03_数据的特征预处理
Posted hp-lake
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了03_数据的特征预处理相关的知识,希望对你有一定的参考价值。
03 数据特征预处理
特征的预处理
特征的预处理
- 定义:通过特定的统计方法(数学方法),将数据转换成算法要求的数据。
- 数值型数据:标准缩放
- 归一化
- 标准化
- 类别性数据: one-hot编码
- 时间类型: 时间的切分
归一化
- 定义: 通过对原始数据的变化把数据映射到 [0,1] 之间
- 优点:多个特征时,某一个特征对最终结果不会造成更大的影响 (同一个维度)
- 缺点:容易受到极大值和极小值的影响
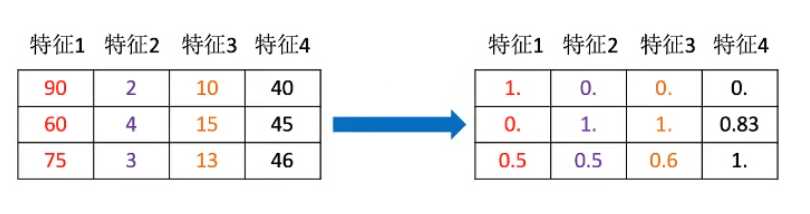

标准化
- 定义: 将原始数据变换为均值为0, 标准差为1的范围内
- 如果出现异常点,由于具有一定的数据量,少量的异常点对于平均值的影响并不大,从而方差改变较小
- 在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景。

from sklearn.preprocessing import MinMaxScaler, StandardScaler
def mm():
"""
归一化预处理
:return:None
"""
mm = MinMaxScaler()
data = mm.fit_transform([[90, 2, 10, 40], [60, 4, 15, 45], [75, 3, 13, 46]])
print(data)
def stand():
"""
标准化预处理
:return: None
"""
st = StandardScaler()
data = st.fit_transform([[90, 2, 10, 40], [60, 4, 15, 45], [75, 3, 13, 46]])
print(data)
if __name__ == '__main__':
mm()
print('*' * 50)
stand()缺失值的处理
- 缺失值的处理方法
- 删除: 如果每列或者行数缺失值达到一定的比例,建议放弃整行或者整列
- 插补: 通过缺失值每行或者每列(特征值)的平均值、中位数来填补
- sklearn缺失值API: sklearn.preprocessing.Imputer # impute 归咎于
import numpy as np
from sklearn.preprocessing import Imputer
def im():
"""
缺失值处理
:return: None
"""
# NaN, nan都可以
im = Imputer(missing_values='NaN', strategy='mean', axis=0) # axis=0 列,可以记忆0是竖着圈
data = im.fit_transform([[1, 2], [np.nan, 3], [7, 6]])
print(data)
return None
if __name__ == '__main__':
im()- 关于np.nan(np.NaN)
- numpy的数组中可以使用np.nan来代替缺失值,属于float类型
- 如果是文件中的一些缺失值,可以替换成nan,通过np.array转化成float型的数组即可
以上是关于03_数据的特征预处理的主要内容,如果未能解决你的问题,请参考以下文章