强化学习 --- 马尔科夫决策过程详解(MDP)
Posted jsfantasy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了强化学习 --- 马尔科夫决策过程详解(MDP)相关的知识,希望对你有一定的参考价值。
强化学习 --- 马尔科夫决策过程(MDP)
一、马尔科夫过程(Markov Process)
马尔科夫性某一状态信息包含了所有相关的历史,只要当前状态可知,所有的历史信息都不再需要,当前状态就可以决定未来,则认为该状态具有马尔科夫性
马尔科夫过程又叫做马尔科夫链(Markov Chain),它是一个无记忆的随机过程,可以用一个元组<S, P>表示,其中
S是有限数量的状态集 (S ={s_1, s_2, s_3, cdots, s_t})P是状态转移概率矩阵 (p(S_{t+1} = s‘|s_t=s) , 其中 s‘ 表示下一时刻的状态,s 表示当前状态)
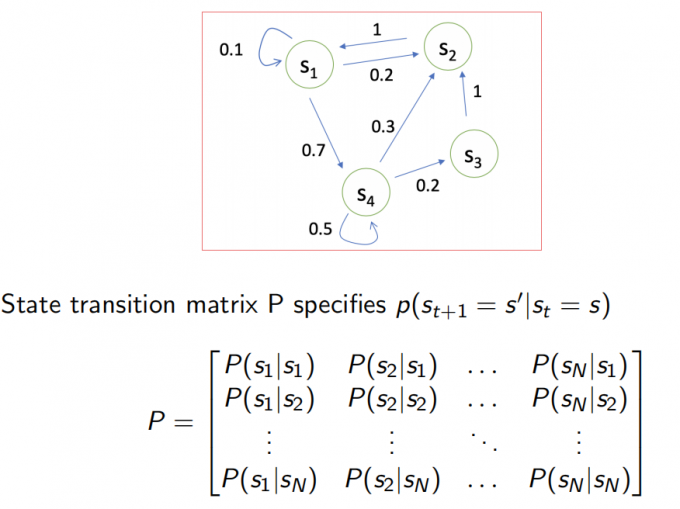
二、马尔科夫奖励过程(Markov Reward Process)
马尔科夫奖励过程是在马尔科夫过程基础上增加了奖励函数 (R) 和衰减系数 (gamma), 用 (<S, R,P, gamma>)表示
- (R) : 表示 (S) 状态下某一时刻的状态(S_t) 在下一个时刻 ((t + 1)) 能获得的奖励的期望
- (G_t) : 收获 (G_t)为在一个马尔科夫奖励链上从t时刻开始往后所有的奖励的有衰减的收益总和
- (gamma) : 折扣因子((Discount ; factor γ ∈ [0, 1]))
- 1、为了避免出现状态循环的情况
- 2、系统对于将来的预测并不一定都是准确的,所以要打折扣
- 很显然
越靠近1,考虑的利益越长远。
- (V(s)) : 状态价值函数(state value function) 表示从从该状态开始的马尔科夫链收获(G_t)的期望
- 例子:
- 奖励:(S_1) +5, (S_7) +10, 其余奖励为 0,则 (R = [5,0,0,0,0,0,10])
- (gamma = 0.5)
- $S_4, S_5, S_6, S_7: $ 0 + 0.5*0 + 0.5*0 + 0.125 *10 = 1.25
- (S_4,S_3,S_2,S_1) : 0 + 0.5 ×0 + 0.25×0 + 0.125×5 = 0.625
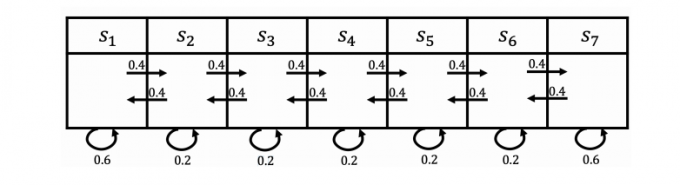
Bellman Equation 贝尔曼方程
(v(s) = E[G_t|S_t = s])
(= E[R_{t+1} + gamma R_{t+2} + gamma^2 R_{t+3} + cdots|S_t = s])
(= E[R_{t+1} + gamma(R_{t+2} + R_{t+3} + cdots)|S_t=s])
(=E[R_{t+1} + gamma v(S_{t+1})|S_t = s])
(=underbrace{E[R_{t+1}|S_t=s]}_{当前的奖励} + underbrace{gamma E[v(S_{t+1})|S_t = s]}_{下一时刻状态的价值期望})
使用贝尔曼方程状态价值(V)可以表示为:
- S 表示下一时刻的所有状态
- s‘ 表示下一时刻可能的状态
