用kettle做爬虫get请求爬取日期
Posted 10sxluo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用kettle做爬虫get请求爬取日期相关的知识,希望对你有一定的参考价值。
背景
接到一个任务,是爬取广东省采购网2019年全年的采购公告、合同信息、结果公告等信息。通过python代码的编写已经完成了这个任务。但由于采购网的服务器不是太稳定等因素,因此,相当一部分的数据行没有爬取到“公布日期”。
幸好,我的数据行里面已经存有每个数据的网址来历,只要直接get,就能获取该网页了。而我想起kettle里面也可以做简易的爬虫,因此,我利用kettle做了一个爬虫,将数据库内,公布日期为“0000-00-00”的错误数据,重新爬取入库。
附:广东省采购网网址:http://www.gdgpo.gov.cn/queryMoreInfoList.do
制作kettle转换
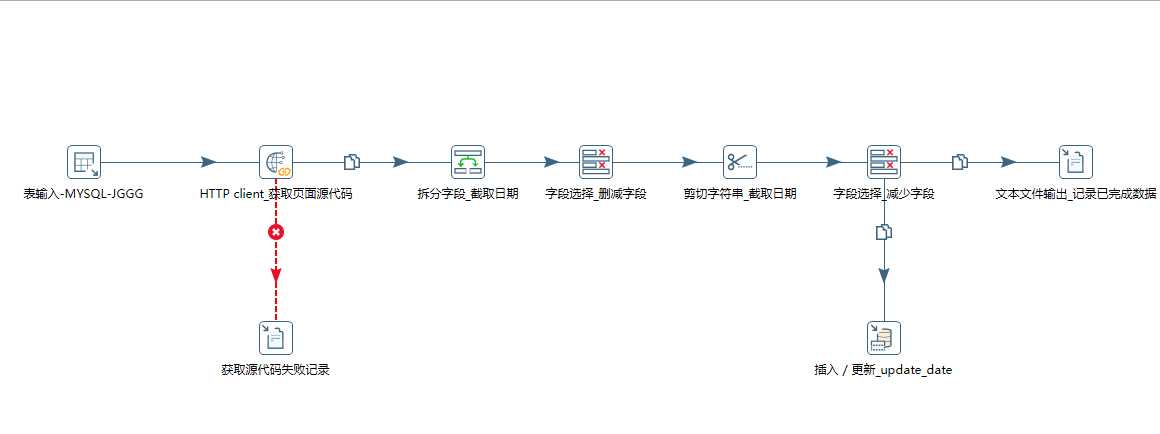
流程分别是:
