KNN
Posted zym-yc
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了KNN相关的知识,希望对你有一定的参考价值。
一、knn的原理
K-近邻算法采用测量不同特征值之间的距离方法进行分类。
问题是求某点的最近 K 个点。求两点间距离公式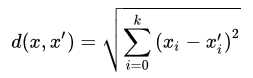 ,此外还可能需要增加权重
,此外还可能需要增加权重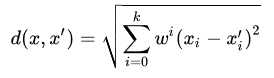
优点:精度高、对异常值不敏感、无数据输入假定。
缺点:时间复杂度高、空间复杂度高。
1、当样本不平衡时,比如一个类的样本容量很大,其他类的样本容量很小,输入一个样本的时候,K个临近值中大多数都是大样本容量的那个类,这时可能就会导致分类错误。可以对K临近点进行加权,也就是距离近的点的权值大,距离远的点权值小。
2、计算量较大,每个待分类的样本都要计算它到全部点的距离,根据距离排序才能求得K个临近点,可以先对已知样本点进行剪辑,事先去除对分类作用不大的样本。
适用数据范围:数值型和标称型
二、python实现knn
参考链接:https://www.cnblogs.com/lyuzt/p/10471617.html
‘‘‘ trainData - 训练集 testData - 测试集 labels - 分类 ‘‘‘ def knn(trainData, testData, labels, k): # 计算训练样本的行数 rowSize = trainData.shape[0] # 计算训练样本和测试样本的差值 diff = np.tile(testData, (rowSize, 1)) - trainData # 计算差值的平方和 sqrDiff = diff ** 2 sqrDiffSum = sqrDiff.sum(axis=1) # 计算距离 distances = sqrDiffSum ** 0.5 # 对所得的距离从低到高进行排序 sortDistance = distances.argsort() count = {} for i in range(k): vote = labels[sortDistance[i]] count[vote] = count.get(vote, 0) + 1 # 对类别出现的频数从高到低进行排序 sortCount = sorted(count.items(), key=operator.itemgetter(1), reverse=True) # 返回出现频数最高的类别 return sortCount[0][0]
python调用
from sklearn.neighbors import KNeighborsClassifier neigh = KNeighborsClassifier(n_neighbors=3) #根据数据判别性别 #身高、体重、鞋的尺寸 X = np.array([[181,80,44],[177,70,43],[160,60,38],[154,54,37], [166,65,40],[190,90,47],[175,64,39],[177,70,40], [159,55,37],[171,75,42],[181,85,43]]) display(X) y = [‘male‘,‘male‘,‘female‘,‘female‘,‘male‘,‘male‘,‘female‘,‘female‘,‘female‘,‘male‘,‘male‘] # 第1步:训练数据 neigh.fit(X,y) # 第2步:预测数据 Z = neigh.predict(np.array([[190,70,43],[168,55,37]])) display(Z)
三、监督学习和非监督学习
通俗的说无监督的学习,就是事先不知道类别,自动将相似的对象归到同一个簇中。监督学习是指数据集的正确输出已知情况下的一类学习算法。因为输入和输出已知,意味着输入和输出之间有一个关系,监督学习算法就是要发现和总结这种“关系”。
监督学习常见算法有:线性回归、神经网络、决策树、支持向量机、KNN、朴素贝叶斯算法等
无监督学习常见算法有:主成分分析法(PCA)、异常检测法、自编码算法等。
以上是关于KNN的主要内容,如果未能解决你的问题,请参考以下文章