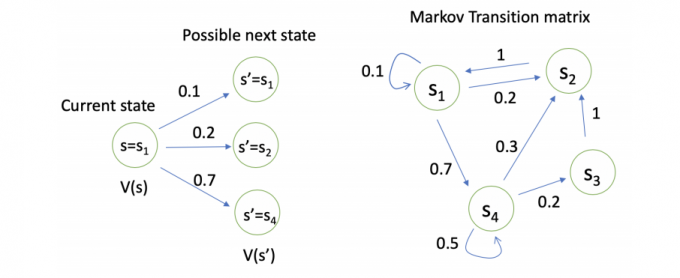
三、马尔科夫决策过程(Markov Decision Process)
马尔科夫决策过程是在马尔科夫奖励过程的基础上加了 Decision 过程,相当于多了一个动作集合,可以用 (<S, A, P, R, gamma>)
-
(A) 表示有限的行为集合
-
(S)表示有限的状态集合
-
(P^a) is dynamics / transition model for each action
- (P(s_{t+1} = s‘|s_t = s, a_t = a))
-
(R) 是奖励函数 (R(s_t=s, a_t = a) = E[R_t|s_t=s, a_t=a])
策略 (Policy)
- 用 (pi) 表示策略的集合,其元素 (pi(a|s)) 表示某一状态
s采取可能的行为a的概率
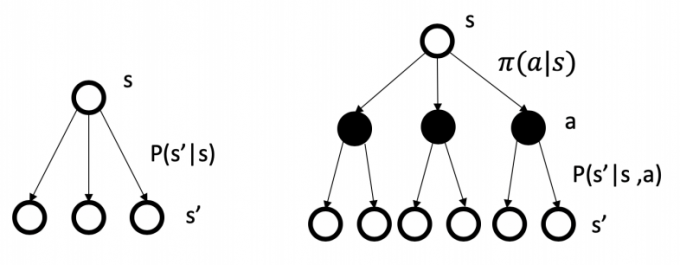
- 在马尔科夫奖励过程中 策略 (pi) 满足以下方程,可以参照下面图来理解
状态转移概率可以描述为:在执行策略 (pi) 时,状态从 s 转移至 s‘ 的概率等于执行该状态下所有行为的概率与对应行为能使状态从 s 转移至 s’ 的概率的乘积的和。参考下图
奖励函数可以描述为:在执行策略 (pi) 时获得的奖励等于执行该状态下所有行为的概率与对应行为产生的即时奖励的乘积的和。
我们引入策略,也可以理解为行动指南,更加规范的描述个体的行为,既然有了行动指南,我们要判断行动指南的价值,我们需要再引入基于策略的价值函数。
基于策略的状态价值函数(state value function)
- (V(s)) 表示从状态 (s) 开始,遵循当前策略时所获得的收获的期望
其中 (G_t) 可以参照马科夫奖励过程。我们有了价值衡量标准,如果状态 s 是一个好的状态,如何选择动作到达这个状态,这时就需要判断动作的好坏,衡量行为价值。
基于策略的行为价值函数(action value function)
- (q_{pi}(s,a))当前状态s执行某一具体行为a所能的到的收获的期望
- 根据 Bellman 公式推导可得(参照马尔科夫奖励过程中 V 的推导)
在某一个状态下采取某一个行为的价值,可以分为两部分:其一是离开这个状态的价值,其二是所有进入新的状态的价值于其转移概率乘积的和。参考下图右理解
- 由状态价值函数和行为价值函数的定义,可得两者的关系
我们知道策略就是用来描述各个不同状态下执行各个不同行为的概率,而状态价值是遵循当前策略时所获得的收获的期望,即状态 s 的价值体现为在该状态下遵循某一策略而采取所有可能行为的价值按行为发生概率的乘积求和。参照下图左理解
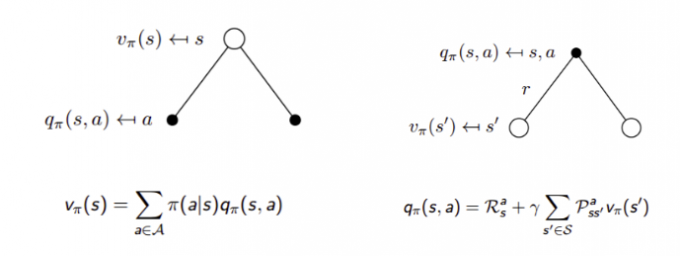
- 上面两个公式组合可得 Bellman Expectation Equation
实例
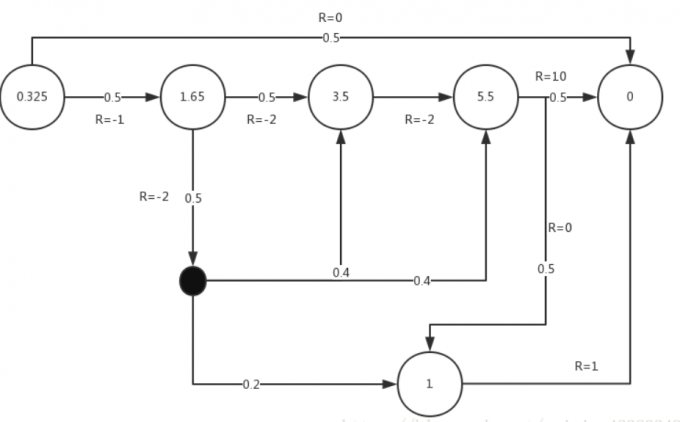
假设(gamma = 1)上图数字值为对于状态价值v(s),根据公式价值函数需要下一个状态的价值,终点的状态价值为0,利用递归的方式即可得到
-
5.5=0.5*(10+0)+0.5*(0+1*1)
-
1.65=0.5*(-2+0.4*3.5+0.4*5.5+0.2*1)+0.5*(-2+1*3.5)
五、Decision Making in MDP