1、读取url。
从库中读取结果公告表中PublishDate=‘0000-00-00‘的主键ID、url。
2、获取网页信息。
利用get请求获取页面信息。由于对方服务器不稳定,所以等待的时间要设置的比较长,而且给它设置了错误定义,将获取不到页面的url和id,暂且存到一个txt内,不影响整个流程跑。
3、文本处理和入库。
获取页面信息后(xml信息),本来我是打算用get data from xml来读取的,结果发现它的很多节点写的不规范,例如<link>少了</link>,<br>少了</br>,很多都没有结束符号。结果kettle就报错,我估计之前我用python爬,应该是这个语法的问题导致,我的beautifulsoup读不出来。无奈之下,我选择直接利用文本截取,更快更简洁。根据关键字“发布日期”去拆分文本。然后删掉拆分后产生的没用的字段。再利用剪切将日期的10位字符串剪出来。同理,删除新产生的不需要的字段。然后将更新记录写入数据库,和一个txt中作为记录。
处理结果
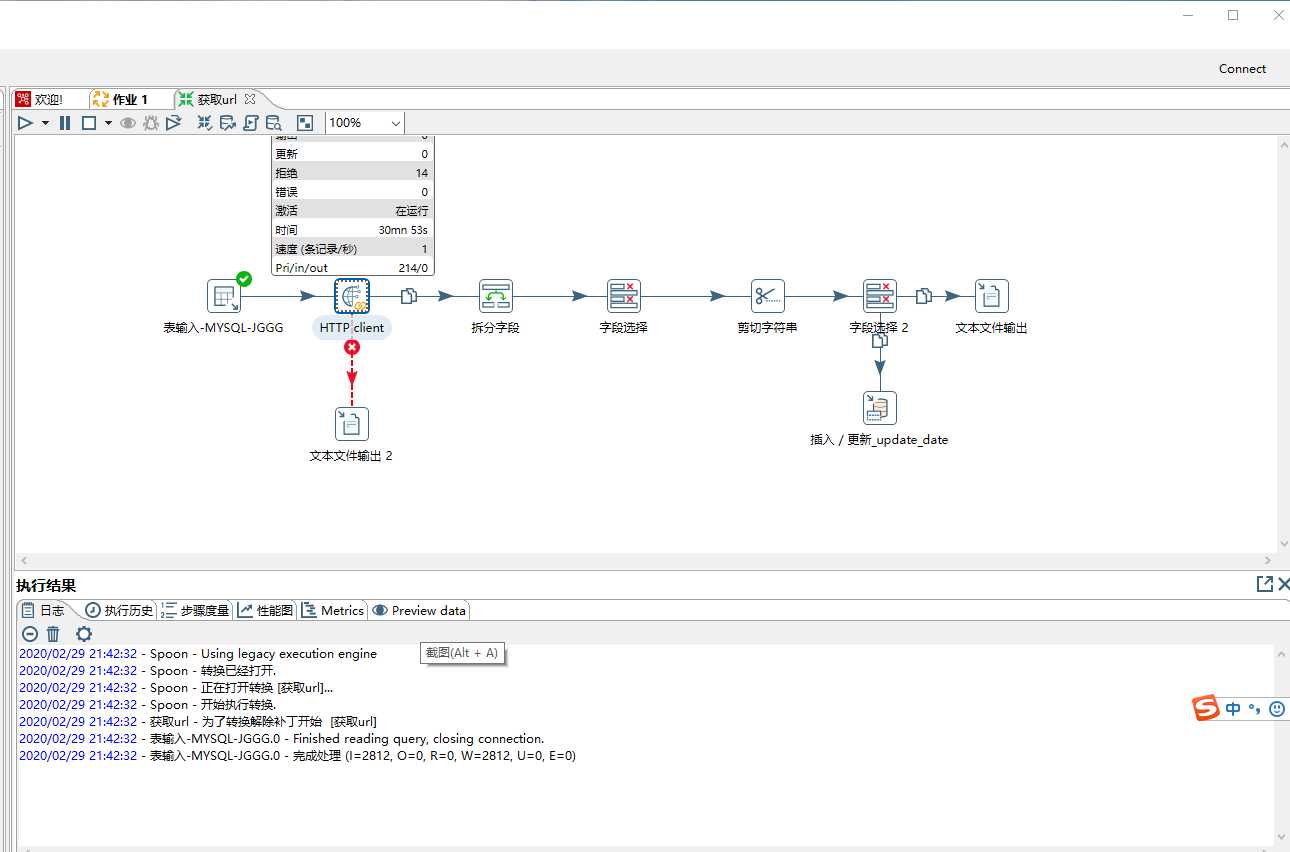
