Flink读写Kafka
Posted zackstang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink读写Kafka相关的知识,希望对你有一定的参考价值。
Flink 读写Kafka
在Flink中,我们分别用Source Connectors代表连接数据源的连接器,用Sink Connector代表连接数据输出的连接器。下面我们介绍一下Flink中用于读写kafka的source & sink connector。
Apache Kafka Source Connectors
Apache Kafka 是一个分布式的流平台,其核心是一个分布式的发布-订阅消息系统,被广泛用于消费与分发事件流。
Kafka将事件流组织成为topics。一个topic是一个事件日志(event-log),保证读入事件的顺序为事件写入的顺序。为了实现可扩展,topic可以被分为多个partition,并分布在集群中的各个节点中。但是在topic分区后,由于consumers可能会从多个partition读入数据,所以此时只能在partition级别保证事件的顺序。在Kafka中,当前读的位置称为偏移量(offset)。
可以通过sbt或maven构建Flink Kafka connector 的依赖,下面是一个sbt的例子:
// https://mvnrepository.com/artifact/org.apache.flink/flink-connector-kafka
libraryDependencies += "org.apache.flink" %% "flink-connector-kafka" % "1.8.1"
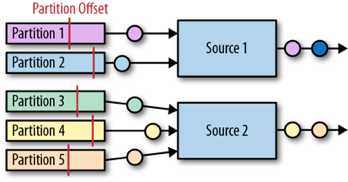
Flink Kafka connector以并行的方式读入事件流,每个并行的source task 都可以从一个或多个partition读入数据。Task对于每个它当前正在读的partition,都会追踪当前的offset,并将这些offset数据存储到它的检查点数据中。当发生故障,进行恢复时,offset被取出并重置,使得数据可以在上次检查点时的offset继续读数据。Flink Kafka connector并不依赖于Kafka 本身的offset-tracking 机制(也就是consumer groups机制)。下图显示的是partitions被分配给不同的source task:
下面是一个创建一个 kafka source 的例子:
val properties = new Properties()
properties.setProperty("bootstrap.servers", "localhost:9092")
properties.setProperty("group.id", "test")
val stream: DataStream[String] = env.addSource(
new FlinkKafkaConsumer[String](
"topic",
new SimpleStringSchema(),
properties))
这个FlinkKafkaConsumer 构造函数有3 个参数,第一个参数定义的是读入的目标topic名。这里可以是单个topic、一组topics、亦或是一个正则表达式匹配所有符合规则的topics。当从多个topics读入事件时,Kafka connectors会将所有topics的所有partitions 一视同仁,并将这些事件合并到一个单个流中。
第二个参数是一个DeserializationSchema 或KeyedDeserializationSchema。Kafka中的消息是以纯字节消息存储,所以需要被反序列化为Java或Scala 对象。在上例中用到的SimpleStringSchema 是一个内置的DeserializationSchema,可以将字节数字反序列化为一个String。Flink也提供了对Apache Avro以及基于text的JSON编码的实现。我们也可以通过实现DeserializationSchema 与KeyedDeserializationSchema 这两个公开的接口,用于实现自定义的反序列化逻辑。
第三个参数是一个Properties对象,用于配置Kafka的客户端。此对象至少要包含两个条目,"bootstrap.servers" 与"group.id"。
为了提取事件-时间的时间戳,并生成水印,我们可以为Kafka consumer提供AssignerWithPeriodicWatermark 或AssignerWithPunctuatedWatermark ,具体可以通过调用FlinkKafkaConsumer.assignTimestampsAndWatermark()实现。这个assigner会被应用到每个partition,并影响每个partition的message序列保证。Source 实例会根据水印的propagation protocol 将partition的水印进行merge。
需要注意的是:如果一个partition变为inactive状态,则source 实例的水印机制便无法向前推进。并最终会因为一个inactive的partition导致整个application停止运行,因为application的水印无法向前推进。
