《微软小冰:如何构建人格化的对话系统》,2020-03,曾敏
Posted cheesezh
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《微软小冰:如何构建人格化的对话系统》,2020-03,曾敏相关的知识,希望对你有一定的参考价值。
原文链接:https://mp.weixin.qq.com/s/YkVPtdWQkY-5hyoQW26UPA
- 如何构建基本的对话系统?
- 人格化的定义及如何部分实现人格化
Conversation AI主要包括三个方向
- 第一个方向是Task Completion,这也是业界做的比较多的,包括客服机器人和各种代理等等,都定位在这个方向。这里存在一个问题,就是它的Scalability ( 可扩展性 ) 不是特别够。当你在做A场景的时候,可能产品设计思路、框架部分是能够复用的,但是你的模型、意图分类、serving,每个场景都会不一样。
- 第二个方向是做Information和Answers的攫取,有点类似于百度知道或者知乎上如何评价XX?这种话题。如果要搭建类似这样的系统,需要有很好的社区对内容进行维护,来尽可能的让知识库以及问题答案的丰富度和多样性在一个比较高的水平,它的局限性也在这个地方。
- 第三个方向是General Conversation ( 闲聊 ),也是小冰主要关注的方向。而这里比较大的问题是 ( Dynamic Context/Complex ) 长程的上下文非常的复杂,不仅仅是当前对话轮中会存在特别多的问题,包括用户昨天说过的话,一个月之前说过的话,可能都会对今天的对话内容造成比较大的影响,这是一个非常难的问题。
为什么订机票/订外卖不适合用对话系统来完成?
- 比如订机票或者订外卖,包括国内一些大厂也在做,通过对话系统完成类似的事情,但是市场上其实已经有了很好的APP能够快速的完成类似的任务。快速不是说简单点两下就完成了,而是说对话系统本身是有局限性的,首先对话是基于时间的行为序列,是一步一步往下走的,但是我们在做task时,其实有很多的工具、界面,可以一目十行的看到非常多的文字、图片和视频等各种各样的信息跟我们进行交互。由于通过文字进行交互,信息被极大的压缩了,人在接受文字类信息的处理速度相对来讲会比图像、视频等要慢一些。站在这个维度,由于Scalability局限性,以及市场上已经有了成型的产品在做这件事情,所以这块的上限或者想象空间会稍微低一些。(动手比动嘴更高效)
以Turn-oriented来设计?还是以Session-oriented来设计?
- 以Turn-oriented来设计业界比较传统的做法,当用户站在对话的某一时间节点时,可能背后会有很多的意图,很多的分类,这时需要做一个决策,到底是往A、B、C哪个方向走?
- 以Session-oriented来设计,就是说对话应该像河流一样,在实际的沟通过程中,并不是每一句话都有特别的信息量,并不是每一句话都是在做任务或者搜索。这些无用的对话,由于穿插在这些任务或者知识的获取中,并且前面有些无用的对话可能会对后边的推荐或者任务有帮助,所以我们可以把这些潜在的意图给挖掘出来加以利用。
如何通过对话可以比较直接的挖掘到用户的兴趣点?
- 比如你想知道用户是男是女,我们可以通过问用户有没有男朋友来得到答案。这是一个很简单的问题,当被抛出来之后,用户也不觉得这个问题有多么的突兀,就是人跟人之间无意的对话,由于人类类似于一个复读机,每天会重复的聊比较相似的话题。
对于对话系统特别是闲聊式的对话系统,该如何衡量?