2800多条记录,跑了半个小时左右。对方的服务器确实比较慢。而且这种操作挺占内存的,每个页面的源代码都挺多,3000页左右就比较大了。
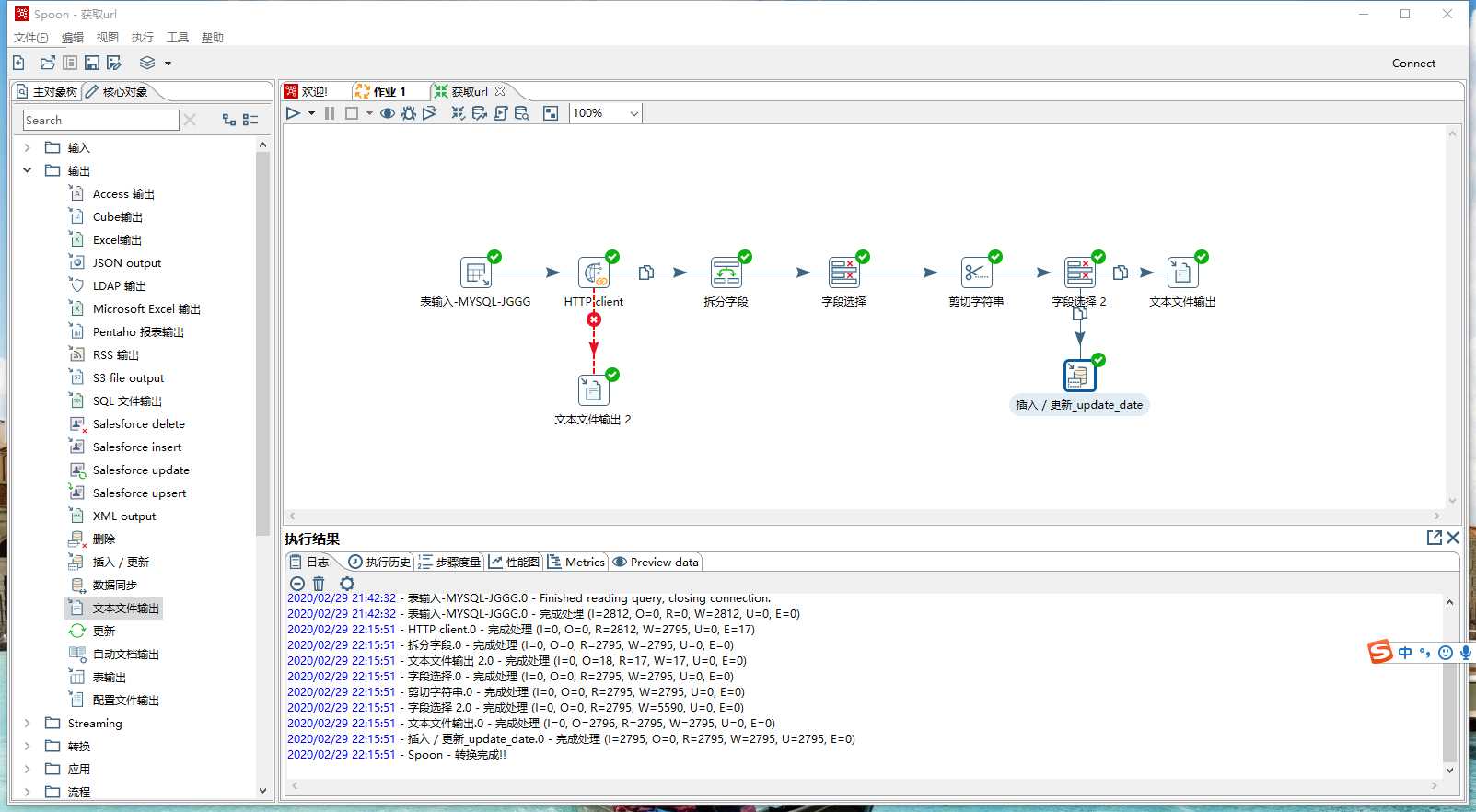
里面有17条记录是无法获取的url,可以人工去检查是什么问题。
关于xpath语言
还是想写一点记录一下。举个例子:

红色框这些是节点,绿色框的是属性(class="zw_c_c_title")。在填写kettle里面的循环路径时,只要填写节点就ok了。譬如我要读取这个绿色框的文本。循环路径就写:html/body/div/div/div,然后在字段路径里面,就根据你想获取的信息,在循环路径的哪一节去写,现在是在末端获取,所以字段路径就一点“.”,表示当前。而现在要获取的是属性,所以不用写一点了,就写@class就可以了。如果是要获取上一级,就是../@class。如此类推。
以上是关于用kettle做爬虫get请求爬取日期的主要内容,如果未能解决你的问题,请参考以下文章