巧用字典树算法,轻松实现日志实时聚类分析
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了巧用字典树算法,轻松实现日志实时聚类分析相关的知识,希望对你有一定的参考价值。
by 田富龙
日志分析对于企业运维来说尤为重要,运维人员如不能实时了解服务器的安全状况,会给企业造成难以估计的损失。对日志进行分析,不仅可以了解到软、硬件设备的运行状况,还可以了解到报错日志的源头、服务器上正在发生的安全事件,判断错误是由应用引发的还是系统本身引起的,从而及时进行补救,以提高企业软、硬件设备的高可用性。
然而,随着服务器数量逐渐增加,日志数据也与日俱增,面对这种境况,利用传统的方式对日志进行分析,显然已经不能满足企业的要求。此时,基于AI技术的日志分析方式就显得尤为重要。
本文提出的实时日志聚类算法,通过提取日志模板方式,能够有效帮助运维人员进行诊断以及定位问题,提高解决问题的效率,从而起到事半功倍的效果。
在这里,我们将介绍实时日志聚类算法中用到的子算法–字典树,它能极大提升日志聚类算法的效率,使实时日志聚类算法能够在极短的时间内,从海量的日志信息中提取出日志模板。
字典树(Trie),又称前缀树,是哈希树(Hash Tree)的一种变种。它的核心思想是以空间换时间,常常用于统计、排序和保存大量的字符串(但不仅限于字符串)。在Trie的每个 Node中保存一个字符以及该节点的所有子节点,并且每个Node中带有一个标志位,用来标识由根节点出发到该节点为止是否能组成一个完整的字符串。
