量化交易——均值回归策略
Posted xiugeng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了量化交易——均值回归策略相关的知识,希望对你有一定的参考价值。
一、均值回归理论
均值回归:股票价格无论高于或低于价值中枢(或均值)都会以很高的概率向价值中枢回归的趋势。何时会发生均值回归,属于“随机漫步”范畴。
均值回归的理论基于以下观测:价格的波动一般会以它的均线为中心。即当标的价格由于波动而偏离移动的均线时,它将调整并重新归于均线。
偏离程度:(MA-P)/MA
1、均值回归原理
均值回归法则:万物最终都将回归于其长期的均值。
根据这个理论,一种上涨或者下跌的趋势不管其延续的时间多长都不能永远持续下去,最终均值回归的规律一定会出现:涨得太多了,就会向平均值移动下跌;跌得太多了,就会向平均值移动上升。
与趋势跟踪赌趋势的继续不同,均值回归则是赌趋势的反转。巴菲特的逆向投资策略,索罗斯的反身理论,其本质都是均值回归理论的应用,所不同的是前者是价值低估的投资,后者则是泡沫破灭的投机。
均值回归理论在一定程度上或一定范围内对股票价格进行预测,对于长线投资者具有重要指导意义。
到目前为止,均值回归理论仍不能解决的或者说不能预测的是回归的时间间隔,即回归的周期呈 " 随机漫步 "。不同的股票市场,回归的周期会不一样,就是对同一个股票市场来说,每次回归的周期也不一样。
2、均值回归策略(选股)
每个调仓日进行。
- 计算股票池中所有股票的N日均线;
- 计算股票池中所有股票和均线的偏离度;
- 选取偏离度最高的M只股票并调仓。
二、均值回归实现
# 初始化函数,设定基准等等 def initialize(context): # 设定沪深300作为基准 set_benchmark(‘000300.XSHG‘) # 开启动态复权模式(真实价格) set_option(‘use_real_price‘, True) # 输出内容到日志 log.info() log.info(‘初始函数开始运行且全局只运行一次‘) # 股票类每笔交易时的手续费是:买入时佣金万分之三,卖出时佣金万分之三加千分之一印花税, 每笔交易佣金最低扣5块钱 set_order_cost(OrderCost(close_tax=0.001, open_commission=0.0003, close_commission=0.0003, min_commission=5), type=‘stock‘) # 获取指数成份股 g.security = get_index_stocks(‘000300.XSHG‘) # print(g.security) # [‘000001.XSHE‘, ‘000002.XSHE‘, ‘000063.XSHE‘...‘603986.XSHG‘, ‘603993.XSHG‘] g.ma_days = 30 # 30天均值 g.stock_num = 10 # 持仓10只股票 run_monthly(handle, 1) # 第一个参数是对应的函数,第二个参数指第几个交易日 def handle(context): # pandas的Series对象:能够保存任何类型的数据(整数,字符串,浮点数,Python对象等)的一维标记数组 # Series参数——index索引:索引值必须是唯一的和散列的,与数据的长度相同 sr = pd.Series(index=g.security) # 索引设置为沪深300股票代码 # 遍历股票代码 for stock in sr.index: # attribute_history获取历史数据:参数设置股票代码、单位时间长度 ma = attribute_history(stock, g.ma_days)[‘close‘].mean() # 选取close这一列求平均,获取30日均值 # 这只股票今天开盘价 # get_current_data: 获取当前时间数据 p = get_current_data()[stock].day_open # 股票到均线的偏离程度 ratio = (ma - p) / ma sr[stock] = ratio # 选出偏离程度最大的十个 # pandas.DataFrame.nlargest:返回按列降序排列的前n行 to_hold = sr.nlargest(g.stock_num).index.values # print(to_hold) for stock in context.portfolio.positions: if stock not in to_hold: # 目标股数下单,卖出非标的的股票 order_target(stock, 0) # 期待持有且还未持仓的股票 to_buy = [stock for stock in to_hold if stock not in context.portfolio.positions] if len(to_buy) > 0: # 需要调仓 # 每只股票预计投入的资金 cash_per_stock = context.portfolio.available_cash / len(to_buy) for stock in to_buy: # 按价值下单,买入需买入的股票 order_value(stock, cash_per_stock)
执行显示效果:
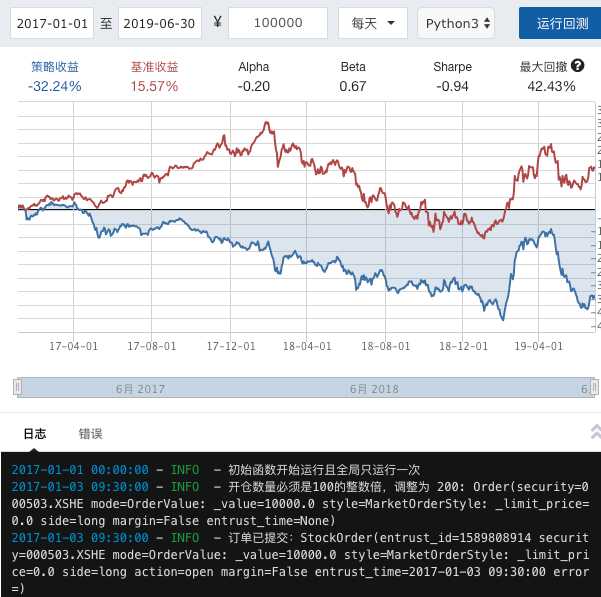
1、计算出均线、股价、偏离度