在Kafka 0.10.0版本后,提供了消息时间戳的支持。如果application是以event-time模式运行,则consumer会自动从Kakfa消息中获取时间戳,并以此时间戳为event-time时间戳。在这种情况下,我们需要生成水印并应用AssignerWithPeriodicWatermark或AssignerWithPunctuatedWatermark,它们会向前推进前面被分配的Kafka时间戳。
还有一些需要注意的配置选项,在 consumer 开始读Kafka 消息时,我们可以配置它的读起始位置,有以下几种:
- Kafka为consumer group(由group.id配置指定)存储的最近的读取位置。这个也是默认的行为,指定方式为:FlinkKafkaConsumer.setStartFromGroupOffsets()
- 每个partition最开始的offset:FlinkKafkaConsumer.setStartFromEarliest()
- 每个partition最近的offset:FlinkKafkaConsumer.setStartFromLatest()
- 给定时间戳之后的records(需Kafka 版本高于0.10.x):FlinkKafkaConsumer.setStartFromTimestamp(long)
- 为所有partition指定读取位置,传入参数为Map对象:FlinkKafkaConsumer.setStartFromSpecificOffsets(Map)
需要注意的是:这些配置仅影响第一次读取的位置。在application出现故障后恢复时,使用的是检查点的offset(或是在以savepoint启动时,使用的是savepoint中的offset)。
Flink Kafka consumer可以被配置为自动发现新加入的topics(通过正则表达式)或新加入的partition的模式。默认此功能是禁止的,不过可以通过指定flink.partition-discovery.interval-millis参数(在Properties对象中指定)开启,只需要将此参数指定为非负整数即可。
Apache Kafka Sink Connector
Flink提供为Kafka 0.8 版本后所有 Kafka版本的sink connectors。同样,根据环境中Flink的版本,我们需要加上相关依赖(具体可参考上文)。
下面是一个Kafka sink的例子:
val stream: DataStream[String] = ... val myProducer = new FlinkKafkaProducer[String]( "localhost:9092", // broker list "topic", // target topic new SimpleStringSchema) // serialization schema stream.addSink(myProducer)
这个FlinkKafkaProducer构造函数有3个参数。第一个参数是一个以逗号分隔的Kafka broker地址。第二个参数是目标topic名,最后是一个SerializationSchema,用于将输入数据(此例子中String)转换为一个字节数组。此处的DeserializationSchema与Kakfa source connector中的DeserializationSchema相对应。
FlinkKafkaProducer提供了多种构造函数的选项:
- 与Kafka source connector 类似,可以传递一个Properties对象,用于为客户端提供自定义的配置。在使用Properties时,broker list需要以"bootstrap.servers"属性的方式写在Properties中。
- 也可以指定一个FlinkKafkaPartitioner,用于控制records与Kafka partition中的映射。
- 除了使用SerializationSchema将记录转换为字节数组,我们也可以实现一个KeyedSerializationSchema接口,用于将一条记录转换为两个字节数组——一个是key,另一个是value。也可以通过它实现更多的功能,例如将目标topic重写为多个topics。
为KAFKA SINK提供AT-LEAST-ONCE 保证
Flink Kafka sink可提供的一致性保障由它的配置决定。Kafka sink 在满足以下条件时,可以提供at-least-once 保障:
- Flink的检查点功能已开启,并且application的所有source是可重置的(也就是reading offset可重置)
- 如果写未成功,则sink connector抛出一个异常,导致application失败并recover。这个是默认的行为。在Kafka 客户端,我们也可以配置为:在写入失败时,进行重试,重试参数可由retries属性指定(默认为0,设置为大于0即可),在达到重试次数后,再申明写入失败。我们也可以配置sink仅将写入失败的操作记录到日志,而不抛出任何异常,对sink对象调用setLogFailuresOnly(true)即可。需要注意的是这个会导致application无任何输出一致性保证。
- sink connector在完成它的检查点之前,需要等待Kafka ack 所有in-flight records。这个也是默认的行为。
为KAFKA SINK提供EXACTLY-ONCE一致性保证