通常规定根节点对应空字符串,由于Trie是一种有序树结构,所以同一个节点的所有子孙节点都有相同的前缀。一般情况下,不是所有的节点都能组成一个完整的字符串,只有叶子节点和部分内部节点所对应的节点才能组成一个完整的字符串。
字典树的一个典型应用是,用于搜索引擎系统中的文本词频统计,它的最大优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串以达到提高效率的目的,查询效率高。
字典树的使用,主要包含插入、查找、删除三方面:
插入
例如,向字典树中插入useless、hope、inter三个字符串,字符串中的每个字符作为一个单独的Node插入到字典树中,每个Node包含两部分:
①根节点开始到该节点为止是否为一个完整的单词
②节点的所有子节点,用map来保存
当字符串插入完成之后,字典树的结构如下图所示,其中红色节点表示该节点是否为一个完整字符串的结尾。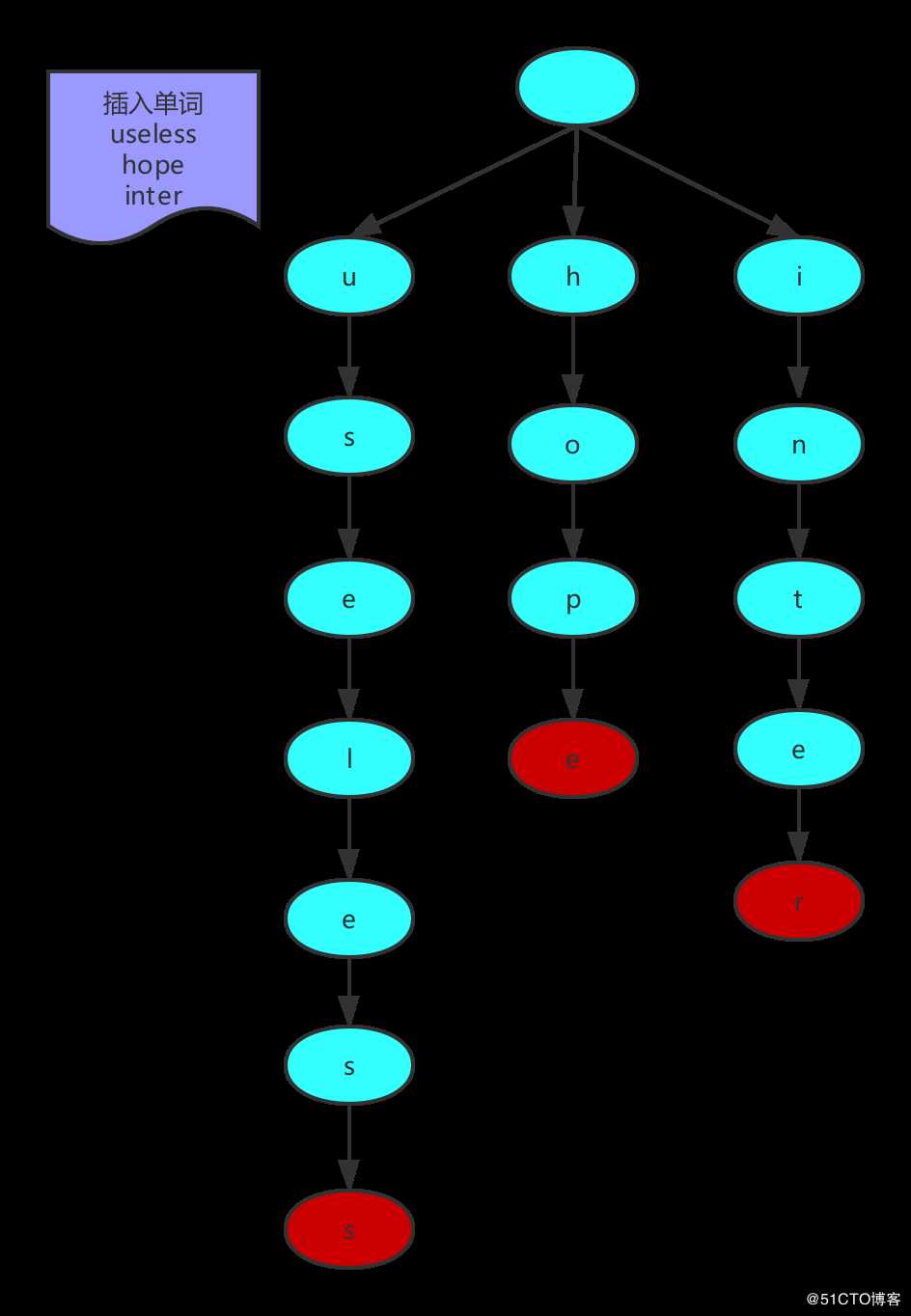
插入useless过程
在此基础上,继续插入单词interact,如下图所示: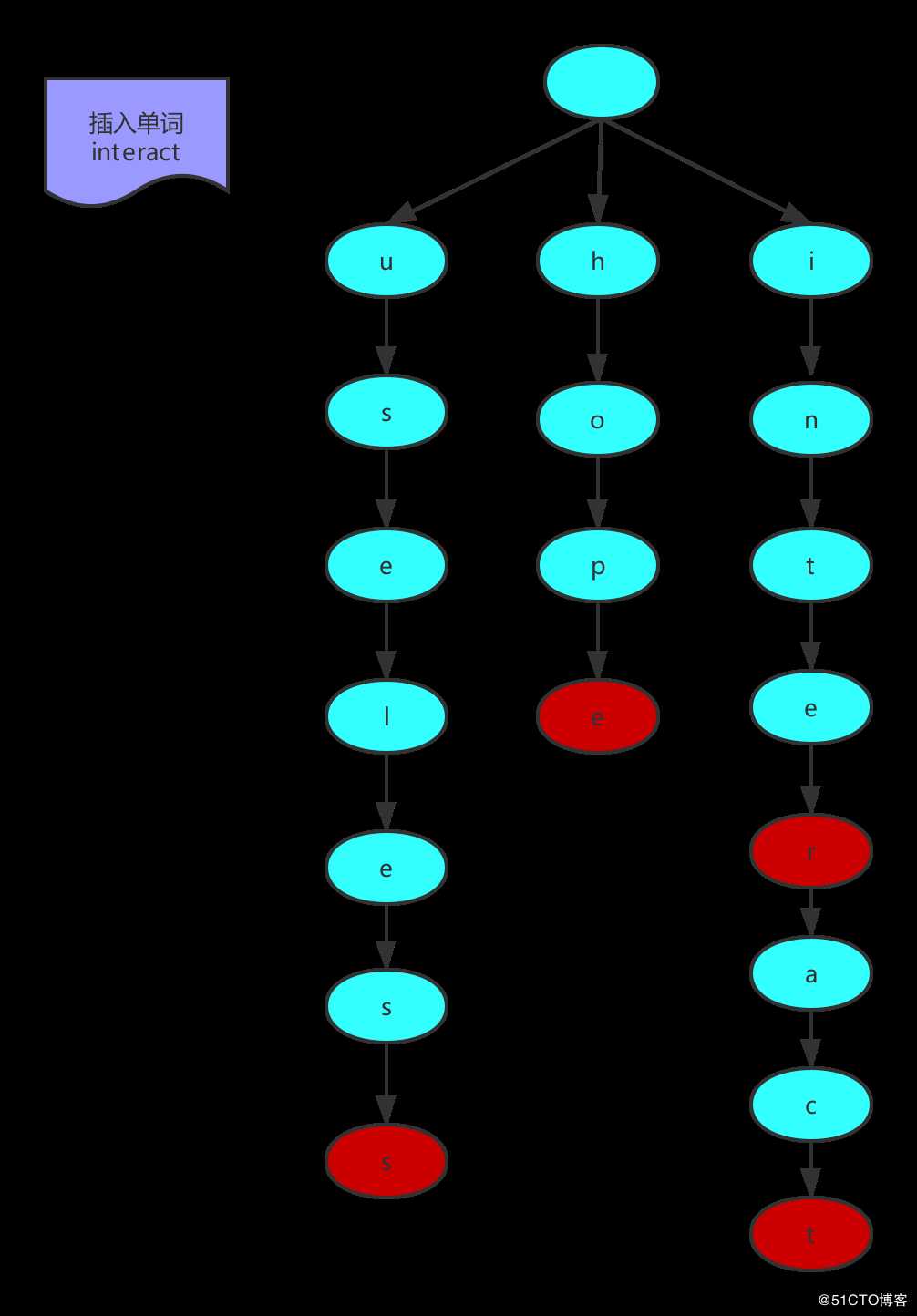
插入单词interact过程
查找
字典树的查找比较简单,遍历查找字符串的字符,如果每个节点都存在,并且待查找字符串的最后一个字符对应的Node的isWord属性为True,则表示该单词存在。如字符串apple存在,app则不存在,因为p的isWord属性为False,不对应一个完整字符串的结束。
删除
