分布式锁实现的三种方式
Posted riversdrift
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式锁实现的三种方式相关的知识,希望对你有一定的参考价值。
日常工作中很多场景下需要用到分布式锁,例如:任务运行(多个节点同一时刻同一个任务只能在一个节点上运行(分片任务除外)),交易请求接收(前端交易请求发送时,可能由于两次提交,后端需要识别出这是一个交易)等,怎么样实现一个分布式锁呢?一般有:zookeeper、redis、database等三种实现方式。
二、分布式锁实现
2.1、zookeeper
2.1.1、原理
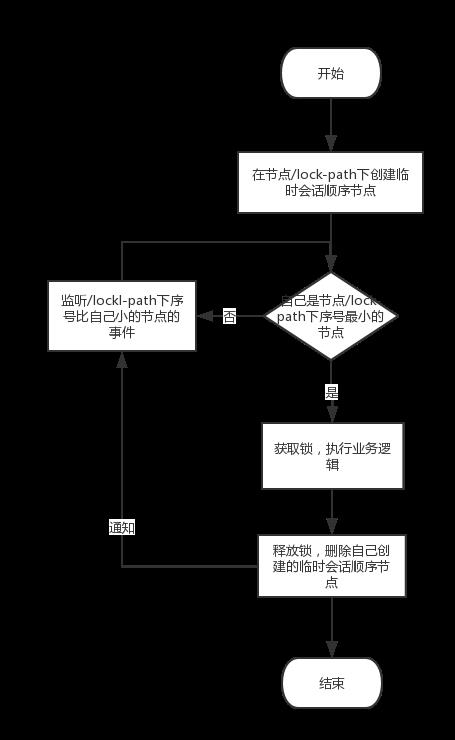
zookeeper实现分布式锁的原理就是多个节点同时在一个指定的节点下面创建临时会话顺序节点,谁创建的节点序号最小,谁就获得了锁,并且其他节点就会监听序号比自己小的节点,一旦序号比自己小的节点被删除了,其他节点就会得到相应的事件,然后查看自己是否为序号最小的节点,如果是,则获取锁。流程如下:
2.1.2、代码实现
应用依赖:
<dependencies>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.13</version>
<scope>compile</scope>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.0.0</version>
</dependency>
</dependencies>客户端注入:
@Configuration
public class CuratorBean {
@Bean
public CuratorFramework curatorFramework() {
RetryPolicy retryPolicy = new RetryNTimes(3, 1000);
CuratorFramework client = CuratorFrameworkFactory.newClient("localhost:2181", retryPolicy);
return client;
}
}具体实现:
package com.iwill.zookeeper.service;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.recipes.locks.InterProcessMutex;
import org.apache.curator.utils.CloseableUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.DisposableBean;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.concurrent.TimeUnit;
@Service
public class CuratorClient implements InitializingBean, DisposableBean {
@Autowired
private CuratorFramework client;
private final Logger logger = LoggerFactory.getLogger(this.getClass());
public void execute(String lockPath, BusinessService businessService) throws Exception {
InterProcessMutex lock = new InterProcessMutex(client, lockPath);
try {
boolean acquireLockSuccess = lock.acquire(200, TimeUnit.MILLISECONDS);
if (!acquireLockSuccess) {
logger.warn("acquire lock fail , thread id : " + Thread.currentThread().getId());
return;
}
logger.info("acquire lock success ,thread id : " + Thread.currentThread().getId());
businessService.handle();
} catch (Exception exp) {
logger.error("execute throw exp", exp);
} finally {
if (lock.isOwnedByCurrentThread()) {
lock.release();
}
}
}
/**
* Invoked by a BeanFactory on destruction of a singleton.
*
* @throws Exception in case of shutdown errors.
* Exceptions will get logged but not rethrown to allow
* other beans to release their resources too.
*/
@Override
public void destroy() throws Exception {
CloseableUtils.closeQuietly(client);
}
/**
* Invoked by a BeanFactory after it has set all bean properties supplied
* (and satisfied BeanFactoryAware and ApplicationContextAware).
