《百度UNIT对话系统核心技术解析》2018-09
Posted cheesezh
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《百度UNIT对话系统核心技术解析》2018-09相关的知识,希望对你有一定的参考价值。
原文链接:https://mp.weixin.qq.com/s/n1ASECUOWH7UY73yDiVaUg

口语理解
- 基于语义解析的口语理解模式,是将用户请求解析为所包含语义信息的结构化表达。其中,最典型的结构化表达是意图(描述用户的核心诉求)+ 词槽(描述意图的关键信息)的模式。常用方法有基于知识规则的方法,基于机器学习的方法,基于融合策略的方法。
- 基于语义匹配的口语理解模式,不需要解析出具体的格式,而是需要寻找与其具有最高语义匹配程度的问答对。
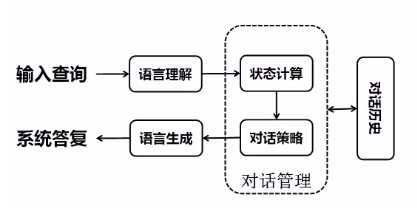
对话管理
- 对话状态跟踪,即根据对话历史计算当前对话状态,管理并更新对话历史。其常用方法为:基于人工规则的方法,基于机器学习的方法。通过建立影射,输入会话历史,然后输出当前对话状态。
- 对话策略选择,即根据当前对话状态,选择接下来最恰当的操作。其常用方法为:基于人工规则的方法,基于机器学习的方法,基于强化学习的方法。同样是通过建模影射的过程,输入当前对话状态,输出系统回复和指令执行。
系统评估
- 对单个系统的精度给出量化的指标数据,用于单个系统的精度评估。由于口语理解精度直接影响对话管理运行,进而影响对话系统效果,因此可以通过评估口语理解来评估对话系统。其中有三个指标:准确率(Precision),召回率(Recall),F 值(F-measure)。
- 对两个系统的精度对比给出量化的指标数据,用于系统迭代时给出精度对比。针对系统迭代需求,比较基线系统 X 和对比系统 Y 的优势。其中两个系统的定量对比涉及的指标:
- Diff 面:同一条 query 解析结果不一致的情况在抽样集合中的占比
- G(变好):针对同一条 query,Y 的结果比 X 好
- S(相同):针对同一条 query,Y 的结果与 X 差不多
- B(变差):针对同一条 query,Y 的结果比 X 差
- 如果 Y 要替换 X,至少 G>B;同时如果 Diff 面过大,需要考虑用户体验的波动。
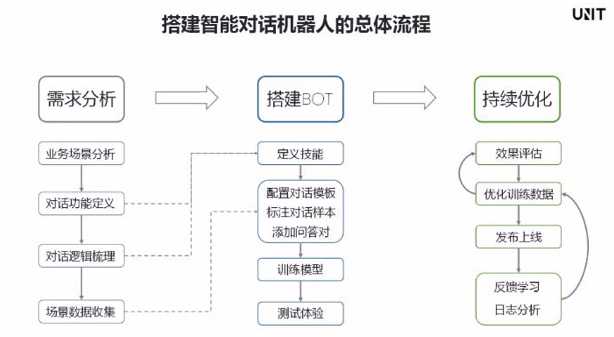
沙盒的概念。
关于数据量:100 可训;1000 可用
所有已标注样本都会进入 K-V 字典,K-V 字典保证样本一定会按标注的方式解析,当词槽识别出现不稳定时,注意看看样本
以上是关于《百度UNIT对话系统核心技术解析》2018-09的主要内容,如果未能解决你的问题,请参考以下文章