干货 Elasticsearch 知识点整理二
Posted zhuchangwu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货 Elasticsearch 知识点整理二相关的知识,希望对你有一定的参考价值。
目录
?## mapping
root object
mapping json中包含了诸如properties,matadata(_id,_source,_type),settings(analyzer)已经其他的settings
PUT my_index
{
"mappings": {
"my_index": {
"properties": {
"my_field1": {
"type": "integer"
},
"my_field2": {
"type": "float"
},
"my_field2": {
"type": "scaled_float",
"scaling_factor": 100
}
}
}
}
}mate-field 元数据字段
_all
当我们往ES中插入一条document时,它里面包含了多个fireld, 此时,ES会自动的将多个field的值,串联成一个字符串,作为_all属性,同时会建立索引,当用户再次检索却没有指定查询的字段 时,就会在这个_all中进行匹配
_field_names
按照指定的field进行检索,所有含有指定field并且field不为空的document全部会被检索出来
示例:
# Example documents
PUT my_index/_doc/1
{
"title": "This is a document"
}
PUT my_index/_doc/2?refresh=true
{
"title": "This is another document",
"body": "This document has a body"
}
GET my_index/_search
{
"query": {
"terms": {
"_field_names": [ "title" ]
}
}
}禁用:
PUT tweets
{
"mappings": {
"_doc": {
"_field_names": {
"enabled": false
}
}
}
}_id
document的唯一标识信息
_index
标识当前的doc存在于哪个index中,并且ES支持跨域index进行检索,详情见官网 点击进入官网
_routing
路由导航需要的参数,这是它的计算公式shard_num = hash(_routing) % num_primary_shards
可以像下面这样定制路由规则
PUT my_index/_doc/1?routing=user1&refresh=true
{
"title": "This is a document"
}
GET my_index/_doc/1?routing=user1_source
这个元数据中定义的字段,就是将要返回给用户的doc的中字段,比如说一个type = user类型的doc中存在100个字段,但是前端并不是真的需要这100个字段,于是我们使用_source去除一些字段,注意和filter是不一样的,filter不会影响相关性得分
禁用
PUT tweets
{
"mappings": {
"_doc": {
"_source": {
"enabled": false
}
}
}
}_type
这个字段标识doc的类型,是一个逻辑上的划分, field中的value在顶层的lucene建立索引的时候,全部使用的opaque bytes类型,不区分类型的lucene是没有type概念的, 在document中,实际上将type作为一个document的field,什么field呢? _type
ES会通过_type进行type的过滤和筛选,一个index中是存放的多个type实际上是存放在一起的,因此一个index下,不可能存在多个重名的type
_uid
在ES6.0中被弃用
mapping-parameters
首先一点,在ES5中允许创建多个index,这在ES6中继续被沿用,但是在ES7将被废弃,甚至在ES8中将被彻底删除
其次:在一开始我们将Elastic的index必做mysql中的database, 将type比作table,其实这种比喻是错误的,因为在Mysql中不同表之间的列在物理上是没有关系的,各自占有自己的空间,但是在ES中不是这样,可能type=Student中的name和type=Teacher中的name在存储在完全相同的字段中,换句话说,type是在逻辑上的划分,而不是在物理上的划分
copy_to
这个copy_to实际上是在允许我们自定义一个_all字段, 程序员可以将多个字段的值复制到一个字段中,然后再次检索时目标字段就使用我们通过copy_to创建出来的_all新字段中