- 我们用CPS ( conversation per session ) 指标来衡量,也就是用户跟Chatbot聊天的turn数。这是一个相对来讲非常宏观的指标,并不能100%代表对话的质量,我们目前的平均值可以做到23。一般任务型的对话系统,基本2~3个turn可能就完成了。而且用户的粘性也不会特别好,用户有需求时,才会用一下。
站在我们的立场,turn数越多,可以挖掘到的有用信息越多,给用户推荐引导的机会就越多。
小冰也能做很多的task,只不过我们在对外宣传时,不会特意去提,我们觉得很多基本的Task是一个对话机器人的标配,如果一个产品有下界跟上界,这个下界就是做一些基本的task。
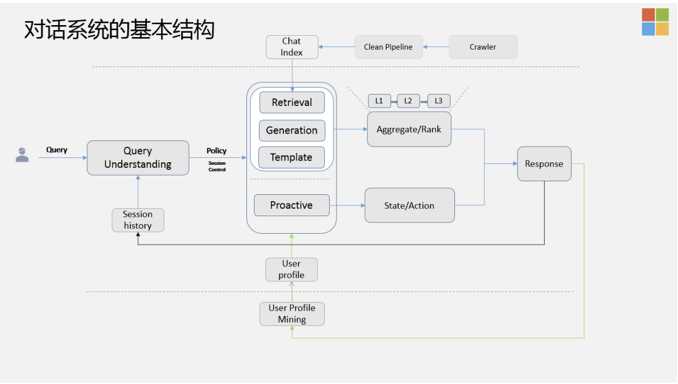
Query Understanding不仅仅分析当前的Query,还会从Session里提取Session History来做分析,生成两大类的Policy,一类是被动式的,一类是主动式的。
- 被动式的:指的是当前的Query比较有信息量,这时需要尽可能的引导这个话题往更有意义,更深入的方向上走,这里有三个模块:基于模板,基于检索,基于生成的方式来做的,然后对这三个模块整体上会做Aggregation Ranking,这里包含三层:召回,排序,还有Post Process ( 后处理 ),需要把很多违背常识/违背逻辑的答案去除。
- 主动式的 ( Proactive ):指抛出新的话题。对话系统不是一个简单的NLP问题,它还是一个非常复杂的系统工程,需要在没话题聊的时候,尽可能的把问题弄回来或者抛出新的话题。需要维护State,以及下一步的Action应该怎样去take。
用户画像挖掘模块!
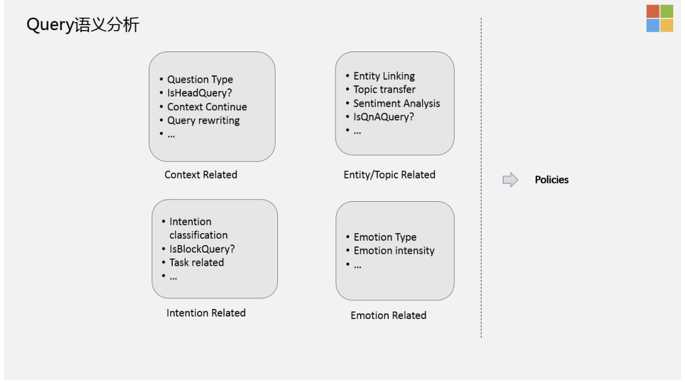
Query Understanding的四类信号
- 上下文相关的信号:包括query改写,上下文,是不是头部Query,是不是在聊,以及当前的Query类型,是简单的问题,还是复杂的问题。
- Entity相关的信号:这块大家都在做,特别提下Topic transfer,在对话中非常常见,因为对话的状态其实是一个open domain,是没有目标的,所以说有很大的概率会存在你在聊这个话题,机器人回答的是另外一个话题,然后用户再去顺着机器人的话题时,他又转移到另外一个话题上去了。所以,这里你需要有一个非常好的Transfer Detection模块,尽可能的把用户当前的topic 检测出来,以及做好话题生成、引导。我们内部有一个Graph叫做Topic Graph,跟业界提的KG有点类似,但又有点不同,我们是基于对话系统里面能聊的Topic本身来精心设计的。Topic之间就蕴含了我当前在聊A话题时,潜在其它话题的可能性。
