爬取---Books to Scrape(第一页所有书名和价格)
Posted cfancy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取---Books to Scrape(第一页所有书名和价格)相关的知识,希望对你有一定的参考价值。
1、首先在终端建立一个项目 项目名为bookspider 建立过程在这里就略写了
网站链接:http://books.toscrape.com/catalogue/page-1.html
2、打开文件spider——books.py文件以及settings.py文件
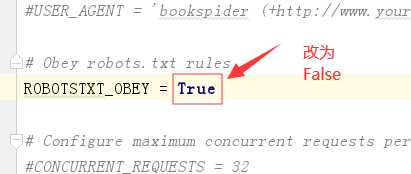
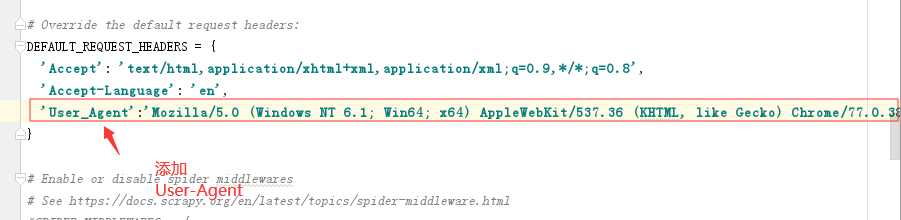
重新配置settings.py文件的内容
3、打开books.py编辑代码


1 import scrapy 2 3 from scrapy.http.response.html import HtmlResponse 4 5 class BooksSpider(scrapy.Spider): 6 name = ‘books‘ 7 allowed_domains = [‘books.toscrape.com‘] 8 start_urls = [‘http://books.toscrape.com/catalogue/page-1.html‘] 9 10 11 def parse(self, response): 12 # print(‘*‘) 13 # print(type(response)) # <class ‘scrapy.http.response.html.HtmlResponse‘> 14 # print(‘*‘) 15 16 Books_lis = response.xpath("//div/ol[@class=‘row‘]/li") 17 #print(Books_lis) 18 for Books_li in Books_lis: 19 book_name = Books_li.xpath(".//h3/a") 20 print(book_name) 21 22 for prices_li in Books_lis: 23 book_price = prices_li.xpath(".//div[@class=‘product_price‘]/p[@class=‘price_color‘]/text()").get() 24 print(book_price)
4、运行结果
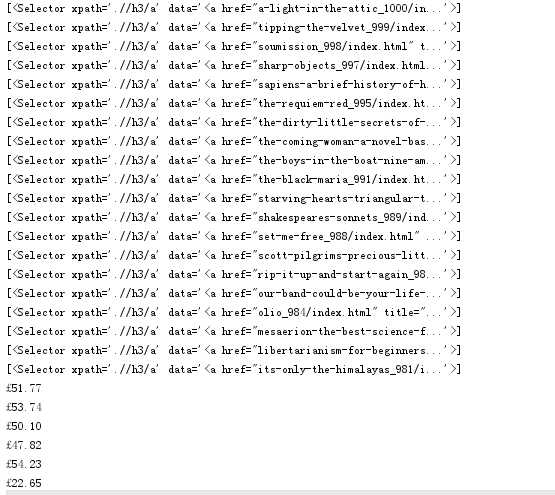

运行程序可以的方法:
1、直接通过终端 win+R
2、通过pycharm中的Terminal打开终端
3、在项目文件夹下建立一个Python文件 上例文件名为start.py

输入
from scrapy import cmdline # cmdline.execute("scrapy crawl books").split() 等价下面的cmd cmdline.execute(["scrapy","crawl","books"])
其中 books 是文件名
然后点击运行即可
以上是关于爬取---Books to Scrape(第一页所有书名和价格)的主要内容,如果未能解决你的问题,请参考以下文章