它解决了一个什么问题呢? 假设我们检索的field的value="John Smith",但是doc中存放名字的field却有两个,分别是firstName和lastName中,就意味着cross field检索,这样一来再经过TF-IDF算法一算,可能结果就不是我们预期的样子,因此使用copy_to 做这件事
示例:
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"first_name": {
"type": "text",
"copy_to": "full_name"
},
"last_name": {
"type": "text",
"copy_to": "full_name"
},
"full_name": {
"type": "text"
}
}
}
}
}
PUT my_index/_doc/1
{
"first_name": "John",
"last_name": "Smith"
}
GET my_index/_search
{
"query": {
"match": {
"full_name": {
"query": "John Smith",
"operator": "and"
}
}
}
}动态mapping(dynamic mapping)
ES使用_type来描述doc字段的类型,原来我们直接往ES中存储数据,并没有指定字段的类型,原因是ES存在类型推断,默认的mapping中定义了每个field对应的数据类型以及如何进行分词
null --> no field add
true flase --> boolean
123 --> long
123.123 --> double
1999-11-11 --> date
"hello world" --> string
Object --> object定制dynamic mapping 策略
- ture: 语法陌生字段就进行dynamic mapping
- false: 遇到陌生字段就忽略
- strict: 遇到默认字段就报错
示例
PUT /my_index/
{
"mappings":{
"dynamic":"strict"
}
}- 禁用ES的日期探测
PUT my_index
{
"mappings": {
"_doc": {
"date_detection": false
}
}
}
PUT my_index/_doc/1
{
"create": "2015/09/02"
}- 定制日期发现规则
PUT my_index
{
"mappings": {
"_doc": {
"dynamic_date_formats": ["MM/dd/yyyy"]
}
}
}
PUT my_index/_doc/1
{
"create_date": "09/25/2015"
}- 定制数字类型的探测规则
PUT my_index
{
"mappings": {
"_doc": {
"numeric_detection": true
}
}
}
PUT my_index/_doc/1
{
"my_float": "1.0",
"my_integer": "1"
}核心的数据类型
各种类型的使用及范围参见官网,点击进入
数字类型
long, integer, short, byte, double, float, half_float, scaled_float示例:
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"number_of_bytes": {
"type": "integer"
},
"time_in_seconds": {
"type": "float"
},
"price": {
"type": "scaled_float",
"scaling_factor": 100
}
}
}
}
}日期类型
date示例:
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"date": {
"type": "date"
}
}
}
}
}
PUT my_index/_doc/1
{ "date": "2015-01-01" } boolean类型
string类型的字符串可以被ES解释成boolean
boolean示例:
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"is_published": {
"type": "boolean"
}
}
}
}
}二进制类型
binary示例
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"name": {
"type": "text"
},
"blob": {
"type": "binary"
}
}
}
}
}
PUT my_index/_doc/1
{
"name": "Some binary blob",
"blob": "U29tZSBiaW5hcnkgYmxvYg=="
}范围
integer_range, float_range, long_range, double_range, date_range示例
