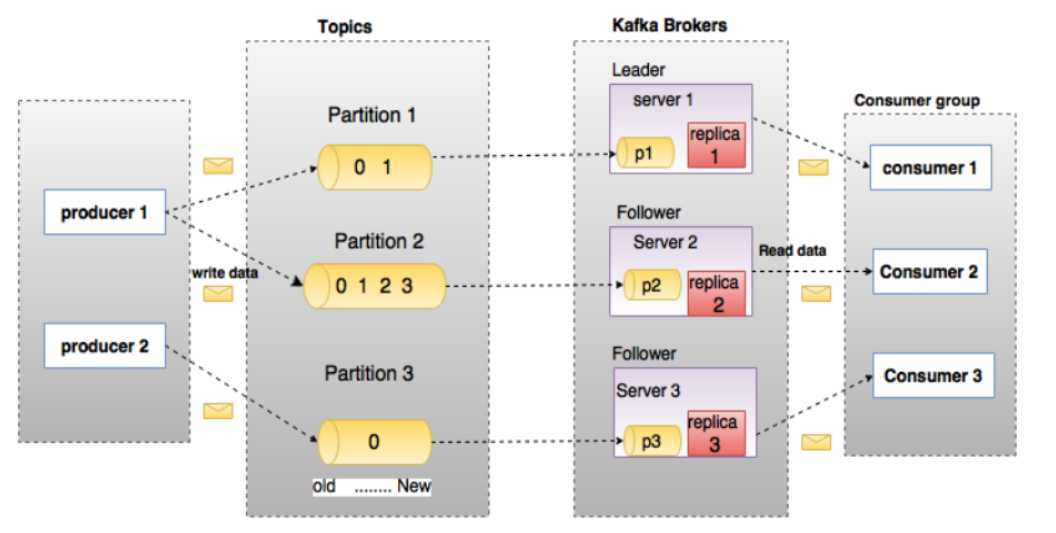
Topic:
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
类似于数据库的表名
Partition:
topic中的数据分割为一个或多个partition。每个topic至少有一个partition。每个partition中的数据使用多个segment文件存储。partition中的数据是有序的,不同partition间的数据丢失了数据的顺序。如果topic有多个partition,消费数据时就不能保证数据的顺序。在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。
Broker:
Kafka 集群包含一个或多个服务器,服务器节点称为broker。
broker存储topic的数据。如果某topic有N个partition,集群有N个broker,那么每个broker存储该topic的一个partition。
如果某topic有N个partition,集群有(N+M)个broker,那么其中有N个broker存储该topic的一个partition,剩下的M个broker不存储该topic的partition数据。
如果某topic有N个partition,集群中broker数目少于N个,那么一个broker存储该topic的一个或多个partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致Kafka集群数据不均衡。
Consumer Group:
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
Consumer:
消费者可以从broker中读取数据。消费者可以消费多个topic中的数据。
Leader:
每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition。
Follower:
Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。如果Leader失效,则从Follower中选举出一个新的Leader。当Follower与Leader挂掉、卡住或者同步太慢,leader会把这个follower从“in sync replicas”(ISR)列表中删除,重新创建一个Follower。
思考与总结:
Kafka 的高可用性原理就是基于:producer--topic--partition--broker(Leader--follower copy)--consumer 这个流程
数据源统一使用topic 进行分类,Kafka尽量将所有的Partition均匀分配到整个集群上。一个典型的部署方式是一个Topic的Partition数量大于Broker的数量。
同时为了提高Kafka的容错能力,也需要将同一个Partition的Replica尽量分散到不同的机器。实际上,如果所有的Replica都在同一个Broker上,那一旦该Broker宕机,该Partition的所有Replica都无法工作,也就达不到HA(High Availability)的效果。同时,如果某个Broker宕机了,需要保证它上面的负载可以被均匀的分配到其它幸存的所有Broker上。
Kafka分配Replica的算法如下:
1.将所有Broker(假设共n个Broker)和待分配的Partition排序
2.将第i个Partition分配到第(i mod n)个Broker上
3.将第i个Partition的第j个Replica分配到第((i + j) mode n)个Broker上
如果要进一步学习Kafka ,建议自己进行搭建,参考: https://www.jianshu.com/p/5297773fcc1b
原理学习参考博客: https://www.cnblogs.com/qingyunzong/p/9004509.html
以上是关于CDN+Kafka 的初步认识与入门的主要内容,如果未能解决你的问题,请参考以下文章