可以把 Decision Making 分为两个过程
-
Prediction (评估给定的策略)
- 输入: MDP(<S, A, P, R, gamma>) 和 策略 $pi $
- 输出:value function (V_pi)
-
Control (寻找最优策略)
- 输入:MDP$<S, A, P, R, gamma> $
- 输出:最优的价值函数 (V^*) 和最优的策略 (pi^*)
1、Policy evaluation on MDP
Prediction 满足动态规划的条件:
- 贝尔曼等式可以递归分解
- value function 可以被存储和重用
Iteration on Bellman exception backup
我们可以用所有的状态 s 在 t 时刻的价值 (v_t(s‘)) 来更新 (v_{t+1}(s)) 时刻的价值,然后迭代下去
- 最优状态价值函数指的是在从所有策略产生的状态价值函数中,选取使状态s价值最大的函数:
- 最优的策略
- 对于任何MDP,下面几点成立:
- 1.存在一个最优策略,比任何其他策略更好或至少相等;
- 2.所有的最优策略有相同的最优价值函数;
- 3.所有的最优策略具有相同的行为价值函数。
根据以上几点,我们可以最大化最优行为价值函数找到最优策略
- 策略的个数为 (|A|^{|S|}) 个,对于状态比较多的环境,计算量太大
- 更加高效的方法是 policy iteration 和 value iteration
2、MDP Control
(1) Policy Iteration
- 分为两个部分
- Evaluate the policy $ pi $,(通过给定的 $ pi $ 计算 V)
- Improve the policy $ pi $,(通过贪心策略)
如果我们有 一个 策略 (pi),我们可以用策略 估计出它的状态价值函数 (v_pi(s)), 然后根据策略改进提取出更好的策略 (pi‘),接着再计算 (v_{pi‘}(s)), 然后再获得更好的 策略 (pi‘‘),直到相关满足相关终止条件。
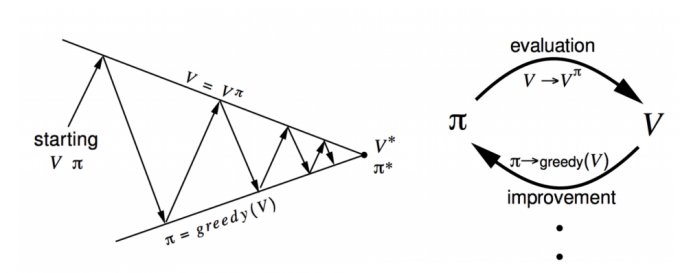
- 评估价值 (Evaluate)
- 如何改进策略(Improve)
- 可以把 (q^{pi_i}(s,a)) 想象成一个表格,其中横轴代表不同的状态,纵轴代表每种状态下不同的动作产生的价值,然后选择一个最大的行为价值作为当前的状态价值
- 当 improve 过程停止时,已经找到最佳策略
Bellman Optimality Equation
- 利用状态价值函数和动作价值函数之间的关系,得到
把上面两个式子结合起来有Bellman Optimality Equation

(2) Value Iteration
- 如果我们解决了子问题的 (V^*(s‘))
- 那么我们就可以通过反复迭代Bellman Optimality Equation找到 $ V^*(s) $
- 然后直接提取最优策略 $ pi $
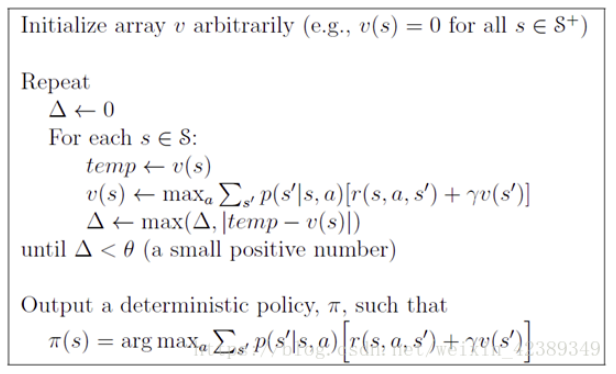
六 后记
关于直观的理解 Policy Iteration 和 Value Iteration 可以访问下面的网址
以上是关于强化学习 --- 马尔科夫决策过程详解(MDP)的主要内容,如果未能解决你的问题,请参考以下文章