- 意图相关的信号:在对话中,有很多潜在的意图,我们需要做意图分类,Task related等。
- 情绪相关的信号:包括情绪类型和情绪强度等。
基于上下文的Query改写
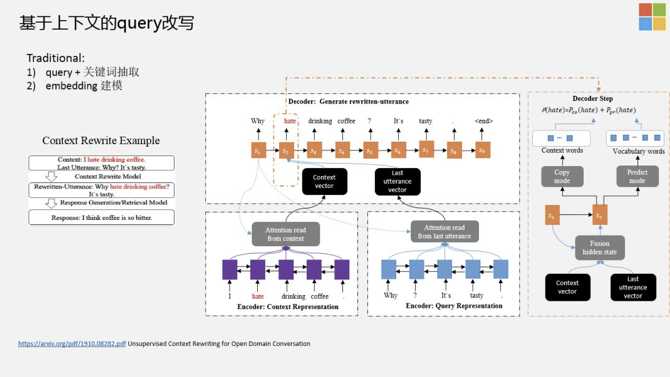
传统的基于上下文的query改写包括两种方式:
- 针对当前的query,把上下文的key word抽取出来,和当前的query做一个combine,combine可以放在前边、后边、中间,可以按照不同的方法组合出来。
- 通过sequence建模的方式,把上下文query放到统一的model中建模,得到vector,甚至可以叠加一个Hierarchical层,把整个句子的Embedding表示出来。
存在问题
- 由于生成模型会对序列产生很大影响,直接插入关键词是不科学的做法,比较简单粗暴;仅仅进行关键词抽取,可能会忽略掉一些信息,比如“否定”类的信息,就不会被挖掘到。
- Embedding建模的方式是一个系统工程,需要的计算资源非常大;如果整个句子过长,则起不到很好的建模作用。
Unsupervised Context Rewriting for Open Domain Conversation https://arxiv.org/abs/1910.08282



在小样本学习中,有一个比较经典的领域,就是Meta Learning,Meta Learning又分为:基于model based方法,metric based方法。基于Metric based中又有一种方法是基于原型的网络。

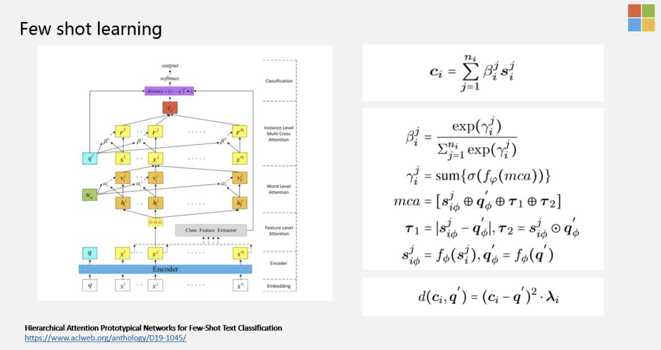
一个改进工作:Hierarchical Attention Prototypical Networks for Few-Shot Text Classification,https://www.aclweb.org/anthology/D19-1045/
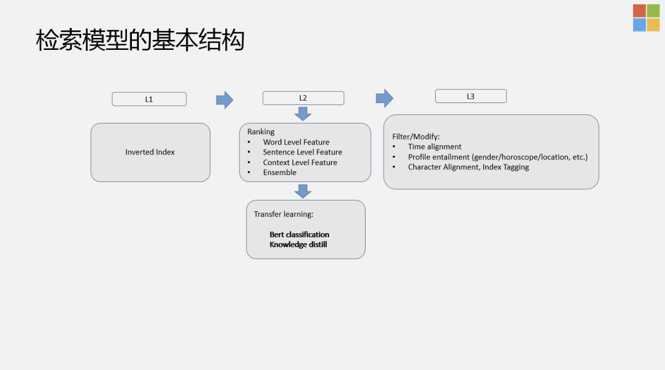

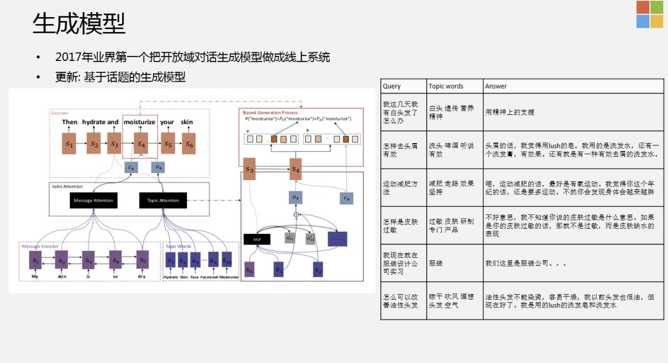
从系统整体的对话结构上来看,其实就是QA。但在QA中间,是存在一些策略的,也就是说,对当前的上下文,对用户来讲,机器人要不要引入一些新的话题。整个对话相当于是商检的过程,因为对话本身是无序的,如果回答的不好,就会东扯一下西扯一下。从商业的角度来讲,整个系统的稳定性不是特别好,用户聊了两句可能就走了,所以需要尽可能的获取对话的节奏。那么,有没有可能更显式的控制对话的节奏?
