数据库
Posted ustc-anmin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库相关的知识,希望对你有一定的参考价值。
并发事务带来哪些问题?
在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务(多个用户对同一数据进行操作)。并发虽然是必须的,但可能会导致以下的问题。
- 脏读(Dirty read): 当一个事务正在访问数据并且对数据进行了修改,而这种修改还没有提交到数据库中,这时另外一个事务也访问了这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是“脏数据”,依据“脏数据”所做的操作可能是不正确的。
- 丢失修改(Lost to modify): 指在一个事务读取一个数据时,另外一个事务也访问了该数据,那么在第一个事务中修改了这个数据后,第二个事务也修改了这个数据。这样第一个事务内的修改结果就被丢失,因此称为丢失修改。 例如:事务1读取某表中的数据A=20,事务2也读取A=20,事务1修改A=A-1,事务2也修改A=A-1,最终结果A=19,事务1的修改被丢失。
- 不可重复读(Unrepeatableread): 指在一个事务内多次读同一数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,因此称为不可重复读。
- 幻读(Phantom read): 幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。
事务隔离级别有哪些?mysql的默认隔离级别是?
SQL 标准定义了四个隔离级别:
- READ-UNCOMMITTED(读取未提交): 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
- READ-COMMITTED(读取已提交): 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
- REPEATABLE-READ(可重复读): 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
- SERIALIZABLE(可串行化): 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
一条SQL语句执行得很慢的原因有哪些?
1、大多数情况是正常的,只是偶尔会出现很慢的情况。
2、在数据量不变的情况下,这条SQL语句一直以来都执行的很慢。
1.1、数据库在刷新脏页(flush)
刷脏页有下面4种场景(后两种不用太关注“性能”问题):
-
redolog写满了:redo log 里的容量是有限的,如果数据库一直很忙,更新又很频繁,这个时候 redo log 很快就会被写满了,这个时候就没办法等到空闲的时候再把数据同步到磁盘的,只能暂停其他操作,全身心来把数据同步到磁盘中去的,而这个时候,就会导致我们平时正常的SQL语句突然执行的很慢,所以说,数据库在在同步数据到磁盘的时候,就有可能导致我们的SQL语句执行的很慢了。
-
内存不够用了:如果一次查询较多的数据,恰好碰到所查数据页不在内存中时,需要申请内存,而此时恰好内存不足的时候就需要淘汰一部分内存数据页,如果是干净页,就直接释放,如果恰好是脏页就需要刷脏页。
-
MySQL 认为系统“空闲”的时候:这时系统没什么压力。
-
MySQL 正常关闭的时候:这时候,MySQL 会把内存的脏页都 flush 到磁盘上,这样下次 MySQL 启动的时候,就可以直接从磁盘上读数据,启动速度会很快。
1.2、拿不到锁
2.1、没用到索引
(1)、字段没有索引
(2)、字段有索引,但却没有用索引
select * from t where c - 1 = 1000;
2.2、数据库自己选错索引了
其实是这样的,系统在执行这条语句的时候,会进行预测:究竟是走 c 索引扫描的行数少,还是直接扫描全表扫描的行数少呢?显然,扫描行数越少当然越好了,因为扫描行数越少,意味着I/O操作的次数越少。
如果是扫描全表的话,那么扫描的次数就是这个表的总行数了,假设为 n;而如果走索引 c 的话,我们通过索引 c 找到主键之后,还得再通过主键索引来找我们整行的数据,也就是说,需要走两次索引。而且,我们也不知道符合 100 c < and c < 10000 这个条件的数据有多少行,万一这个表是全部数据都符合呢?这个时候意味着,走 c 索引不仅扫描的行数是 n,同时还得每行数据走两次索引。
所以呢,系统是有可能走全表扫描而不走索引的。那系统是怎么判断呢?
判断来源于系统的预测,也就是说,如果要走 c 字段索引的话,系统会预测走 c 字段索引大概需要扫描多少行。如果预测到要扫描的行数很多,它可能就不走索引而直接扫描全表了。
那么问题来了,系统是怎么预测判断的呢?这里我给你讲下系统是怎么判断的吧,虽然这个时候我已经写到脖子有点酸了。
系统是通过索引的区分度来判断的,一个索引上不同的值越多,意味着出现相同数值的索引越少,意味着索引的区分度越高。我们也把区分度称之为基数,即区分度越高,基数越大。所以呢,基数越大,意味着符合 100 < c and c < 10000 这个条件的行数越少。
所以呢,一个索引的基数越大,意味着走索引查询越有优势。
那么问题来了,怎么知道这个索引的基数呢?