PUT range_index
{
"settings": {
"number_of_shards": 2
},
"mappings": {
"_doc": {
"properties": {
"expected_attendees": {
"type": "integer_range"
},
"time_frame": {
"type": "date_range",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
}
PUT range_index/_doc/1?refresh
{
"expected_attendees" : {
"gte" : 10,
"lte" : 20
},
"time_frame" : {
"gte" : "2015-10-31 12:00:00",
"lte" : "2015-11-01"
}
}复杂数据类型
对象类型,嵌套对象类型示例:
PUT my_index/_doc/1
{
"region": "US",
"manager": {
"age": 30,
"name": {
"first": "John",
"last": "Smith"
}
}
}在ES内部这些值被转换成这种样式
{
"region": "US",
"manager.age": 30,
"manager.name.first": "John",
"manager.name.last": "Smith"
}Geo-type
ES支持地理上的定位点
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}
}
PUT my_index/_doc/1
{
"text": "Geo-point as an object",
"location": {
"lat": 41.12,
"lon": -71.34
}
}
PUT my_index/_doc/4
{
"text": "Geo-point as an array",
"location": [ -71.34, 41.12 ]
}
Arrays 和 Multi-field
? 更多内容参见官网**,点击进入
查看某个index下的某个type的mapping
GET /index/_mapping/type定制type field
可以给现存的type添加field,但是不能修改,否则就会报错
PUT twitter
{
"mappings": {
"user": {
"properties": {
"name": {
"type": "text" , # 会被全部检索
"analyzer":"english" # 指定当前field使用 english分词器
},
"user_name": { "type": "keyword" },
"email": { "type": "keyword" }
}
},
"tweet": {
"properties": {
"content": { "type": "text" },
"user_name": { "type": "keyword" },
"tweeted_at": { "type": "date" },
"tweeted_at": {
"type": "date"
"index": "not_analyzeed" # 设置为当前field tweeted_at不能被分词
}
}
}
}
}mapping复杂数据类型再底层的存储格式
Object类型
{
"address":{
"province":"shandong",
"city":"dezhou"
},
"name":"zhangsan",
"age":"12"
}转换
{
"name" : [zhangsan],
"name" : [12],
"address.province" : [shandong],
"address.city" : [dezhou]
}Object数组类型
{
"address":[
{"age":"12","name":"张三"},
{"age":"12","name":"张三"},
{"age":"12","name":"张三"}
]
}转换
{
"address.age" : [12,12,12],
"address.name" : [张三,张三,张三]
}精确匹配与全文检索
精确匹配称为 : exact value
搜索时,输入的value必须和目标完全一致才算作命中
"query": { "match_phrase": { "address": "mill lane" } }, # 短语检索 address完全匹配 milllane才算命中,返回
全文检索 full text
全文检索时存在各种优化处理如下:
- 缩写: cn == china
- 格式转换 liked == like == likes
- 大小写 Tom == tom
- 同义词 like == love
示例
GET /_search
{
"query": {
"match" : {