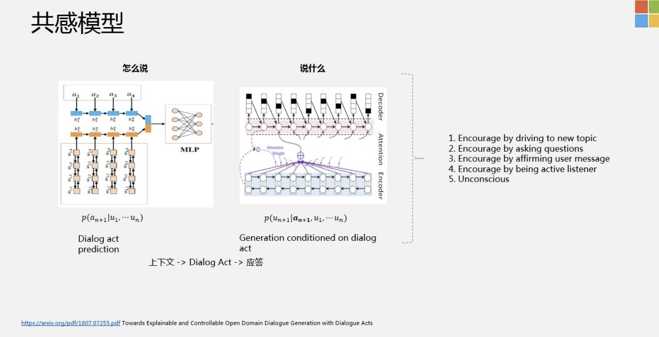
- Towards Explainable and Controllable Open Domain Dialogue Generation with Dialogue Acts,https://arxiv.org/pdf/1807.07255.pdf
- 我们引入了Dialogue Act概念,在这里,我们有比较宽泛的七大类的Act,比如我们是应该follow用户的问题,还是针对用户的问题,问一个新的问题,或者直接拒绝回答用户的问题,这是一大类。还有一大类,是发现当前的Session聊得不太好了,需要更多的引入新的话题,新的话题有可能是饭,也有可能是问题等等。通过这样的方式,我们可以比较好的建模对话的节奏。

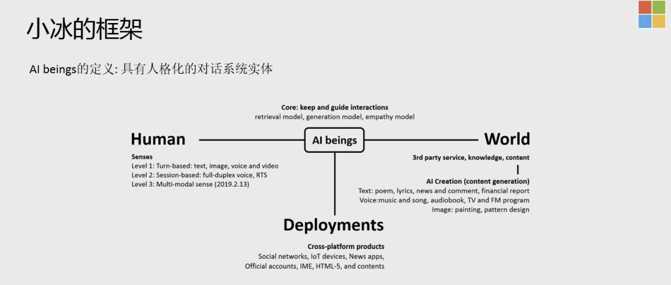

为什么人工智能在智能音箱上的价值不大?


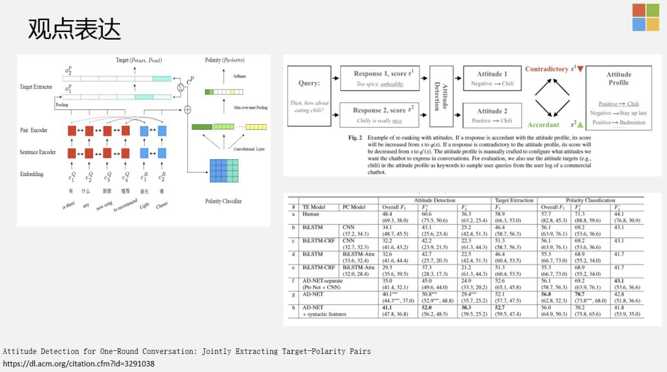
Attitude Detection for One-Round Conversation: Jointly Extracting Target-Polarity Pairs,https://dl.acm.org/citation.cfm?id=3291038
- 业界在做系统时,会把TAG提取和意图分开。特别是在做slot filling ( 槽位填充 ) 时,会先分意图,再做slot抽取。我们发现,如果把这两个工作组合在一起做,会有更好的效果提升。右上角是我们的一个做法,可以给她的观点根据不同的Entity,不同事物做设定,当有新的Response回来之后,会跟当前的设定做逻辑一致性校验,比如喜欢吃辣的或者不喜欢吃辣的,Response如果是吃火锅,对应的就是喜欢吃辣的,如果人设是不喜欢吃辣的,那么这种Response需要尽可能的去掉。
以上是关于《微软小冰:如何构建人格化的对话系统》,2020-03,曾敏的主要内容,如果未能解决你的问题,请参考以下文章