ML-Review-集成-bagging-RF
Posted a-lam
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ML-Review-集成-bagging-RF相关的知识,希望对你有一定的参考价值。
集成学习(ensemble learning)—bagging—RF
Bagging主要关注降低方差。(low variance)Boosting关注的主要是降低偏差。(low bias)
bagging是对许多强(甚至过强)的分类器求平均。在这里,每个单独的分类器的bias都是低的,平均之后bias依然低;而每个单独的分类器都强到可能产生overfitting的程度,也就是variance高,求平均的操作起到的作用就是降低这个variance。
boosting是把许多弱的分类器组合成一个强的分类器。弱的分类器bias高,而强的分类器bias低,所以说boosting起到了降低bias的作用。variance不是boosting的主要考虑因素。Boosting 则是迭代算法,每一次迭代都根据上一次迭代的预测结果对样本进行加权,所以随着迭代不断进行,误差会越来越小,所以模型的 bias 会不断降低。这种算法无法并行,例子比如Adaptive Boosting.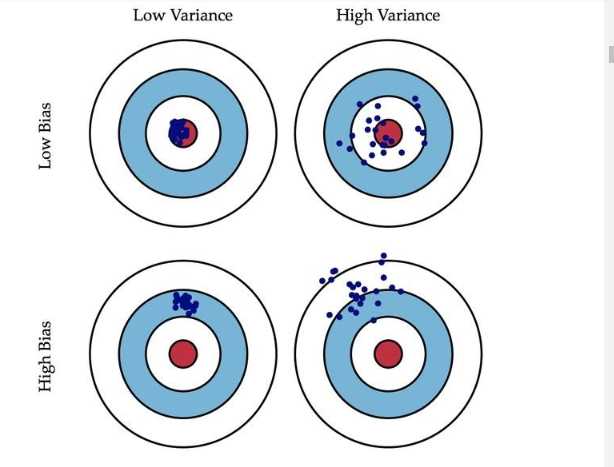
构建并组合多个学习器来完成学习任务,
同类型个体学习器(同质)——基学习器
不同累习惯个体学习器(异质)——个体学习器
原则:要获得比单一学习器更好的性能,个体学习器应该好而不同。即个体学习器应该具有一定的准确性,不能差于弱学习器,并且具有多样性,即学习器之间有差异。
根据个体学习器的生成方式,目前集成学习分为两大类:
- 个体学习器之间存在强依赖关系、必须串行生成的序列化方法。代表是Boosting。
- 个体学习器之间不存在强依赖关系、可同时生成的并行化方法。代表是Bagging和随机森林(Random Forest)
bagging在原始数据集上有放回抽样,选出S个新集,训练S个新的基学习器。
原数据会有63.2%会出现在采样集中,可推导。
分类——简单投票,回归——简单平均
Bagging优点:
- 高效。Bagging集成与直接训练基学习器的复杂度同阶。
- Bagging能不经修改的适用于多分类、回归任务。
- 包外估计。使用剩下的样本作为验证集进行包外估计(out-of-bag estimate)OOB
随机森林RF
bagging的变式,以决策树为基学习器。RF较决策树引入了 属性的随机选择
优点:随机可以采用到 均匀分布、高斯分布、置换
RF不再考虑全部属性,而是一个属性子集,计算开销小,训练效率高
随机的引入,不容易过拟合,抗噪声强
离散连续都可处理
基于oob误分类率和基于Gini系数的变化,可以得到变量的重要性(泛化能力退化程度,OOB用来验证过程推导——>笔记)
缺点:噪声较大时依然会过拟合
以上是关于ML-Review-集成-bagging-RF的主要内容,如果未能解决你的问题,请参考以下文章