* <p>This method allows the bean instance to perform initialization only
* possible when all bean properties have been set and to throw an
* exception in the event of misconfiguration.
*
* @throws Exception in the event of misconfiguration (such
* as failure to set an essential property) or if initialization fails.
*/
@Override
public void afterPropertiesSet() throws Exception {
client.start();
}
}
2.1.3、扩展分析
会话的建立与关闭:
在client.start调用后,就会创建与zookeeper服务器之间的会话链接。进入到client.start里面查看到代码如下:
@Override
public void start()
{
log.info("Starting");
if ( !state.compareAndSet(CuratorFrameworkState.LATENT, CuratorFrameworkState.STARTED) )
{
throw new IllegalStateException("Cannot be started more than once");
}
try
{
connectionStateManager.start(); // ordering dependency - must be called before client.start()
final ConnectionStateListener listener = new ConnectionStateListener()
{
@Override
public void stateChanged(CuratorFramework client, ConnectionState newState)
{
if ( ConnectionState.CONNECTED == newState || ConnectionState.RECONNECTED == newState )
{
logAsErrorConnectionErrors.set(true);
}
}
};
this.getConnectionStateListenable().addListener(listener);
client.start();
executorService = Executors.newSingleThreadScheduledExecutor(threadFactory);
executorService.submit(new Callable<Object>()
{
@Override
public Object call() throws Exception
{
backgroundOperationsLoop();
return null;
}
});
if ( ensembleTracker != null )
{
ensembleTracker.start();
}
log.info(schemaSet.toDocumentation());
}
catch ( Exception e )
{
ThreadUtils.checkInterrupted(e);
handleBackgroundOperationException(null, e);
}
}系统启动部分日志如下:
系统关闭时,系统的日志:
![]()
系统启动时zookeeper的日志:

系统关闭时zookeeper的日志:

由此可知,应用在启动的时候(client.start方法执行的时候)zookeeper客户端就会和zookeeper服务器时间建立会话,系统关闭时,客户端与zookeeper服务器的会话就关闭了。
节点创建:
跟踪lock.acquire(200, TimeUnit.MILLISECONDS)进入到org.apache.curator.framework.recipes.locks.StandardLockInternalsDriver#createsTheLock,代码如下:
@Override
public String createsTheLock(CuratorFramework client, String path, byte[] lockNodeBytes) throws Exception
{
String ourPath;
if ( lockNodeBytes != null )
{
ourPath = client.create().creatingParentContainersIfNeeded().withProtection().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath(path, lockNodeBytes);
}
else
{
ourPath = client.create().creatingParentContainersIfNeeded().withProtection().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath(path);
}
return ourPath;
}可以看到,创建的节点为临时会话顺序节点(EPHEMERAL_SEQUENTIAL),该节点的说明如下:
/**
* The znode will be deleted upon the client‘s disconnect, and its name
* will be appended with a monotonically increasing number.
