Es知识整理
Posted camouflage
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Es知识整理相关的知识,希望对你有一定的参考价值。
一、Es是如何实现分布式的
1.Es本身基于lucene,高度支持分布式的核心思想就在于,在多个服务器上启动多个Es进程实例,组建了一套Es集群。
2.其次,因为shard分片的应用,非常灵活的支持数据量横向扩展(只需要重建一个索引,多加shard,把数据迁进去)。再者说shard的数据其实是有多个备份,每个shard都会有一个primary shard,负责写数据,写入数据后,会将数据同步到其他的replica shard上。(ps : 主shard 和 复制shard 可以不在相同的服务器上,如果某个机器宕机了,别的机器上依然有数据备份)
3.Es集群会自动选举一个master节点, 负责一些管理工作(比如维护索引元数据、负责切换 primary shard 和 replica shard 身份等),如果master节点宕机了,会重新选举一个新的master。
4.非master节点宕机时,master节点会让宕机节点的primary shard 身份转移给其他节点。如果宕机节点修好了,那它也只能是replica shard了。(保证集群正常)。
二、Es 写数据操作
1.客户端随机选了一个节点1触发请求,该节点1成为 协调节点。
2.协调节点对这个写入的document进行路由,将数据发送给有primary shard的节点2。
3.节点2写数据,并将数据同步给所有的replica shard节点。
4.协调节点如果发现 primary shard 和 各 replica shard 都将数据搞定之后,响应客户端。
三、Es读数据操作
1.客户端随机选了一个节点1触发请求,该节点1成为 协调节点。
2.协调节点对请求过来的文档id进行hash路由,使用随机轮训算法(保证读数据负载均衡)从所有的primary shard 的node 和复制节点的node里挑一个节点2,将请求指给对应的节点2。
3.节点2将数据document 响应给协调节点1。
4.协调节点1 将数据响应给客户端。
四、Es搜索数据操作
1.客户端随机选了一个节点1触发请求,该节点1成为 协调节点。
2.协调节点将搜索的内容转发到所有的shard。
3.每个shard 将自己的搜索结果 其实也就是一些document_id。返回给协调节点1。协调节点进行合并、排序、分页等。
4.协调节点1根据每个shard发挥的document_id去各个节点上拉去实际的document数据,最终响应给客户端。
五、Es为什么快
首先要知道什么是倒排索引,引用大佬的图。
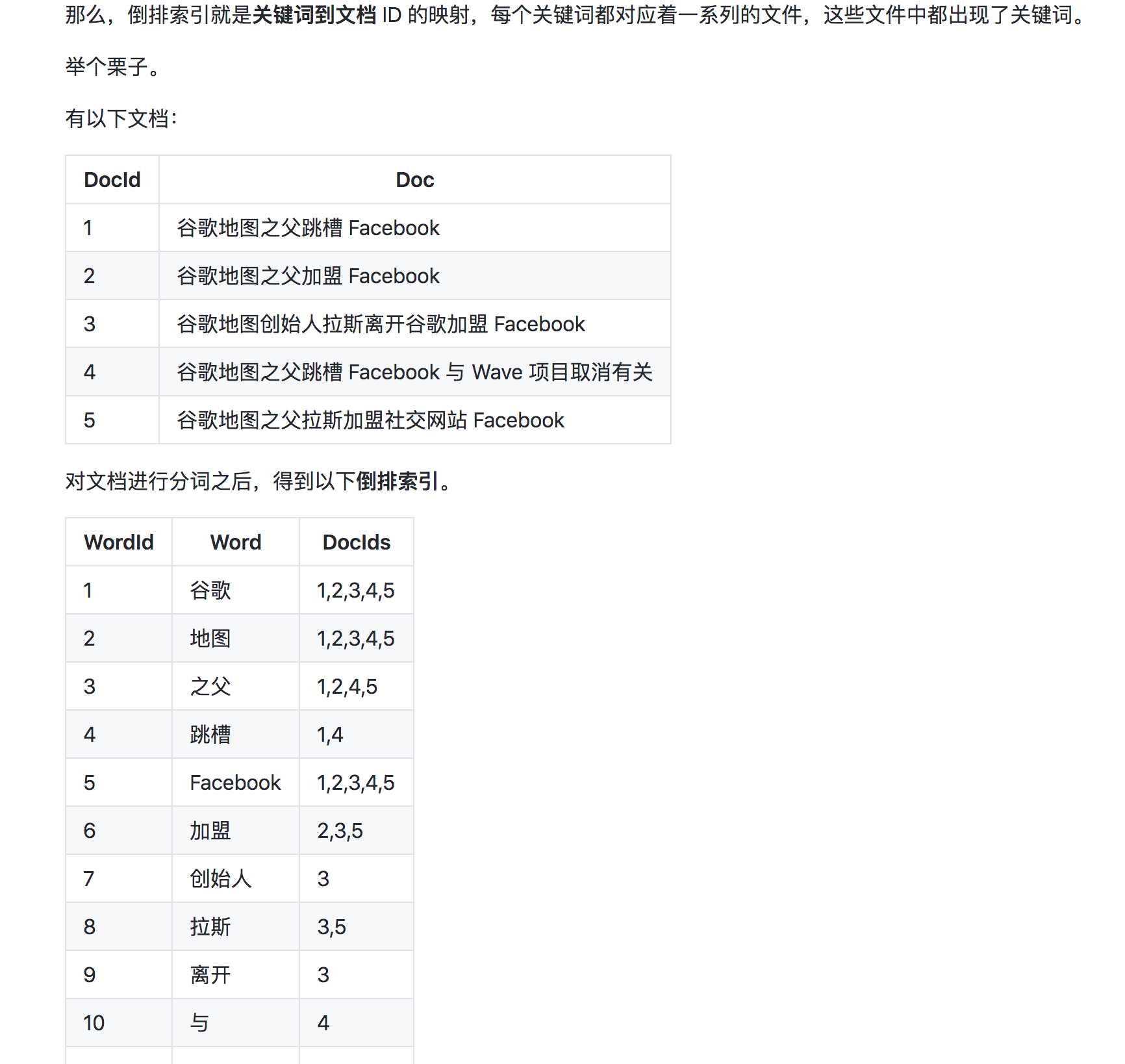
1.倒排索引就是关键词到文档id 多对多的一个映射关系。
着重注意两点:
a.倒排索引中的关键词词项本身就是有个生序排列的顺序的。
b.每个关键词在倒排所以里又直接对应着所有相关的document_id。
2.Es通过此项索引快速找到了倒排文件和trem。再通过倒排文件快速定位到具体的document。
以上是关于Es知识整理的主要内容,如果未能解决你的问题,请参考以下文章