梳理NLP预训练模型
Posted mokoaxx
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了梳理NLP预训练模型相关的知识,希望对你有一定的参考价值。
在2017年之前,语言模型都是通过RNN,LSTM来建模,这样虽然可以学习上下文之间的关系,但是无法并行化,给模型的训练和推理带来了困难,因此有人提出了一种完全基于attention来对语言建模的模型,叫做transformer。transformer摆脱了NLP任务对于RNN,LSTM的依赖,使用了self-attention的方式对上下文进行建模,提高了训练和推理的速度。
1、Transformer
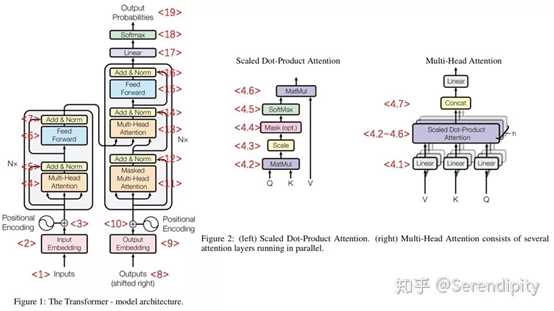
<1> Inputs是经过padding的输入数据,大小是[batch size, max seq length]。
<2> 初始化embedding matrix,通过embedding lookup将Inputs映射成token embedding,大小是[batch size, max seq length, embedding size],然后乘以embedding size的开方。
<3> 通过sin和cos函数创建positional encoding,表示一个token的绝对位置信息,并加入到token embedding中,然后dropout。
<4> multi-head attention
<4.1> 输入token embedding,通过Dense生成Q,K,V,大小是[batch size, max seq length, embedding size],然后按第2维split成num heads份并按第0维concat,生成新的Q,K,V,大小是[num heads*batch size, max seq length, embedding size/num heads],完成multi-head的操作。
<4.2> 将K的第1维和第2维进行转置,然后Q和转置后的K的进行点积,结果的大小是[num heads*batch size, max seq length, max seq length]。
<4.3> 将<4.2>的结果除以hidden size的开方(在transformer中,hidden size=embedding size),完成scale的操作。
<4.4> 将<4.3>中padding的点积结果置成一个很小的数(-2^32+1),完成mask操作,后续softmax对padding的结果就可以忽略不计了。
<4.5> 将经过mask的结果进行softmax操作。
<4.6> 将softmax的结果和V进行点积,得到attention的结果,大小是[num heads*batch size, max seq length, hidden size/num heads]。
<4.7> 将attention的结果按第0维split成num heads份并按第2维concat,生成multi-head attention的结果,大小是[batch size, max seq length, hidden size]。Figure 2上concat之后还有一个linear的操作,但是代码里并没有。
<5> 将token embedding和multi-head attention的结果相加,并进行Layer Normalization。
<6> 将<5>的结果经过2层Dense,其中第1层的activation=relu,第2层activation=None。
<7> 功能和<5>一样。
<8> Outputs是经过padding的输出数据,与Inputs不同的是,Outputs的需要在序列前面加上一个起始符号”<s>”,用来表示序列生成的开始,而Inputs不需要。
<9> 功能和<2>一样。
<10> 功能和<3>一样。
<11> 功能和<4>类似,唯一不同的一点在于mask,<11>中的mask不仅将padding的点积结果置成一个很小的数,而且将当前token与之后的token的点积结果也置成一个很小的数。
<12> 功能和<5>一样。
<13> 功能和<4>类似,唯一不同的一点在于Q,K,V的输入,<13>的Q的输入来自于Outputs 的token embedding,<13>的K,V来自于<7>的结果。
<14> 功能和<5>一样。
<15> 功能和<6>一样。
<16> 功能和<7>一样,结果的大小是[batch size, max seq length, hidden size]。