"message" : "this is a test"
}
}
}倒排索引 & 正排索引
倒排索引 inverted index
倒排索引指向所有document分词的field
假设我们存在这样两句话
doc1 : hello world you and me
doc2 : hi world how are you建立倒排索引就是这样
| - | doc1 | doc2 |
|---|---|---|
| hello | * | - |
| world | * | * |
| you | * | * |
| and | * | - |
| me | * | - |
| hi | - | * |
| how | - | * |
| are | - | * |
这时,我们拿着hello world you 来检索,经过分词后去上面索引中检索,doc12都会被检索出,但是doc1命中了更多的词,因此doc1得分会更高
正排索引 doc value
doc value实际上指向所有不分词的document的field
ES中,进行搜索动作时需要借助倒排索引,但是在排序,聚合,过滤时,需要借助正排索引,所谓正排索引就是其doc value在建立正排索引时一遍建立正排索引一遍建立倒排索引, doc value会被保存在磁盘上,如果内存充足也会将其保存在内存中
正排索引大概长这样
| document | name | age |
|---|---|---|
| doc1 | 张三 | 12 |
| doc2 | 李四 | 34 |
正排索引也会写入磁盘文件 中,然后os cache会对其进行缓存,以提成访问doc value的速度,当OS Cache中内存大小不够存放整个正排索引时,doc value中的值会被写入到磁盘中
关于性能方面的问题: ES官方建议,大量使用OS
Cache来进行缓存和提升性能,不建议使用jvm内存来进行缓存数据,那样会导致一定的gc开销,甚至可能导致oom问题,所以官方的建议是,给JVM更小的内存,给OS Cache更大的内存, 假如我们的机器64g,只需要给JVM 16g即可
doc value存储压缩 -- column压缩
为了减少doc value占用内存空间的大小,采用column对其进行压缩, 比如我们存在三个doc, 如下
doc 1: 550
doc 2: 550
doc 3: 500合并相同值,doc1,doc2的值相同都是550,保存一个550标识即可
- 所有值都相同的话,直接保留单位
- 少于256的值,使用table encoding的模式进行压缩
- 大于256的值,检查他们是否有公约数,有的话就除以最大公约数,并保留最大公约数
如: doc1: 24 doc2 :36
除以最大公约数 6
doc1: 4 doc2 : 6 保存下最大公约数6- 没有最大公约数就使用 offset结合压缩方式
禁用doc value
假设,我们不使用聚合等操作,为了节省空间,在创建mappings时,可以选择禁用doc value
PUT /index
{
"mappings":{
"my_type":{
"properties":{
"my_field":{
"type":"text",
"doc_values":false # 禁用doc value
}
}
}
}
}相关性评分与 TF-IDF算法
relevance score 相关度评分算法, 直白说就是算出一个索引中的文本和搜索文本之间的相似程度
Elasticsearch使用的是 TF-IDF算法 (term-frequency / inverser document frequency)
- term-frequency: 表示当前搜索的文本中的词条在field文本中出现了多少次,出现的次数越多越相关
- inverse document frequency : 表示搜索文本中的各个词条在整个index中所有的document中出现的次数,出现的次数越多越不相关
- field-length: field长度越长,越不相关
向量空间模式
ES会根据用户输入的词条在所有document中的评分情况计算出一个空间向量模型 vector model, 他是空间向量中的一个点
然后会针对所有的doc都计算出一个vector model出来, 将这个
如果存在多个term,那么就是一个多维空间向量之间的运算,但是我们假设是二维的,就像下面这张图
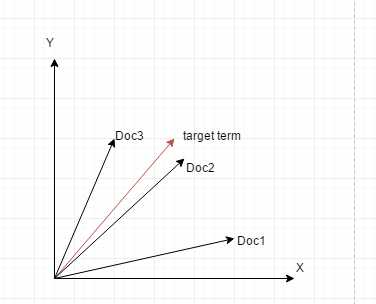
一目了然,Doc2和目标词条之间的弧度小,于是认为他们最相似,它的得分也就越高
分词器
什么是分词器?
我们使用分词将将一段话拆分成一个一个的单词,甚至进一步对分出来的单词进行词性的转换,师太的转换,单复数的转换的操作, 为什么使用分词器? 就是为了提高检索时的召回率,让更多的doc被检索到
分词器的组成
character filter:
在一段文本在分词前先进行预处理,比如过滤html标签, 将特殊符号转换成123..这种阿拉伯数字等特殊符号的转换
tokenizer