*/即该节点会在客户端链接断开时被删除,还有,我们调用org.apache.curator.framework.recipes.locks.InterProcessMutex#release时也会删除该节点。
可重入性:
跟踪获取锁的代码进入到org.apache.curator.framework.recipes.locks.InterProcessMutex#internalLock,代码如下:
private boolean internalLock(long time, TimeUnit unit) throws Exception
{
/*
Note on concurrency: a given lockData instance
can be only acted on by a single thread so locking isn‘t necessary
*/
Thread currentThread = Thread.currentThread();
LockData lockData = threadData.get(currentThread);
if ( lockData != null )
{
// re-entering
lockData.lockCount.incrementAndGet();
return true;
}
String lockPath = internals.attemptLock(time, unit, getLockNodeBytes());
if ( lockPath != null )
{
LockData newLockData = new LockData(currentThread, lockPath);
threadData.put(currentThread, newLockData);
return true;
}
return false;
}可以看见zookeeper的锁是可重入的,即同一个线程可以多次获取锁,只有第一次真正的去创建临时会话顺序节点,后面的获取锁都是对重入次数加1。相应的,在释放锁的时候,前面都是对锁的重入次数减1,只有最后一次才是真正的去删除节点。代码见:
@Override
public void release() throws Exception
{
/*
Note on concurrency: a given lockData instance
can be only acted on by a single thread so locking isn‘t necessary
*/
Thread currentThread = Thread.currentThread();
LockData lockData = threadData.get(currentThread);
if ( lockData == null )
{
throw new IllegalMonitorStateException("You do not own the lock: " + basePath);
}
int newLockCount = lockData.lockCount.decrementAndGet();
if ( newLockCount > 0 )
{
return;
}
if ( newLockCount < 0 )
{
throw new IllegalMonitorStateException("Lock count has gone negative for lock: " + basePath);
}
try
{
internals.releaseLock(lockData.lockPath);
}
finally
{
threadData.remove(currentThread);
}
}多线程并发获取同一个锁时,服务端的数据结构如下:
[zk: localhost:2181(CONNECTED) 9] ls /lock-path
[_c_c38d1220-26d5-4001-9f20-5bc447f37229-lock-0000000104, _c_a2ced468-86f2-466e-bf38-0432350b65f2-lock-0000000103]
[zk: localhost:2181(CONNECTED) 10]释放锁时,会删除_c_c38d1220-26d5-4001-9f20-5bc447f37229-lock-0000000104和_c_a2ced468-86f2-466e-bf38-0432350b65f2-lock-0000000103这样的临时会话顺序节点,但是它们的父节点/lock-path不会被删除。因此,高并发的业务场景下使用zookeeper分布式锁时,会留下很多的空节点。
客户端故障检测:
正常情况下,客户端会在会话的有效期内,向服务器端发送PING 请求,来进行心跳检查,说明自己还是存活的。服务器端接收到客户端的请求后,会进行对应的客户端的会话激活,会话激活就会延长该会话的存活期。如果有会话一直没有激活,那么说明该客户端出问题了,服务器端的会话超时检测任务就会检查出那些一直没有被激活的与客户端的会话,然后进行清理,清理中有一步就是删除临时会话节点(包括临时会话顺序节点)(参见《从paxos到zookeeper分布式一致性原理与实践》“会话”一节)。这就保证了zookeeper分布锁的容错性,不会因为客户端的意外退出,导致锁一直不释放,其他客户端获取不到锁。