<17> 将<16>的结果的后2维和embedding matrix的转置进行点积,生成的结果的大小是[batch size, max seq length, vocab size]。
<18> 将<17>的结果进行softmax操作,生成的结果就表示当前时刻预测的下一个token在vocab上的概率分布。
<19> 计算<18>得到的下一个token在vocab上的概率分布和真实的下一个token的one-hot形式的cross entropy,然后sum非padding的token的cross entropy当作loss,利用adam进行训练。
more : multi-head相当于把一个大空间划分成多个互斥的小空间,然后在小空间内分别计算attention,虽然单个小空间的attention计算结果没有大空间计算得精确,但是多个小空间并行然后concat有助于网络捕捉到更丰富的信息。
当模型变得越来越大,样本数越来越多的时候,self-attention无论是并行化带来的训练提速,还是在长距离上的建模,都是要比传统的RNN,LSTM好很多。transformer现在已经各种具有代表性的nlp预训练模型的基础,bert系列使用了transformer的encoder,gpt系列transformer的decoder。在推荐领域,transformer的multi-head attention也应用得很广泛。
2、BERT
在bert之前,将预训练的embedding应用到下游任务的方式大致可以分为2种,一种是feature-based,例如ELMo这种将经过预训练的embedding作为特征引入到下游任务的网络中;一种是fine-tuning,例如GPT这种将下游任务接到预训练模型上,然后一起训练。然而这2种方式都会面临同一个问题,就是无法直接学习到上下文信息,像ELMo只是分别学习上文和下文信息,然后concat起来表示上下文信息,抑或是GPT只能学习上文信息。因此,作者提出一种基于transformer encoder的预训练模型,可以直接学习到上下文信息,叫做bert。bert使用了12个transformer encoder block,在13G的数据上进行了预训练,可谓是nlp领域大力出奇迹的代表。在整个流程上与transformer encoder没有大的差别,只是在embedding,multi-head attention,loss上有所差别。
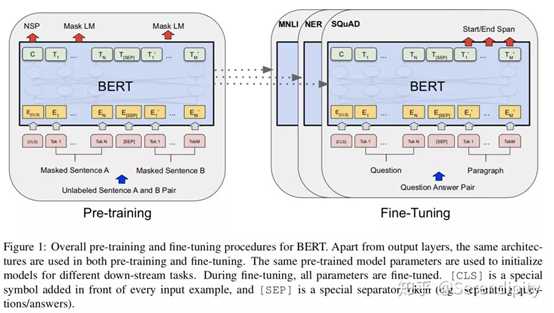
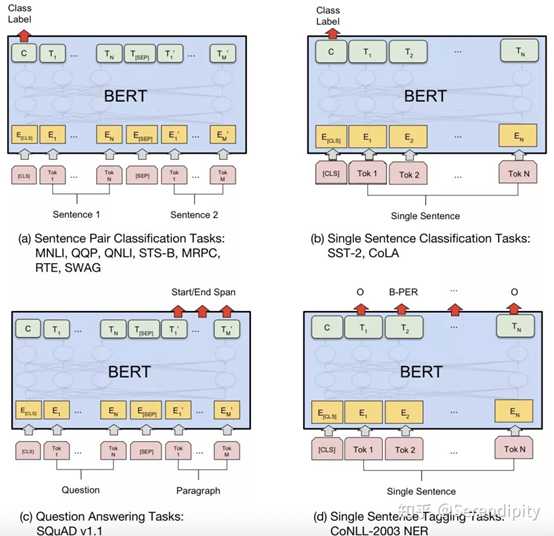
bert和transformer在embedding上的差异主要有3点:
<1> transformer的embedding由2部分构成,一个是token embedding,通过embedding matrix lookup到token_ids上生成表示token的向量;一个是position embedding,是通过sin和cos函数创建的定值向量。而bert的embedding由3部分构成,第一个同样是token embedding,通过embedding matrix lookup到token_ids上生成表示token的向量;第二个是segment embedding,用来表达当前token是来自于第一个segment,还是第二个segment,因此segment vocab size是2;第三个是position embedding,与transformer不同的是,bert创建了一个position embedding matrix,通过position embedding matrix lookup到token_ids的位置上生成表示token位置的位置向量。
<2> transformer在embedding之后跟了一个dropout,但是bert在embedding之后先跟了一个layer normalization,再跟了一个dropout。
<3> bert在token序列之前加了一个特定的token“[cls]”,这个token对应的向量后续会用在分类任务上;如果是句子对的任务,那么两个句子间使用特定的token“[seq]”来分割。
bert和transformer在multi-head attention上的差异:
<1> transformer在<4.7>会concat<4.6>的attention的结果。而bert不仅会concat<4.6>的attention的结果,还会把前N-1个encoder block中attention的结果都concat进来。
<2> transformer在<4.7>之后没有linear的操作,而bert在transformer的<4.7>之后有一个linear的操作。
