十XPath与lxml类库
Posted nuochengze
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了十XPath与lxml类库相关的知识,希望对你有一定的参考价值。
1、XML语言
(1)XML指可扩展标记语言(EXtensible Markup Language)
(2)XML是一中标记语言,类似于html
(3)XML的设计宗旨是传输数据,而非显示数据
(4)XML的标签需要我们自行定义
(5)XML被设计为具有自我描述性
(6)XML是W3C的推荐标准
官方文档:https://www.w3school.com.cn/xml/index.asp
2、XML和HTML的区别
| 数据格式 | 描述 | 设计目标 |
|---|---|---|
| XML | Extensible Markup Language (可扩展标记语言) |
被设计为传输和存储数据,其焦点是数据的内容。 |
| HTML | HyperText Markup Language (超文本标记语言) |
显示数据以及如何更好显示数据。 |
| HTML DOM | Document Object Model for HTML (文档对象模型) |
通过 HTML DOM,可以访问所有的 HTML 元素,连同它们所包含的文本和属性。可以对其中的内容进行修改和删除,同时也可以创建新的元素。 |
3、HTML DOM模型
HTML DOM定义了访问和操作HTML文档的标准方法,以树结构方式表达HTML文档。
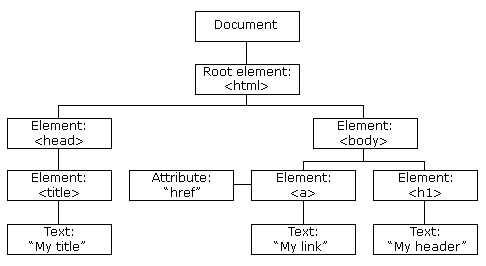
4、XML的节点关系
4.1 父(Parent)
每个元素以及属性都有一个父
<?xml version="1.0" encoding="utf-8"?> <book> <title>Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book>
book元素是title、author、year以及price元素的父。
4.2 子(Children)
元素节点可有零个、一个或多个子
title、author、year以及price元素都是book元素的子。
4.3 同胞(Sibling)
拥有相同的父的节点
title、author、year和price元素都是同胞
4.4 先辈(Ancestor)
某节点的父、父的父等
<?xml version="1.0" encoding="utf-8"?> <bookstore> <book> <title>Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> </bookstore>
title元素的先辈是book元素和bookstore元素
4.5 后代(Descendant)
某个节点的子,子的子等
bookstore的后代是book、title、author、year以及price元素
5、XPath
XPath(XML Path Language)是一门在XML文档中查找信息的语言,可用来在XML文档中对元素和属性进行遍历。
XPath的官方文档:https://www.w3school.com.cn/xpath/index.asp
6、XPath开发工具
(1)开源的XPath表达式编辑工具:XMLQuire(XML格式文件可用)
(2)Chrome插件XPath Helper
(3)Firefox插件XPath Checker
7、选取节点
XPath使用路径表达式来选取XML文档中的节点或者节点集。
7.1 最常用的路径表达式
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
路径表达式以及表达式的结果:
`bookstore` 选取bookstore元素的所有子节点
`/bookstore` 选取根元素bookstore。注释:假如路径起始于正斜杠(/),则此路径始终代表到某元素的绝对路径。
`bookstore/book` 选取属于bookstore的子元素的所有book元素
`//book` 选取所有book子元素,而不管它们在文档中的位置
`bookstore//book` 选择属于bookstore元素的后代的所有book元素,而不管它们位于bookstore之下的什么位置
`//@lang` 选取名为lang的所有属性
7.2 谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点,被嵌在方括号中。
路径表达式以及表达式的结果:
`/bookstore/book[1]` 选取属于bookstore子元素的第一个book元素
`/bookstore/book[last()]` 选取属于bookstore子元素的最后一个book元素