数据一致性:
zookeeper服务器集群一般由一个leader节点和其他的follower节点组成,数据的读写都是在leader节点上进行。当一个写请求过来时,leader节点会发起一个proposal,待大多数follower节点都返回ack之后,再发起commit,待大多数follower节点都对这个proposal进行commit了,leader才会对客户端返回请求成功;如果之后leader挂掉了,那么由于zookeeper集群的leader选举算法采用zab协议保证数据最新的follower节点当选为新的leader,所以,新的leader节点上都会有原来leader节点上提交的所有数据。这样就保证了客户端请求数据的一致性了。
CAP:
任何分布式架构都不能同时满足C(一致性)、A(可用性)、P(分区耐受性),因此,zookeeper集群在保证一致性的同时,在A和P之间做了取舍,最终选择了P,因此可用性差一点。参考:https://juejin.im/post/5afe4f285188251b8015e4b6
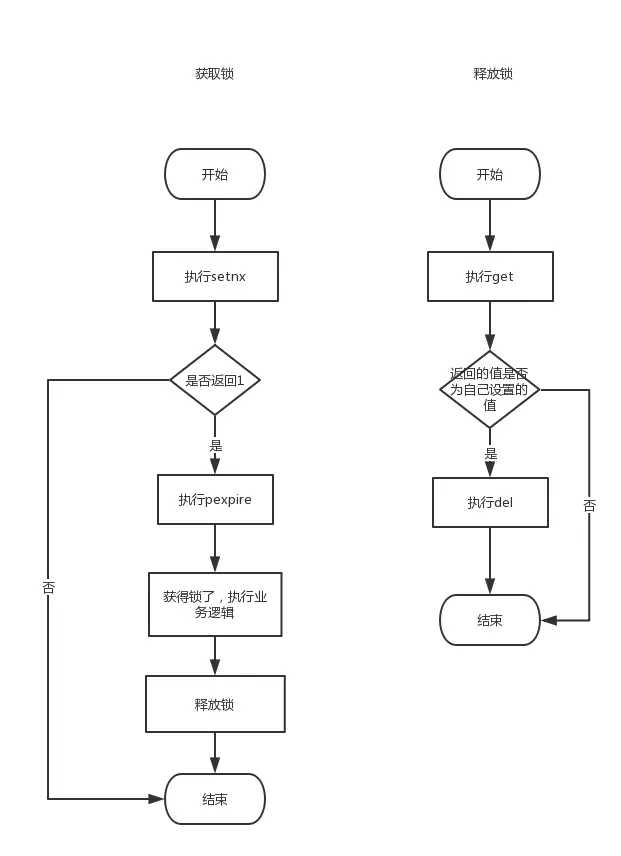
redis实现分布式锁的步骤:
2.2.2、代码实现
项目依赖:
<dependencies>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
</dependencies>注入bean:
@Configuration
public class JedisBean {
@Bean
public Jedis jedis(){
Jedis jedis = new Jedis("redis://127.0.0.1:6379");
return jedis ;
}
}获取锁的代码:
lua脚本:
private static String lockScript = "local key = KEYS[1]
"
+ "local value = ARGV[1]
"
+ "local expireTime = ARGV[2]
"
+ "
"
+ "if (redis.call(‘setnx‘,key,value) == 1) then
"
+ " redis.call(‘pexpire‘ , key , expireTime)
"
+ " return ‘true‘
"
+ "else
"
+ " return ‘false‘
"
+ "end
";对应的java代码:
/**
* 可重入的获取锁
* 使用lua脚本来保证setnx和pexpire是一个原子操作
* 获取锁成功后,里面启动过期续约任务
*
* @param key
* @param expireTime
* @return
*/
public boolean acquire(String key, long expireTime) {
Thread currentThread = Thread.currentThread();
LockData lockData = threadData.get(currentThread);
if (lockData != null) {
lockData.lockCount.incrementAndGet();
return true;
}
if (lockScriptSHA == null) {
lockScriptSHA = client.scriptLoad(lockScript);
}
String owner = generatorOwner();
boolean acquired = false;
try {
Object result = client.evalsha(lockScriptSHA, 1, key, owner, String.valueOf(expireTime));
acquired = Boolean.valueOf((String) result);
} catch (Exception exp) {
logger.error("execute eval sha throw exp", exp);
}
if (acquired) {
startExtendExpireTimeTask(key, owner, expireTime);
lockData = new LockData(currentThread, key, owner);
threadData.put(currentThread, lockData);
return true;
}
return false;
}这里采用和zookeeper分布式锁可重入同样的方式,使得redis锁可重入。
租期延长:
由于redis没有zookeeper的会话机制来保证业务运行期间,该线程一直持有锁,而是使用redis的key的过期时间来保证,为了保证业务运行期间,一直持有锁,我们在这里人为的启用的一个任务来为获取的锁延长过期时间,以此来达到和zookeeper分布式锁同样的效果。实现如下:
lua脚本:
private static String extendExpireTimeScript = "local key = KEYS[1]
"
+ "local value = ARGV[1]
"