字典树的删除操作主要有以下2种情况:
1)待删除字符串是另一个字符串的前缀
如果待删除的单词是另一个单词的前缀,只需要把该单词的最后一个节点的 isWord 属性值改成False即可。比如Trie中存在
inter 和interact 这两个字符串,若要删除
inter 字符串,只需要把字符 r 对应的Node的 isWord 属性改成 False,如下图所示: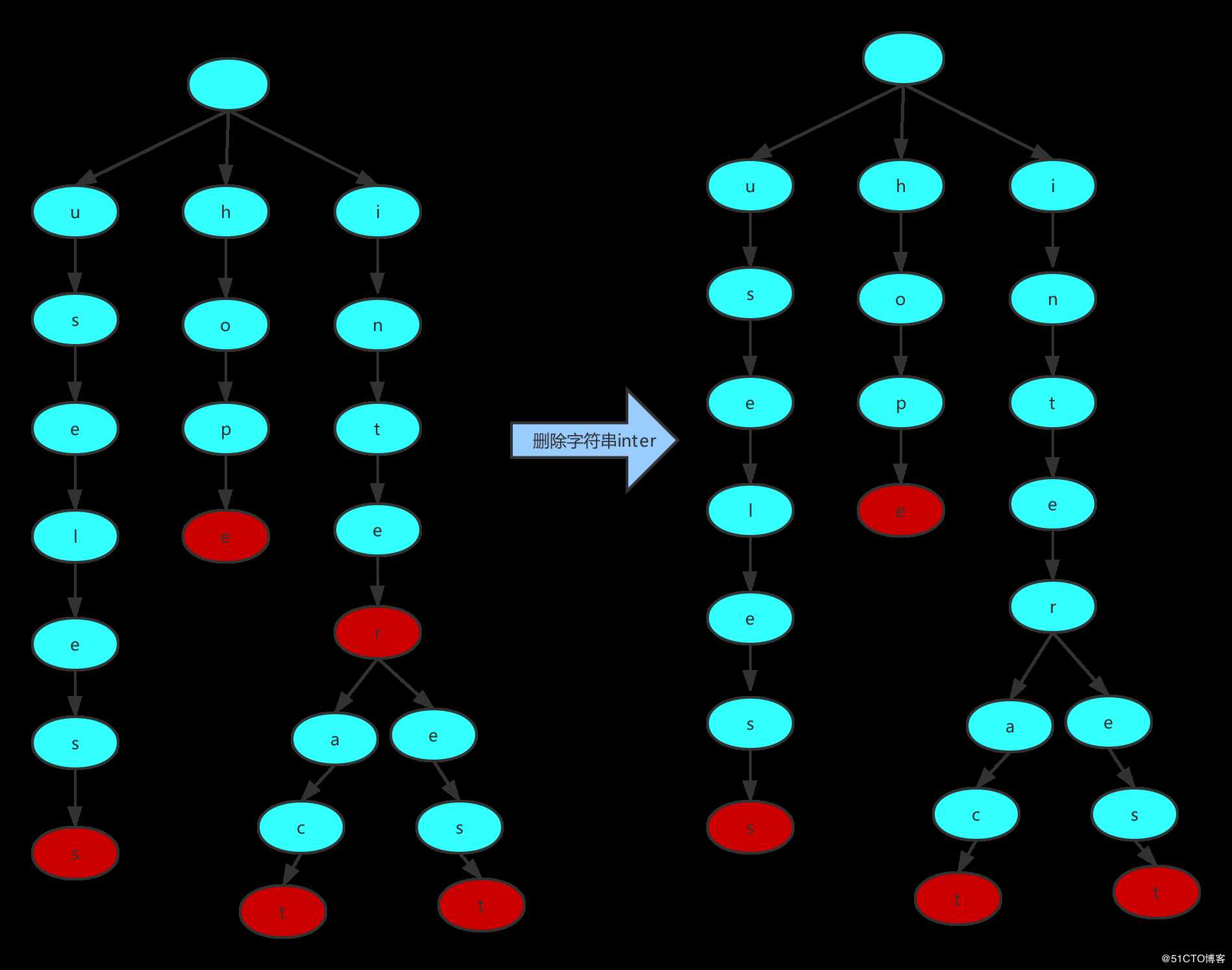
字典树删除inter过程
2)待删除字符串中对应的Node包含多个分支
如果待删除的字符串中字符对应的Node可能有多个分支,需要从该字符串最后一个字符对应的Node开始递归向上进行删除,若节点没有子节点,则将该节点删除,直到遇到节点有多个子节点,递归停止。