Kafka 0.11版本之后引入了对事务写(transactional writes)的支持。得益于此功能,Flink的Kafka sink也可以提供exactly-once的一致性保证(在正确配置了sink与Kafka的前提下)。同样,Flink application必须启用检查点的功能,并且source为可重置的(也就是reading offset可重置)。
FlinkKafkaProducer提供了一个构造方法,可以传入一个Semantic(语义)参数,用于控制(由sink提供的)一致性保证。可选的参数值有:
- Semantic.NONE:提供无保证——records可能会丢失或是被写入多次
- Semantic.AT_LEAST_ONCE:可以保证没有写丢失,但是可能会有重复的写入。这个是默认设置。
- Semantic.EXACTLY_ONCE:基于Kafka的事务(transactions),保证每个record exactly-once 写入
在使用Flink application结合Kafka sink 的exactly-once模式时,有几点需要考虑的地方,这几点也有助于理解Kafka如何处理事务。简单地说,Kafka的事务工作流程如下:
- 开启一个事务,将所有属于此事务内的消息(写入)追加到partition的末尾,并标注这些消息为uncommitted
- 在一个事务committed后,这些标记变为committed
- 从Kafka topic消费消息的consumer,可以配置为一个isolation级别(通过isolation.level属性进行配置),申明是否它可以读uncommitted消息,可读参数为read_uncommitted,也是默认配置。不可读的参数为read_committed。如果consumer被配置为read_committed,则它会在遇到一个uncommitted消息后,停止从一个partition消费数据,并在消息变为committed后,恢复消费数据。
所以,一个正在进行的事务可以阻止consumers从partition读未committed的数据,并引入相当的延迟。Kafka防止高延时所做的一个改进是:在超过timeout interval时间后,会直接拒绝并关闭事务。此超时时间由transaction.timeout.ms属性设置。
在Flink Kafka sink中,这个超时时间非常重要,因为事务超时可能会导致数据丢失。所以我们必须谨慎配置超时时间的属性。默认情况下,Flink Kafka sink(也就是Kafka producer端的配置)设置transaction.timeout.ms为1小时。也就是说,我们需要对应调整Kafka broker端的transaction.max.timeout.ms配置,因为此配置的默认时间为15分钟,而此时间必须要大于transaction.timeout.ms。还有一点需要注意的是:committed 消息的可见性是取决于Flink application的检查点时间间隔的。
检查Kafka集群的配置
Kafka集群的默认配置可能会导致数据丢失(即使一个写操作已经被ack)。我们需要特别注意一下Kafka启动参数:
- acks
- log.flush.interval.messages
- log.flush.interval.ms
- log.flush.*
建议查阅一下Kakfa 官方文档,对这些配置信息有更进一步的了解。
用户自定义partitioning以及写入消息时间戳
在向一个Kafka topic写入消息时,Flink Kafka sink taks可以选择写入topic的哪个partition。FlinkKafkaPartitioner可以在Flink Kafka sink构造函数中指定(此类为一个抽象类,需要传入它的一个实现类)。若是未指定,则默认的partitioner会将每个sink task均映射到一个Kafka partition中,也就是说,所有由同一个sink释放的records会被写入到同一个partition中。若是task的数目大于partition的数目,则其中部分partition可能会包含多个sink tasks的数据。如果partition的数目大于task的数目,则默认的配置会导致有partition的数据为空。在这种情况下,若是application是运行在event-time模式下对topic进行消费,可能会造成问题。
通过提供用户定义的FlinkKafkaPartitioner,我们可以控制records路由到partition的规则。例如,我们创建一个基于key的partitioner、或是轮询的partitioner(可平均分布records)。也可以使用Kafka的partitioning规则,根据message的key,将record分布到不同的partition中。使用此方式时,需要指定KeyedSerializationSchema,以便于从messages中抽取keys,并需要设置FlinkKafkaPartitioner为null,以disable默认的Flink端的partitioner。
最后,Flink Kafka sink可以配置为写入消息时间戳(Kafka 0.10 版本之后支持)。为一条record写入event-time时间戳到Kafka的功能可通过在sink对象上调用setWriteTimestampToKafka(true)启用。
References:
Vasiliki Kalavri, Fabian Hueske. Stream Processing With Apache Flink. 2019
以上是关于Flink读写Kafka的主要内容,如果未能解决你的问题,请参考以下文章