+ "local newExpireTime = ARGV[2]
"
+ "
"
+ "if (redis.call(‘get‘,key) == value) then
"
+ " redis.call(‘pexpire‘ , key ,newExpireTime)
"
+ " return ‘true‘
"
+ "else
"
+ " return ‘false‘
"
+ "end
";该脚本保证只有自己才能延长key的过期时间,其他线程则不能进行此操作。java代码如下:
/**
* 租期续约任务,在当前线程还运行的情况下,延长过期时间
*
* @param key
* @param owner
* @param expireTime
*/
private void startExtendExpireTimeTask(String key, String owner, long expireTime) {
if (extendExpireTimeScriptSHA == null) {
extendExpireTimeScriptSHA = client.scriptLoad(extendExpireTimeScript);
}
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
try {
Object result = client.evalsha(extendExpireTimeScriptSHA, 1, key, owner, String.valueOf(expireTime));
boolean extendSuccess = Boolean.valueOf((String) result);
if (!extendSuccess) {
timer.cancel();
}
} catch (Exception exp) {
timer.cancel();
}
}
}, 0, expireTime * 3 / 4);
}这里的续租方式会使得性能下降,如果同一个应用中,同时很多线程去获取锁,那么就会启动很多的timer线程,这会增加系统开销。还有续租时间严重依赖与锁过期时间,如果锁过期时间很短,某一时刻客户端与redis服务器之间的网络出现网络抖动了,就可能出现该业务没执行完(执行时间稍微大于锁过期时间),导致锁过期被删除了,其他客户端就获取锁了。前一个获取锁的线程就会在无锁条件下运行。
释放锁的实现如下:
lua脚本:
private static String unlockScript = "local key = KEYS[1]
"
+ "local value = ARGV[1]
"
+ "
"
+ "if (redis.call(‘get‘,key) == value) then
"
+ " redis.call(‘del‘ , key )
"
+ " return ‘true‘
"
+ "else
"
+ " return ‘false‘
"
+ "end
";该脚本保证只能获取锁的线程才可以删除该锁。对应的java实现如下:
/**
* 释放锁,获取多少次锁,就释放多少次锁
*
* @return
*/
public boolean release() {
Thread currentThread = Thread.currentThread();
LockData lockData = threadData.get(currentThread);
if (lockData == null) {
throw new RuntimeException("current thread do not own lock");
}
int newLockCount = lockData.lockCount.decrementAndGet();
if (newLockCount > 0) {
return true;
}
if (newLockCount < 0) {
throw new RuntimeException("Lock count has gone negative for lock :" + lockData.key);
}
if (unlockScriptSHA == null) {
unlockScriptSHA = client.scriptLoad(unlockScript);
}
try {
Object result = client.evalsha(unlockScriptSHA, 1, lockData.key, lockData.owner);
boolean unlocked = Boolean.valueOf((String) result);
if (!unlocked) {
logger.error(String.format("unlock fail ,key = %s", lockData.key));
}
} finally {
threadData.remove(currentThread);
}
return true;
}这里释放锁时,采用可重入的方式,同样借鉴于zookeeper分布式锁可重入的实现。
2.2.3、扩展分析
socket链接
redis客户端每次发送请求到服务器时,都与服务器之间建立一个socket来进行。分析如下:
跟踪代码Object result = client.evalsha(unlockScriptSHA, 1, lockData.key, lockData.owner)进入到redis.clients.jedis.Connection#connect,源码如下:
public void connect() {
if (!isConnected()) {
try {
socket = new Socket();
// ->@wjw_add
socket.setReuseAddress(true);
socket.setKeepAlive(true); // Will monitor the TCP connection is
// valid
socket.setTcpNoDelay(true); // Socket buffer Whetherclosed, to
// ensure timely delivery of data
socket.setSoLinger(true, 0); // Control calls close () method,
// the underlying socket is closed
// immediately
// <-@wjw_add
socket.connect(new InetSocketAddress(host, port), connectionTimeout);
socket.setSoTimeout(soTimeout);
if (ssl) {
if (null == sslSocketFactory) {
sslSocketFactory = (SSLSocketFactory)SSLSocketFactory.getDefault();
}
socket = (SSLSocket) sslSocketFactory.createSocket(socket, host, port, true);
if (null != sslParameters) {
((SSLSocket) socket).setSSLParameters(sslParameters);
}
if ((null != hostnameVerifier) &&
(!hostnameVerifier.verify(host, ((SSLSocket) socket).getSession()))) {
String message = String.format(
"The connection to ‘%s‘ failed ssl/tls hostname verification.", host);
throw new JedisConnectionException(message);
}
}
outputStream = new RedisOutputStream(socket.getOutputStream());
inputStream = new RedisInputStream(socket.getInputStream());
} catch (IOException ex) {
broken = true;
throw new JedisConnectionException(ex);
}
}
}调用client.close之后,就会关闭socket链接,代码如下:
public void disconnect() {
if (isConnected()) {
try {
outputStream.flush();
socket.close();
} catch (IOException ex) {
broken = true;
throw new JedisConnectionException(ex);
} finally {
IOUtils.closeQuietly(socket);
}
}
}一个系统中jedis与redis服务器端就建立一个链接,如果这个服务中使用redis的量很大,那么这里会是一个瓶颈,因此这时可以使用jedisPool(链接池)来优化。虽然客户端与服务器端有建立链接,但是redis服务器端不会根据链接有效性去给该链接设置的key来重新设置过期时间。因此,redis分布式锁需要客户端自己去延长过期时间或者在最开始设置过期时间的时候,设置一个足够长的过期时间来满足业务一直执行完,一直持有锁。
一致性:
redis集群中leader与slave之间的数据复制是采用异步的方式(因为需要满足高性能要求),即,leader将客户端发送的写请求记录下来后,就给客户端返回响应,后续该leader的slave节点就会从该leader节点复制数据。那么就会存在这么一种可能性:leader接收了客户端的写请求,也给客户端响应了,但是该数据还没来得及复制到它对应的slave节点中,leader就crash了,从slave节点中重新选举出来的leader也不包含之前leader最后写的数据了,这时,客户端来获取同样的锁就可以获取到,这样就会在同一时刻,两个客户端持有锁。
CAP:
redis的初衷是提供一个高性能的内存存储,对客户端的请求需要很快速的作出响应,因此,高性能是一个重要目标,如果要保证leader和slave之间的数据同步一致,就会牺牲性能。setinel和cluster都实现了高可用,也保证了P,因此redis保证了CAP中的AP。
公平竞争:
上述实现的redis分布式锁不具有获取失败排队等待的情况,因此不具有偏向性。任意时刻,都是竞争获取。