例如在Trie中删除hope、interest字符串过程,如下图所示: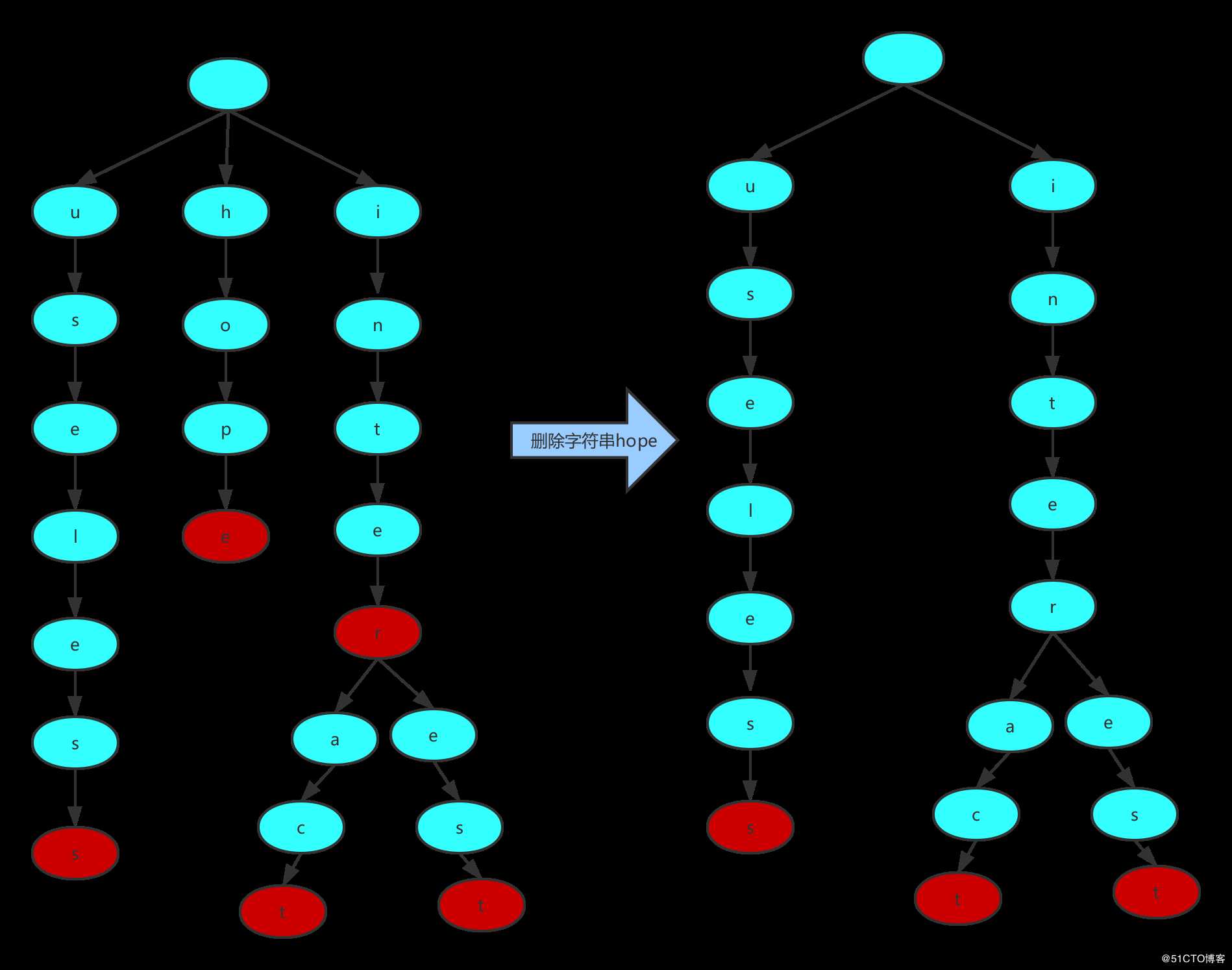
字典树删除hope过程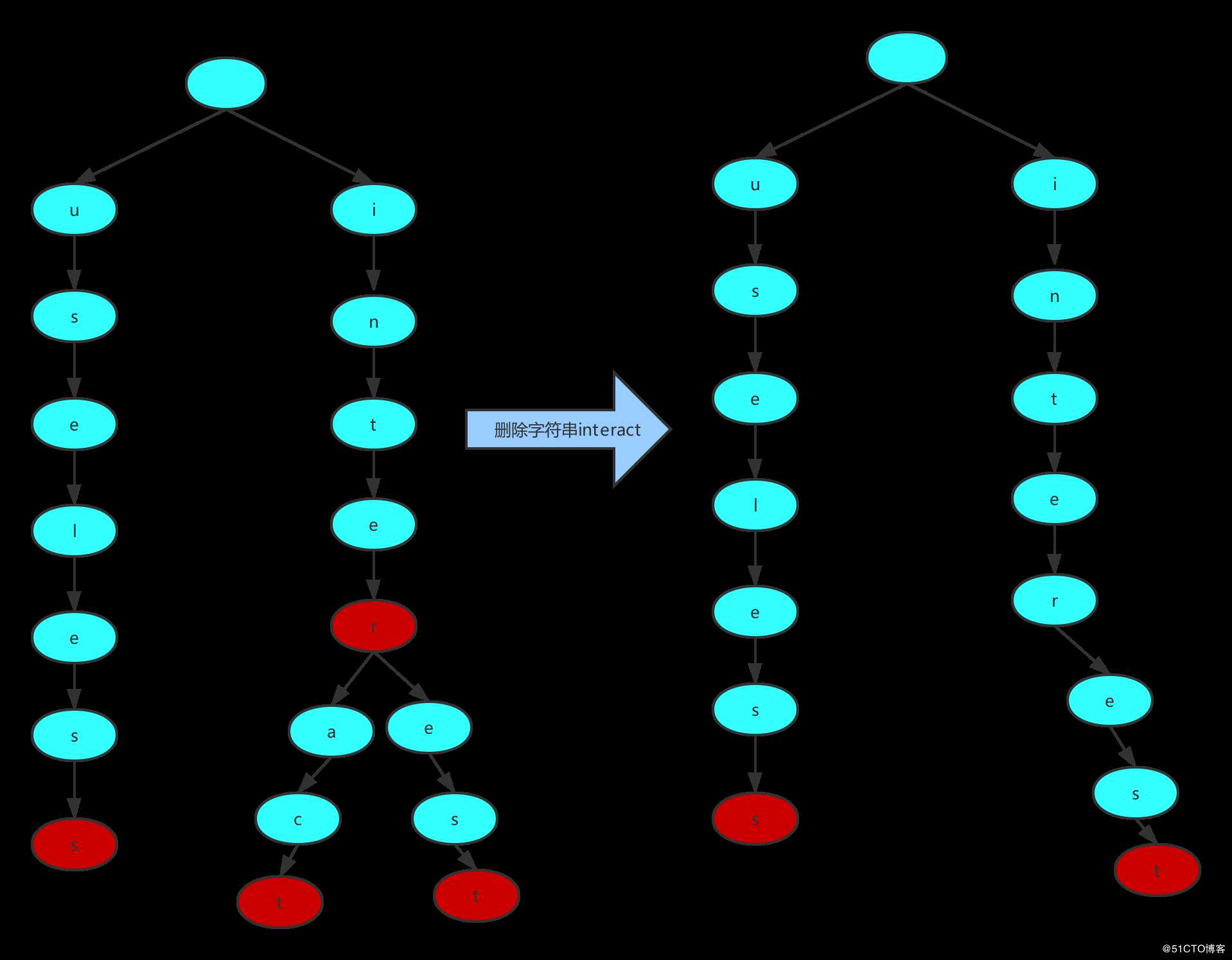
字典树删除interest过程
字典树算法是典型的空间换时间的算法,虽然对空间的消耗很大,但是利用字符串的公共前缀来降低查询时间,查询效率非常高;而且也可以使用压缩字典树(Compressed Trie)来降低对内存的消耗,增加硬件资源的有效利用率。
以上是关于巧用字典树算法,轻松实现日志实时聚类分析的主要内容,如果未能解决你的问题,请参考以下文章
python数据分析与挖掘学习笔记-公司客户价值判断分析与聚类算法