进行分词,拆解句子,记录词条的位置(在当前doc中占第几个位置term position)及顺序
token filter
进行同义词的转换,去除同义词,单复数的转换等等
ES内置的分词器
- standard analyzer(默认)
- simple analyzer
- whitespace
- language analyzer(特定语言的分词器,English)
知识补充
- ES隐藏了复杂分布式机制,如分片,副本,负载均衡
- 增加或者减少节点时,ES会自动的进行rebalance,使数据平均分散在不同的节点中
- master节点: master节点用来管理集群中的元数据,默认会在集群中选出一个节点当成master节点,而且master节点并不会承载全部请求,所以不存在单点瓶颈
- 元数据: 创建或者删除索引,增加或者删除节点
- 扩容方案: 更推荐横向扩容,这也符合ES分片的特定,购置大量的便宜的机器让他们成为replica shard加入集群中
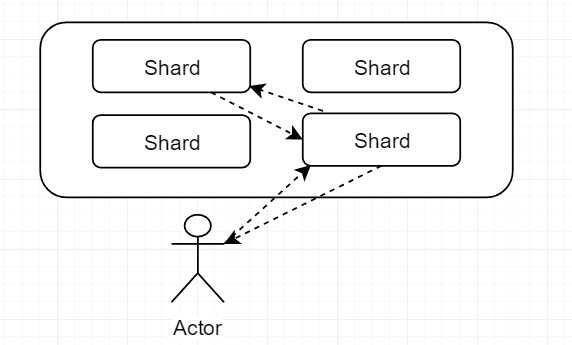
每一个分片地位相同,都能接受请求,处理请求,当当用户的一个请求发送到某一个shard中后,这个shard会自动就请求路由到真正存储数据的shard上去,但是最终总是由接受请求的节点响应请求
图解: master的选举,容错,以及数据的恢复
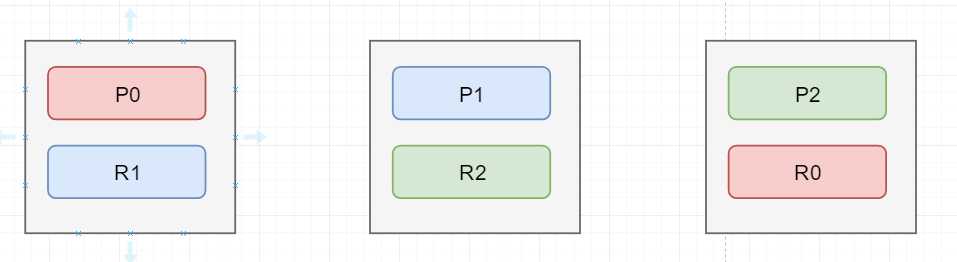
如上图为初始状态图
假如,图上的第一个节点是master节点,并且它挂掉,在挂掉的一瞬间,整个cluster的status=red,表示存在数据丢失了集群不可用
下面要做的第一步就是完成master的选举,自动在剩下的节点中选出一个节点当成master节点, 第二步选出master节点后,这个新的master节点会将Po在第三个节点中存在一个replica shard提升为primary shard,此时cluster 的 status = yellow,表示集群中的数据是可以被访问的但是存在部分replica shard不可用,第三步,重新启动因为故障宕机的node,并且将右边两个节点中的数据拷贝到第一个节点中,进行数据的恢复
并发冲突问题
ES的实现
ES内部的多线程异步并发修改时,是通过_version版本号进行并发控制的,每次创建一个document,它的_version内部版本号都是1,以后对这个doc的修改,删除都会使这个版本号增1
ES的内部需在Primary shard 和 replica shard之间同步数据,这就意味着多个修改请求其实是乱序的不一定按照先后顺序执行
相关语法:
PUT /index/type/2?version=1{
"name":"XXX"
}上面的命令中URL中的存在?version=1,此时,如果存在其他客户端将id=2的这条记录修改过,导致id=2的版本号不等于1了,那么这条PUT语句将会失败并有相应的错误提示
基于external的版本号控制,ES提供了一个Futrue,也就是说用户可以使用自己维护的版本号进行并发访问控制,比如:
PUT /index/type/2?version=1&version_type=external假设当前ES中的版本号是1, 那么只有当用户提供的版本号大于1时,PUT才会成功
路由原理
- 什么是数据路由?
一个index被分成了多个shard,文档被随机的存在某一个分片上,客户端一个请求打向index中的一个分片,但是请求的doc可能不存在于这个分片上,接受请求的shard会将请求路由到真正存储数据的shard上,这个过程叫做数据路由
其中接受到客户端请求的节点称为coordinate node,协调节点,比如现在是客户端往服务端修改一条消息,接受A接受到请求了,那么A就是 coordnate node协调节点,数据存储在B primary shard 上,那么协调节点就会将请求路由到B primary shard中,B处理完成后再向 B replica shard同步数据,数据同步完成后,B primary shard响应 coordinate node, 最后协调节点响应客户端结果
- 路由算法,揭开primary_shard数量不可变的面纱
shard = hash(routing) % number_of_primary_shards其实这个公式并不复杂,可以将上面的routing当成doc的id,无论是用户执行的还是自动生成的,反正肯定是唯一,既然是唯一的经过每次hash得到的结果也是一样的, 这样一个唯一的数对主分片的数进行取余数,得到的结果就会在0-最大分片数之间
可以手动指定routing value的值,比如PUT /index/type/id?routing=user_id ,在保证这类doc一定被路由到指定的shard上,而且后续进行应用级负载均衡时会批量提升读取的性能
写一致性及原理
我们在发送任何一个增删改查时,都可以带上一个 consistency 参数,指明我们想要的写一致性是什么,如下
PUT /index/type/id?consistency=quorum有哪些可选参数呢?