综上所属,redis分布式锁具有高并发、高可用的特性,但是,在极端情况下,存在一定的问题。redis官网提供的redlock在redisson中实现了,由于它需要在大多数节点中都获取同样的锁,因此相较于但节点的锁获取,性能会有所降低。
2.3、database
2.3.1、原理
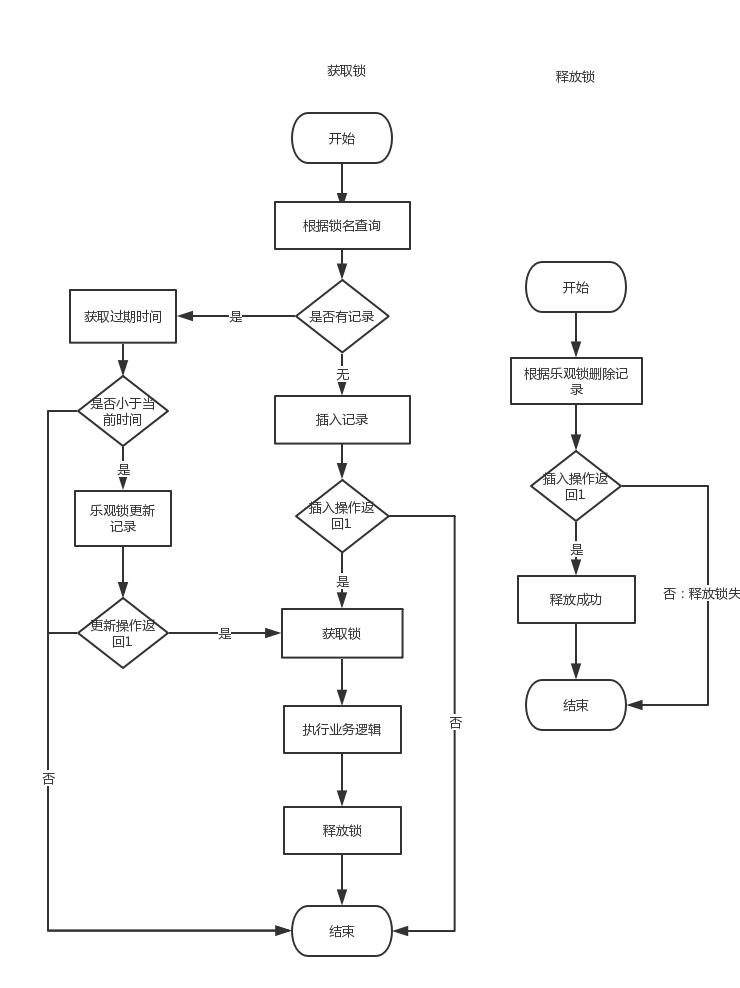
用数据库实现分布式锁的方式和redis分布式锁的实现方式类似,这里采用数据库表的唯一键的形式。如果同一个时刻,多个线程同时向一个表中插入同样的记录,由于唯一键的原因,只能有一个线程插入成功。流程图如下:
2.3.2、代码实现
表结构如下:
CREATE TABLE `lock_record` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT ‘主键‘,
`lock_name` varchar(50) DEFAULT NULL COMMENT ‘锁名称‘,
`expire_time` bigint(20) DEFAULT NULL COMMENT ‘过期时间‘,
`version` int(11) DEFAULT NULL COMMENT ‘版本号‘,
`lock_owner` varchar(100) DEFAULT NULL COMMENT ‘锁拥有者‘,
PRIMARY KEY (`id`),
UNIQUE KEY `lock_name` (`lock_name`)
)获取锁的代码如下:
/**
* @param lockName 锁名称
* @param lockTime 锁时间
* @return
*/
public boolean acquire(String lockName, Long lockTime) {
Thread currentThread = Thread.currentThread();
LockData lockData = threadData.get(currentThread);
if (lockData != null) {
lockData.lockCount.incrementAndGet();
return true;
}
LockRecordDTO lockRecord = lockRecordMapperExt.selectByLockName(lockName);
if (lockRecord == null) {
String lockOwner = generatorOwner();
boolean acquired = tryAcquire(lockName, lockTime, lockOwner);
if (acquired) {
startExtendExpireTimeTask(lockName, lockOwner, lockTime);
lockData = new LockData(currentThread, lockName, lockOwner);
threadData.put(currentThread, lockData);
}
return acquired;
}
long lockExpireTime = lockRecord.getExpireTime();
if (lockExpireTime < System.currentTimeMillis()) {
String lockOwner = generatorOwner();
boolean acquired = tryAcquire(lockRecord, lockTime, lockOwner);
if (acquired) {
lockData = new LockData(currentThread, lockName, lockOwner);
threadData.put(currentThread, lockData);
}
return acquired;
}
return false;
} /**
* 尝试获得锁,数据库表有设置唯一键约束,只有插入成功的线程才可以获取锁
*
* @param lockName 锁名称
* @param lockTime 锁的过期时间
* @param lockOwner 锁的拥有者
* @return
*/
private boolean tryAcquire(String lockName, long lockTime, String lockOwner) {
try {
LockRecordDTO lockRecord = new LockRecordDTO();
lockRecord.setLockName(lockName);
Long expireTime = System.currentTimeMillis() + lockTime;
lockRecord.setExpireTime(expireTime);
lockRecord.setLockOwner(lockOwner);
lockRecord.setVersion(0);
int insertCount = lockRecordMapperExt.insert(lockRecord);
return insertCount == 1;
} catch (Exception exp) {
return false;
}