系统当然是不会遍历全部来获得一个索引的基数的,代价太大了,索引系统是通过遍历部分数据,也就是通过采样的方式,来预测索引的基数的。
扯了这么多,重点的来了,居然是采样,那就有可能出现失误的情况,也就是说,c 这个索引的基数实际上是很大的,但是采样的时候,却很不幸,把这个索引的基数预测成很小。例如你采样的那一部分数据刚好基数很小,然后就误以为索引的基数很小。然后就呵呵,系统就不走 c 索引了,直接走全部扫描了。
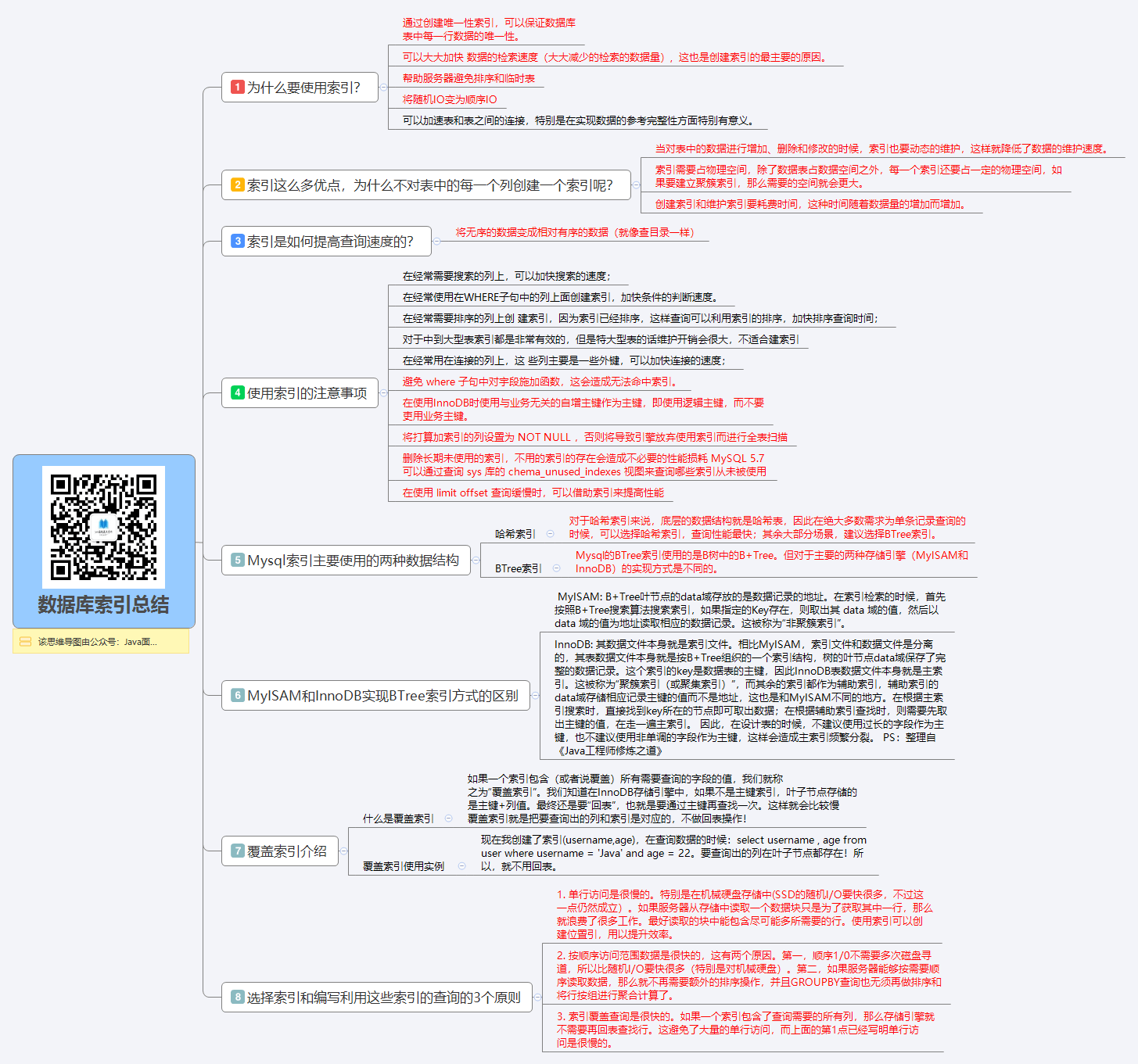
索引提高检索速度
首先Mysql的基本存储结构是页(记录都存在页里边):
- 各个数据页可以组成一个双向链表
- 而每个数据页中的记录又可以组成一个单向链表
- 每个数据页都会为存储在它里边儿的记录生成一个页目录,在通过主键查找某条记录的时候可以在页目录中使用二分法快速定位到对应的槽,然后再遍历该槽对应分组中的记录即可快速找到指定的记录
- 以其他列(非主键)作为搜索条件:只能从最小记录开始依次遍历单链表中的每条记录。
其实就是将无序的数据变成有序(相对):
1.9索引总结
索引在数据库中是一个非常重要的知识点!上面谈的其实就是索引最基本的东西,要创建出好的索引要顾及到很多的方面:
- 1,最左前缀匹配原则。这是非常重要、非常重要、非常重要(重要的事情说三遍)的原则,MySQL会一直向右匹配直到遇到范围查询
(>,<,BETWEEN,LIKE)就停止匹配。 - 3,尽量选择区分度高的列作为索引,区分度的公式是
COUNT(DISTINCT col) / COUNT(*)。表示字段不重复的比率,比率越大我们扫描的记录数就越少。 - 4,索引列不能参与计算,尽量保持列“干净”。比如,
FROM_UNIXTIME(create_time) = ‘2016-06-06‘就不能使用索引,原因很简单,B+树中存储的都是数据表中的字段值,但是进行检索时,需要把所有元素都应用函数才能比较,显然这样的代价太大。所以语句要写成 :create_time = UNIX_TIMESTAMP(‘2016-06-06‘)。 - 5,尽可能的扩展索引,不要新建立索引。比如表中已经有了a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
- 6,单个多列组合索引和多个单列索引的检索查询效果不同,因为在执行SQL时,MySQL只能使用一个索引,会从多个单列索引中选择一个限制最为严格的索引。
以上是关于数据库的主要内容,如果未能解决你的问题,请参考以下文章
将代码片段插入数据库并在 textarea 中以相同方式显示
python 用于数据探索的Python代码片段(例如,在数据科学项目中)
如何在片段中使用 GetJsonFromUrlTask.java