`/bookstore/book[last()-1]` 选取属于bookstore子元素的倒数第二个book元素
`/bookstore/book[position()<3]` 选取最前面的两个属于bookstore元素的子元素的book元素
`//title[@lang=‘eng‘]` 选取所有title元素,且这些元素拥有值为eng的lang属性
`//title[@lang]` 选取所有拥有名为lang的属性的title元素
`/bookstore/book[price>35.00]` 选取bookstore元素的所有book元素,且其中的price元素的值必须大于35.00
`/bookstore/book[price>35.00]/title` 选取bookstore元素的所有book元素中的,price元素值大于35的条件下,book元素中的title元素。
7.3 选取未知节点
XPath通配符可以用来选取位置的XML元素。
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
路径表达式以及表达式的结果:
`/bookstore/*` 选取bookstore元素的所有子元素
`//*` 选取文档中的所有元素
`html/node()/meta/@*` 选取html下面任意节点下的meta节点的所有属性
`//title[@*]` 选取所有带有属性的title元素
7.4 选取若干路径
通过在路径表达式中使用"|"运算符,可以选取若干个路径。
`//book/title | //book/price` 选取book元素的所有title和price元素
`//title | //price` 选取文档中的所有title和price元素
`/bookstore/book/title | //price` 选取属于bookstore元素的book元素的所有title元素,以及文档中所有的price元素
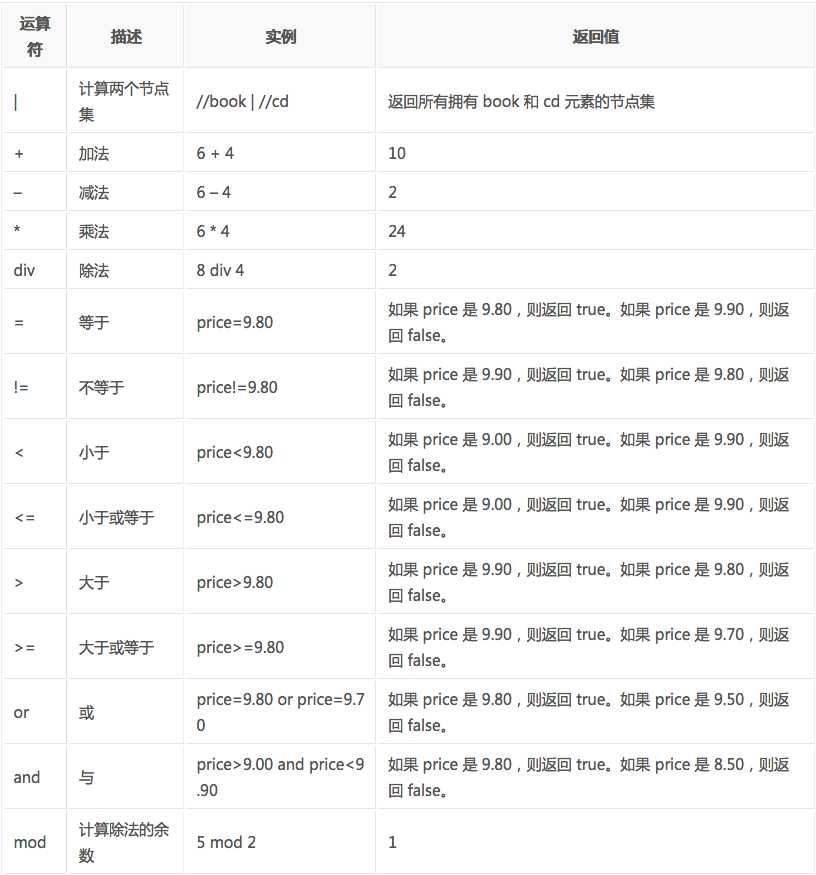
7.5 XPath的运算符
8、lxml库
lxml是一个HTML/XML的解析器,主要的功能是如何解析和提取HTML/XML数据。
lxml和正则一样,也是用 C 实现的,是一款高性能的 Python HTML/XML 解析器,可以利用之前的XPath语法,来快速的定位特定元素以及节点信息。
lxml python的官方文档:https://lxml.de/index.html
安装:`pip install lxml`
from lxml import etree from pprint import pprint text = """ <div> <ul> <li class="item-0"><a href="link1.html">first item</a></li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-inactive"><a href="link3.html">third item</a></li> <li class="item-1"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a></li> </div> """ # 利用etree.HTML,将字符串解析为HTML文档 html = etree.HTML(text) # 将字符串序列化为HTML文档 result = etree.tostring(html) # print(result.decode()) # 利用etree.parse()来读取外部文件 html = etree.parse("./hello.html") result = etree.tostring(html,pretty_print=True) # print(result.decode()) print(type(html)) # <class ‘lxml.etree._ElementTree‘> ret = html.xpath("//li") print(ret) print(len(ret)) print(type(ret)) print(type(ret[0])) #[<Element li at 0x7f58af103348>, <Element li at 0x7f58af103388>, <Element li at 0x7f58af1033c8>, <Element li at 0x7f58af103408>, <Element li at 0x7f58af103448>] #5 #<class ‘list‘ > #<class ‘lxml.etree._Element‘ >
以上是关于十XPath与lxml类库的主要内容,如果未能解决你的问题,请参考以下文章