bert和transformer在loss上的差异:bert预训练的loss由2部分构成,一部分是NSP的loss,就是token“[cls]”经过1层Dense,然后接一个二分类的loss,其中0表示segment B是segment A的下一句,1表示segment A和segment B来自2篇不同的文本;另一部分是MLM的loss,segment中每个token都有15%的概率被mask,而被mask的token有80%的概率用“<mask>”表示,有10%的概率随机替换成某一个token,有10%的概率保留原来的token,被mask的token经过encoder后乘以embedding matrix的转置会生成在vocab上的分布,然后计算分布和真实的token的one-hot形式的cross entropy,最后sum起来当作loss。这两部分loss相加起来当作total loss,利用adam进行训练。bert fine-tune的loss会根据任务性质来设计,例如分类任务中就是token“[cls]”经过1层Dense,然后接了一个二分类的loss;例如问题回答任务中会在paragraph上的token中预测一个起始位置,一个终止位置,然后以起始位置和终止位置的预测分布和真实分布为基础设计loss;例如序列标注,预测每一个token的词性,然后以每一个token在词性的预测分布和真实分布为基础设计loss。 bert在encoder之后,在计算NSP和MLM的loss之前,分别对NSP和MLM的输入加了一个Dense操作,这部分参数只对预训练有用,对fine-tune没用。而transformer在decoder之后就直接计算loss了,中间没有Dense操作。
bert的框架决定了这个模型适合解决自然语言理解的问题,因为没有解码的过程,所以bert不适合解决自然语言生成的问题。
增大预训练模型的大小通常能够提高预训练模型的推理能力,但是当预训练模型增大到一定程度之后,会碰到GPU/TPU memory的限制。因此,albert作者在bert中加入了2项减少参数的技术,能够缩小bert的大小,并且修改了bert NSP的loss,在和bert有相同参数量的前提之下,有更强的推理能力。
3、albert
在bert以及诸多bert的改进版中,embedding size都是等于hidden size的,这不一定是最优的。因为bert的token embedding是上下文无关的,而经过multi-head attention+ffn后的hidden embedding是上下文相关的,bert预训练的目的是提供更准确的hidden embedding,而不是token embedding,因此token embedding没有必要和hidden embedding一样大。albert将token embedding进行了分解,首先降低embedding size的大小,然后用一个Dense操作将低维的token embedding映射回hidden size的大小。bert的embedding size=hidden size,因此词向量的参数量是vocab size * hidden size,进行分解后的参数量是vocab size * embedding size + embedding size * hidden size,只要embedding size << hidden size,就能起到减少参数的效果。
bert的12层transformer encoder block是串行在一起的,每个block虽然长得一模一样,但是参数是不共享的。albert将transformer encoder block进行了参数共享,这样可以极大地减少整个模型的参数量。
在auto-encoder的loss之外,bert使用了NSP的loss,用来提高bert在句对关系推理任务上的推理能力。而albert放弃了NSP的loss,使用了SOP的loss。NSP的loss是判断segment A和segment B之间的关系,其中0表示segment B是segment A的下一句,1表示segment A和segment B来自2篇不同的文本。SOP的loss是判断segment A和segment B的的顺序关系,0表示segment B是segment A的下一句,1表示segment A是segment B的下一句。
albert使用了2项参数减少的技术,但是2项技术对于参数减少的贡献是不一样的,第1项是词向量矩阵的分解,当embedding size从768降到64时,可以节省21M的参数量,但是模型的推理能力也会随之下降。第2项是multi-head attention+ffn的参数共享,在embedding size=128时,可以节省77M的参数量,模型的推理能力同样会随之下降。虽然参数减少会导致了模型推理能力的下降,但是可以通过增大模型使得参数量变回和bert一个量级,这时模型的推理能力就超过了bert。
