基于OPGG的数据分析
Posted zcx-7
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于OPGG的数据分析相关的知识,希望对你有一定的参考价值。
最终代码
1 # _*_ coding:utf-8 _*_ 2 # from 坾尘 3 # 2020/5/09 4 from selenium import webdriver 5 import time 6 from bs4 import BeautifulSoup 7 import matplotlib.pyplot as plt 8 plt.rcParams[‘font.sans-serif‘] = [‘SimHei‘] 9 driver =webdriver.PhantomJS(executable_path="phantomjs.exe") 10 driver.get("http://www.op.gg/champion/statistics") 11 time.sleep(5) 12 file=open(‘opgggg.csv‘,‘w‘,encoding=‘utf-8‘) 13 demo=driver.page_source 14 soup=BeautifulSoup(demo,‘lxml‘) 15 16 b,f,c=[],[],[] 17 a=soup.find_all(name=[‘td‘],class_=[‘champion-index-table__cell champion-index-table__cell--champion‘]) 18 for i in a : 19 b.append(i.a.div.text) 20 d=soup.find_all(name=[‘td‘],class_=[‘champion-index-table__cell champion-index-table__cell--value‘]) 21 for i in d: 22 if i.text!=‘ ‘: 23 f.append(float(i.text.replace(‘%‘,‘‘))) 24 file.write(‘英雄名称‘+‘,‘+‘胜率‘+‘,‘+‘登场率‘+‘ ‘) 25 for i in range(len(b)): 26 file.write(str(b[i])+‘,‘+str(f[2*i-1])+‘,‘+str(f[2*i])+‘ ‘) 27 plt.ylim([45,55]) 28 plt.title(u"op英雄") 29 plt.ylabel(u"胜率%") 30 plt.xlabel(u"英雄") 31 plt.bar(b[:10],f[:20:2],width = 0.35,align=‘center‘,color = ‘c‘,alpha=0.8) 32 plt.show() 33 print(b) 34 print(f)
此次大作业,我选择爬取opgg上的数据,但是刚开始时有些困难,其原因在于opgg采用动态加载,直接使用requests库获取的源代码并不是最终呈现在用户面前的内容,我采取了selenium库模拟浏览器行为,并下载了PhantomJS,使用
driver.get("http://www.op.gg/champion/statistics") time.sleep(5)
与requests类似使用get,为确保加载完毕,引入time.sleep(5)
demo=driver.page_source
获取获得的内容
与之前类似使用BeautifulSoup进行处理
将所得数据传入csv文件,并取排名前十使用matplotlib绘图。
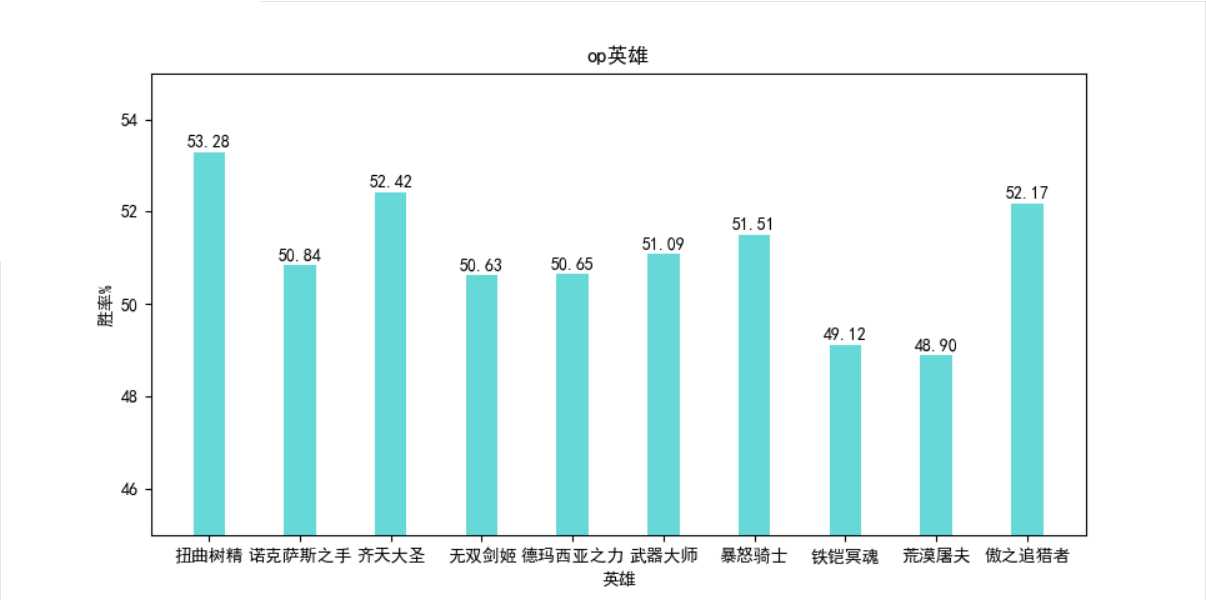
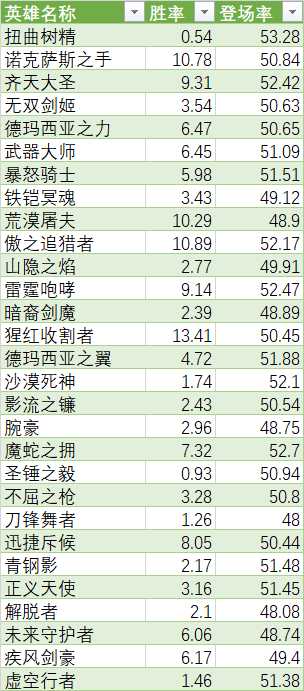
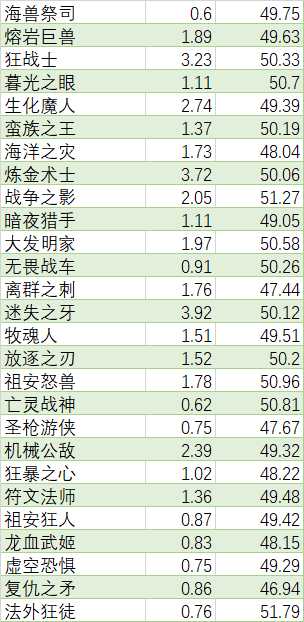
表格内容:
本来想在绘图中使用并列双y轴条形图,但调试一个小时都没弄好,出来的效果很糟糕
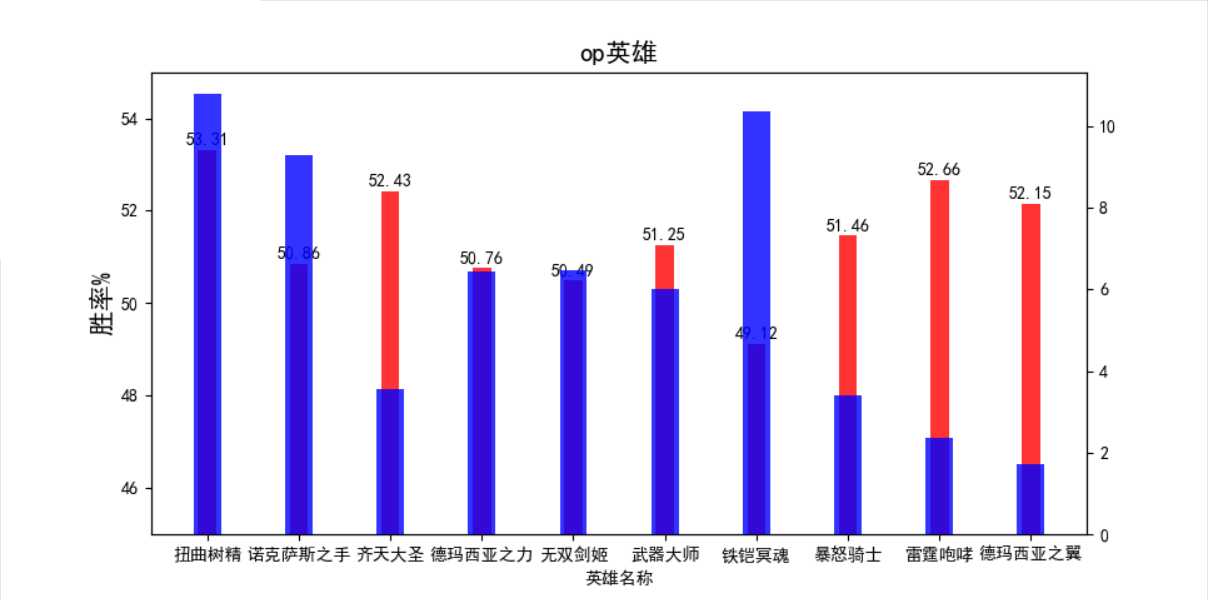
很遗憾没能做好。
以上是关于基于OPGG的数据分析的主要内容,如果未能解决你的问题,请参考以下文章