} /**
* 当上一次获取锁的线程没有正确释放锁时,下一次其他线程获取锁时会调用本方法
* 当多个线程竞争获取锁时,有乐观锁控制,只有更新成功的线程才会获的锁
*
* @param lockRecord 锁记录,里面保存了上一次获取锁的拥有者信息
* @param lockTime 锁过期时间
* @param lockOwner 锁的拥有者
* @return
*/
private boolean tryAcquire(LockRecordDTO lockRecord, long lockTime, String lockOwner) {
try {
Long expireTime = System.currentTimeMillis() + lockTime;
lockRecord.setExpireTime(expireTime);
lockRecord.setLockOwner(lockOwner);
int updateCount = lockRecordMapperExt.updateExpireTime(lockRecord);
return updateCount == 1;
} catch (Exception exp) {
return false;
}
}对应乐观锁更新sql如下:
<update id="updateExpireTime" parameterType="com.iwill.db.model.LockRecordDTO">
update lock_record
set expire_time = #{expireTime},
version = version + 1
where lock_name = #{lockName} and version = #{version}
</update>获取锁时,如果数据库中有记录且超时时间小于当前时间,说明持有锁的客户端崩溃退出了,没有正确释放锁,才会导致表中有过期的记录。这时,并发的获取锁时,只有更新成功的线程才可以获取锁。
释放锁时,只有持有锁的线程才可以释放锁,代码如下:
/**
* 释放锁
* 实现参考zookeeper的锁释放机制
*/
public void release() {
Thread currentThread = Thread.currentThread();
LockData lockData = threadData.get(currentThread);
if (lockData == null) {
throw new RuntimeException("current thread do not own lock");
}
int newLockCount = lockData.lockCount.decrementAndGet();
if (newLockCount > 0) {
return;
}
if (newLockCount < 0) {
throw new RuntimeException("Lock count has gone negative for lock :" + lockData.lockName);
}
try {
lockRecordMapperExt.deleteByOwner(lockData.lockName, lockData.owner);
} finally {
threadData.remove(currentThread);
}
}对应的底层sql如下:
<delete id="deleteByOwner" parameterType="java.util.Map">
delete from lock_record where lock_name = #{lockName} and lock_owner = #{lockOwner}
</delete>2.3.3、扩展分析
数据库的方式实现分布式锁,存在一个明显的问题,就是单节点问题,这里可以通过主-备的形式来缓解,但是这样会引来数据不一致的问题。而且,数据库的方式在高并发的情况下会存在性能问题。
三、对比分析
3.1、zookeeper分布式锁实现简单,集群自己来保证数据一致性,但是会存在建立无用节点且多节点之间需要同步数据的问题,因此一般适合于并发量小的场景使用,例如定时任务的运行等。
3.2、redis分布式锁(非redlock)由于redis自己的高性能原因,会有很好的性能,但是极端情况下会存在两个客户端获取锁(可以通过监控leader故障和运维措施来缓解和解决该问题),因此适用于高并发的场景。
3.3、database分布式锁由于数据库本身的限制:性能不高且不满足高可用(即是存在备份,也会导致数据不一致),因此,工作中很难见到真正使用数据库来作为分布式锁的解决方案,这里使用数据库实现主要是为了理解分布式锁的实现原理。
关于zookeeper、redis、database实现分布式锁的对比可以参见:https://blog.csdn.net/zxp_cpinfo/article/details/53692922
以上是关于分布式锁实现的三种方式的主要内容,如果未能解决你的问题,请参考以下文章
分布式锁的三种实现方式(zookeepermemcachedredis)
分布式——补充的一些东西(就业相关的)秒杀的设计方案分布式id生成方案分布式锁分布式锁的三种实现方式(基于数据库RedisZookeeper)