def handle(context): # pandas的Series对象:能够保存任何类型的数据(整数,字符串,浮点数,Python对象等)的一维标记数组 # Series参数——index索引:索引值必须是唯一的和散列的,与数据的长度相同 sr = pd.Series(index=g.security) # 索引设置为沪深300股票代码 # 遍历股票代码 for stock in sr.index: # attribute_history获取历史数据:参数设置股票代码、单位时间长度 ma = attribute_history(stock, g.ma_days)[‘close‘].mean() # 选取close这一列求平均,获取30日均值 # 这只股票今天开盘价 # get_current_data: 获取当前时间数据 p = get_current_data()[stock].day_open # 股票到均线的偏离程度 ratio = (ma - p) / ma sr[stock] = ratio
偏离程度计算:(MA-P)/MA
2、找到偏离度最高的股票
DataFrame.nlargest(self,n,columns,keep =‘first‘ )
pandas.DataFrame.nlargest():返回按列降序排列的前n行。以降序返回column中具有最大值的前n行。未指定的列也将返回,但不用于排序。
此方法等效于 如下方法,但性能更高:
df.sort_values(columns, ascending=False).head(n)
选出偏离度最大的十只股票:
def handle(context): # pandas的Series对象:能够保存任何类型的数据(整数,字符串,浮点数,Python对象等)的一维标记数组 # Series参数——index索引:索引值必须是唯一的和散列的,与数据的长度相同 sr = pd.Series(index=g.security) # 索引设置为沪深300股票代码 # 遍历股票代码 for stock in sr.index: # attribute_history获取历史数据:参数设置股票代码、单位时间长度 ma = attribute_history(stock, g.ma_days)[‘close‘].mean() # 选取close这一列求平均,获取30日均值 # 这只股票今天开盘价 # get_current_data: 获取当前时间数据 p = get_current_data()[stock].day_open # 股票到均线的偏离程度 ratio = (ma - p) / ma sr[stock] = ratio # 选出偏离程度最大的十个 # pandas.DataFrame.nlargest:返回按列降序排列的前n行 to_hold = sr.nlargest(g.stock_num).index print(to_hold)
执行显示效果:
2019-01-02 09:30:00 - INFO - Index([‘002252.XSHE‘, ‘600518.XSHG‘, ‘300003.XSHE‘, ‘600703.XSHG‘, ‘002450.XSHE‘, ‘002555.XSHE‘, ‘002310.XSHE‘, ‘600157.XSHG‘, ‘603986.XSHG‘, ‘002456.XSHE‘], dtype=‘object‘) 2019-02-01 09:30:00 - INFO - Index([‘002450.XSHE‘, ‘600518.XSHG‘, ‘300072.XSHE‘, ‘002252.XSHE‘, ‘300296.XSHE‘, ‘600100.XSHG‘, ‘600867.XSHG‘, ‘002310.XSHE‘, ‘600703.XSHG‘, ‘002460.XSHE‘], dtype=‘object‘)
可以看到返回的是一个Index对象。
3、将得到的对象转为数组
pandas.Index.values返回Index对象中数据的数组。
def handle(context): # pandas的Series对象:能够保存任何类型的数据(整数,字符串,浮点数,Python对象等)的一维标记数组 # Series参数——index索引:索引值必须是唯一的和散列的,与数据的长度相同 sr = pd.Series(index=g.security) # 索引设置为沪深300股票代码 # 遍历股票代码 for stock in sr.index: # attribute_history获取历史数据:参数设置股票代码、单位时间长度 ma = attribute_history(stock, g.ma_days)[‘close‘].mean() # 选取close这一列求平均,获取30日均值 # 这只股票今天开盘价 # get_current_data: 获取当前时间数据 p = get_current_data()[stock].day_open # 股票到均线的偏离程度 ratio = (ma - p) / ma sr[stock] = ratio # 选出偏离程度最大的十个 # pandas.DataFrame.nlargest:返回按列降序排列的前n行 to_hold = sr.nlargest(g.stock_num).index.values print(to_hold)
执行显示:
2019-01-02 09:30:00 - INFO - [002252.XSHE 600518.XSHG 300003.XSHE 600703.XSHG 002450.XSHE 002555.XSHE 002310.XSHE 600157.XSHG 603986.XSHG 002456.XSHE] 2019-02-01 09:30:00 - INFO - [002450.XSHE 600518.XSHG 300072.XSHE 002252.XSHE 300296.XSHE 600100.XSHG 600867.XSHG 002310.XSHE 600703.XSHG 002460.XSHE]
均值回归也可以作为一个因子加入多因子选股策略!
以上是关于量化交易——均值回归策略的主要内容,如果未能解决你的问题,请参考以下文章
QMT策略编写如何优雅地调教QMT量化平台编写量化策略(使用notepad++pycharmvscode等外部IDE编写量化交易代码)