在albert之前,很多bert的改进版都对NSP的loss提出了质疑。structbert在NSP的loss上进行了修改,有1/3的概率是segment B是segment A的下一句,有1/3的概率是segment A是segment B的下一句,有1/3的概率是segment A和segment B来自2篇不同的文本。roberta则是直接放弃了NSP的loss,修改了样本的构造方式,将输入2个segment修改为从一个文本中连续sample句子直到塞满512的长度。当到达文本的末尾且未塞满512的长度时,先增加一个“[sep]”,再从另一个文本接着sample,直到塞满512的长度。
albert在structbert的基础之上又抛弃了segment A和segment B来自2篇不同的文本的做法,只剩下1/2的概率是segment B是segment A的下一句,1/2的概率是segment A是segment B的下一句。论文中给出了这么做的解释,NSP的loss包含了2部分功能:topic prediction和coherence prediction,其中topic prediction要比coherence prediction更容易学习,而MLM的loss也包含了topic prediction的功能,因此bert难以学到coherence prediction的能力。albert的SOP loss抛弃了segment A和segment B来自2篇不同的文本的做法,让loss更关注于coherence prediction,这样就能提高模型在句对关系推理上的能力。
albert虽然减少参数量,但是并不会减少推理时间,推理的过程只不过是从串行计算12个transformer encoder block变成了循环计算transformer encoder block 12次。albert最大的贡献在于使模型具备了比原始的bert更强的成长性,在模型变向更大的时候,推理能力还能够得到提高。
4、GPT、structbert、xlnet
gpt在bert之前就发表了,使用了transformer decoder作为预训练的框架。在看到了decoder只能get上文信息,不能get下文信息的缺点之后,bert改用了transformer encoder作为预训练的框架,能够同时get上下文信息,获得成功。
structbert的创新点主要在loss上,除了MLM的loss外,还有一个重构token顺序的loss和一个判断2个segment关系的loss。重构token顺序的loss是以一定的概率挑选segment中的token三元组,然后随机打乱顺序,最后经过encoder之后能够纠正被打乱顺序的token三元组的顺序。判断2个segment关系的loss是1/3的概率是segment B是segment A的下一句,有1/3的概率是segment A是segment B的下一句,有1/3的概率是segment A和segment B来自2篇不同的文本,通过“[cls]”预测样本属于这3种的某一种。
在xlnet使用126G的数据登顶GLUE之后不久,roberta使用160G的数据又打败了xlnet。roberta的创新点主要有4点:第1点是动态mask,之前bert使用的是静态mask,就是数据预处理的时候完成mask操作,之后训练的时候同一个样本都是相同的mask结果,动态mask就是在训练的时候每输入一个样本都要重新mask,动态mask相比静态mask有更多不同mask结果的数据用于训练,效果很好。第2点是样本的构造方式,roberta放弃了NSP的loss,修改了样本的构造方式,将输入2个segment修改为从一个文本中连续sample句子直到塞满512的长度。当到达文本的末尾且未塞满512的长度时,先增加一个“[sep]”,再从另一个文本接着sample,直到塞满512的长度。第3点是增大了batch size,在训练相同数据量的前提之下,增大batch size能够提高模型的推理能力。第4点是使用了subword的分词方法,类比于中文的字,相比于full word的分词方法,subword的分词方法使得词表的大小从30k变成了50k,虽然实验效果上subword的分词方法比full word差,但是作者坚信subword具备了理论优越性,今后肯定会比full word好。
本文来自某大神的文章,仅个人学习理解用,侵删~
以上是关于梳理NLP预训练模型的主要内容,如果未能解决你的问题,请参考以下文章