jieba库的分词和词云
Posted gtxy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了jieba库的分词和词云相关的知识,希望对你有一定的参考价值。
1.分词

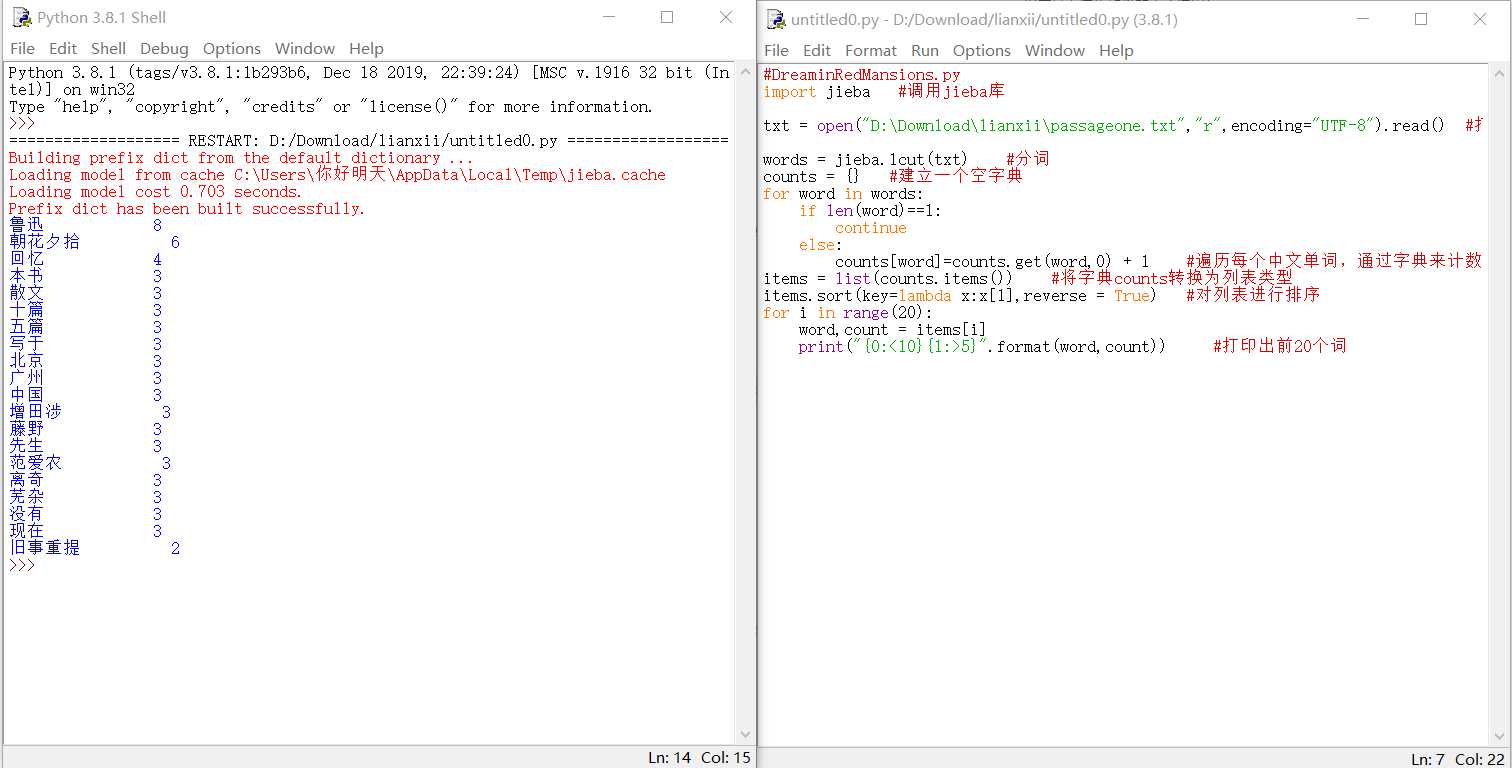
#DreaminRedMansions.py
import jieba #调用jieba库
txt = open("D:Downloadlianxiipassageone.txt","r",encoding="UTF-8").read() #打开txt文件阅读
words = jieba.lcut(txt) #分词
counts = {} #建立一个空字典
for word in words:
if len(word)==1:
continue
else:
counts[word]=counts.get(word,0) + 1 #遍历每个中文单词,通过字典来计数
items = list(counts.items()) #将字典counts转换为列表类型
items.sort(key=lambda x:x[1],reverse = True) #对列表进行排序
for i in range(20):
word,count = items[i]
print("{0:<10}{1:>5}".format(word,count)) #打印出前20个词
自选一篇文章,结果如下
2.词云
from wordcloud import WordCloud
import jieba
def create_word_cloud():
path_txt = ‘D:Downloadlianxiipassageone.txt‘
text = open(path_txt,"r",encoding="UTF-8").read()
wordlist = jieba.lcut(text) # jieba分词
wl = " ".join(wordlist)
# 设置词云
w = WordCloud(
# 设置背景颜色为白色
background_color="white",
# 设置最大显示的词云数为200
max_words=200,
# 字体的一般路径--宋体
font_path=‘simsun.ttc‘,
height=1200,
width=1600,
# 设置字体最大的字体大小
max_font_size=100,
# 设置配色方案
random_state=100,
)
w.generate(wl) # 生成词云
w.to_file(‘img_book1.png‘) # 把词云保存下
if __name__ == ‘__main__‘:
create_word_cloud()

以上是关于jieba库的分词和词云的主要内容,如果未能解决你的问题,请参考以下文章