- one: 当我们进行写操作时,只要存在一个primary_shard=active 就能写入成功
- all: cluster中全部shard都为active时,可以写入成功
- quorum: 意味:法定的,也是ES的默认值, 要求大部分的replica_shard存活时系统才可用
quorum数量的计算公式: int((primary+number_of_replicas)/2)+1, 算一算,假如我们的集群中存在三个node,replica=1,那么cluster中就存在3+3*1=6个shard
int((3+1)/2)+1 = 3
结果显示,我们只有当quorum=3,即replica_shard=3时,集群才是可用的,但是当我们的单机部署时,由于ES不允许同一个server的primary_shard和replica_shard共存,也就是说我们的replica数目为0,为什么ES依然可以用呢? 这是ES提供了一种特殊的处理场景,即当number_of_replicas>1时才会生效
quorum不全时,集群进入wait()状态, 默认1分钟,,在等待期间,期望活跃的shard的数量可以增加,到最后都没有满足这个数量的话就会timeout
我们在写入时也可以使用timeout参数, 比如: PUT /index/type/id?timeout=30通过自己设置超时时间来缩短超时时间
运行流程
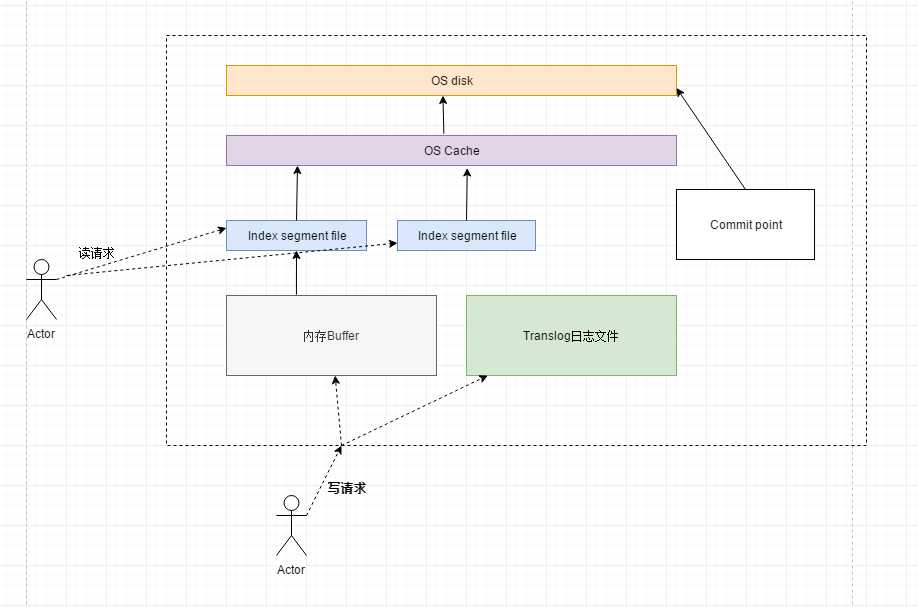
ES的底层运行流程探秘:
用户的写请求将doc写入内存缓冲区,写的动作被记录在translog日志文件中,每隔一秒中内存中的数据就会被刷新到index segment file中,index segment file中的数据随机被刷新到os cache中,然后index segement file处理打开状态,对外提供检索服务,ES会重复这个过程,每次重复这个过程时,都会先清空内存buffer,处理打开状态的 index segment file可以对外提供检索
直到translog日志文件体积太大了,就会进一步触发flush操作,这个flush操作会将buffer中全部数据刷新进新的segment file中,将index segment file刷新进os cache, 写一个commit point 到磁盘上,标注有哪些index segment,并将OS cache中的数据刷新到OS Disk中,完成数据的持久化
上面的flush动作,默认每隔30分钟执行一次,或者当translog文件体积过大时也会自动flush
数据恢复时,是基于translog文件和commit point两者判断,究竟哪些数据在日志中存在记录,却没有被持久化到OSDisk中,重新执行日志中的逻辑,等待下一次的flush完成持久化
merge segment file
看上面的图中,为了实现近实时的搜索,每1秒钟就会产生一个segment文件,文件数目会特别多,而恰巧对外提供搜索的就是这些segment文件,因此ES会在后台进行segement 文件的合并,在合并的时候,被标记deleted的docment会会被彻底的物理删除
每次merge的操作流程
- 选择大小相似的segment文件,merge成一个大的segement文件
- 将新的segment文件flush到磁盘上去
- 写一个新的commit point,包括了新的segement,然后排除那些就的segment
- 将新的segment打开提供搜索
- 将旧的segement删除
以上是关于干货 Elasticsearch 知识点整理二的主要内容,如果未能解决你的问题,请参考以下文章
Elasticsearch必知必会的干货知识二:ES索引操作技巧